MySQL COLUMNS分区
200 ? "200px" : this.width)!important;}
-->
介绍
COLUMN分区是5.5开始引入的分区功能,只有RANGE COLUMN和LIST COLUMN这两种分区;支持整形、日期、字符串;RANGE和LIST的分区方式非常的相似。
COLUMNS和RANGE和LIST分区的区别
1.针对日期字段的分区就不需要再使用函数进行转换了,例如针对date字段进行分区不需要再使用YEAR()表达式进行转换。
2.COLUMN分区支持多个字段作为分区键但是不支持表达式作为分区键。
COLUMNS支持的类型
整形支持:tinyint,smallint,mediumint,int,bigint;不支持decimal和float
时间类型支持:date,datetime
字符类型支持:char,varchar,binary,varbinary;不支持text,blob
一、RANGE COLUMNS分区
1.日期字段分区
CREATE TABLE members (
id INT,
joined DATE NOT NULL
)
PARTITION BY RANGE COLUMNS(joined) (
PARTITION a VALUES LESS THAN ('1960-01-01'),
PARTITION b VALUES LESS THAN ('1970-01-01'),
PARTITION c VALUES LESS THAN ('1980-01-01'),
PARTITION d VALUES LESS THAN ('1990-01-01'),
PARTITION e VALUES LESS THAN MAXVALUE
);
1.插入测试数据
insert into members(id,joined) values(,'1950-01-01'),(,'1960-01-01'),(,'1980-01-01'),(,'1990-01-01');
2.查询分区数据分布
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='members';

当前有5个分区只插入了4条记录,其中C分区是没有记录的,结果和实际一样。
3.分析执行计划
explain select id,joined from tb_partition.members where joined=YEAR(now());
explain select id,joined from tb_partition.members where joined='1963-01-01';
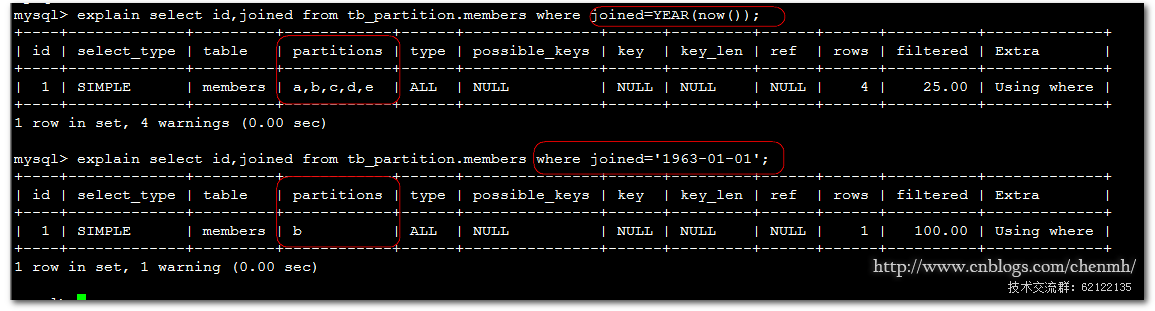
第一条查询使用了函数导致查询没有走具体的分区而是扫描的所有的分区,而第二条查询执行语句查找具体的分区。
2.多个字段组合分区
CREATE TABLE rcx (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a,b) (
PARTITION p0 VALUES LESS THAN (,),
PARTITION p1 VALUES LESS THAN (,),
PARTITION p2 VALUES LESS THAN (,),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
注意:多字段的分区键比较是基于数组的比较。它先用插入的数据的第一个字段值和分区的第一个值进行比较,如果插入的第一个值小于分区的第一个值那么就不需要比较第二个值就属于该分区;如果第一个值等于分区的第一个值,开始比较第二个值同样如果第二个值小于分区的第二个值那么就属于该分区。

例如:
insert into rcx(a,b)values(,),(,),(,);
第一组值:(1,20);1<5所以不需要再比较20了,该记录属于p0分区。
第二组值:(10,15),10>5,10=10且15<20,所以该记录属于P1分区
第三组值:(10,30),10=10但是30>20,所以它不属于p1,它满足10<15所以它属于p2
SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='rcx';

注意:RANGE COLUMN的多列分区第一列的分区值一定是顺序增长的,不能出现交叉值,第二列的值随便,例如以下分区就会报错
PARTITION BY RANGE COLUMNS(a,b) (
PARTITION p0 VALUES LESS THAN (,),
PARTITION p1 VALUES LESS THAN (10,20),
PARTITION p2 VALUES LESS THAN (8,30),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE)
);
由于分区P2的第一列比P1的第一列要小,所以报错,后面的分区第一列的值一定要比前面分区值要大,第二列没规定。
二、LIST COLUMNS分区
1.非整形字段分区
CREATE TABLE listvar (
id INT NOT NULL,
hired DATETIME NOT NULL
)
PARTITION BY LIST COLUMNS(hired)
(
PARTITION a VALUES IN ('1990-01-01 10:00:00','1991-01-01 10:00:00'),
PARTITION b VALUES IN ('1992-01-01 10:00:00'),
PARTITION c VALUES IN ('1993-01-01 10:00:00'),
PARTITION d VALUES IN ('1994-01-01 10:00:00')
); ALTER TABLE listvar ADD INDEX ix_hired(hired); INSERT INTO listvar() VALUES(1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00'),(1,'1992-01-01 10:00:00'),(1,'1993-01-01 10:00:00');
LIST COLUMNS分区对分整形字段进行分区就无需使用函数对字段处理成整形,所以对非整形字段进行分区建议选择COLUMNS分区。

EXPLAIN SELECT * FROM listvar WHERE hired='1990-01-01 10:00:00';

2.多字段分区
CREATE TABLE listvardou (
id INT NOT NULL,
hired DATETIME NOT NULL
)
PARTITION BY LIST COLUMNS(id,hired)
(
PARTITION a VALUES IN ( (1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00') ),
PARTITION b VALUES IN ( (2,'1992-01-01 10:00:00') ),
PARTITION c VALUES IN ( (3,'1993-01-01 10:00:00') ),
PARTITION d VALUES IN ( (4,'1994-01-01 10:00:00') )
); ALTER TABLE listvardou ADD INDEX ix_hired(hired); INSERT INTO listvardou() VALUES(1,'1990-01-01 10:00:00'),(1,'1991-01-01 10:00:00'),(2,'1992-01-01 10:00:00'),(3,'1993-01-01 10:00:00'); SELECT PARTITION_NAME,PARTITION_METHOD,PARTITION_EXPRESSION,PARTITION_DESCRIPTION,TABLE_ROWS,SUBPARTITION_NAME,SUBPARTITION_METHOD,SUBPARTITION_EXPRESSION
FROM information_schema.PARTITIONS WHERE TABLE_SCHEMA=SCHEMA() AND TABLE_NAME='listvardou';

EXPLAIN SELECT * FROM listvardou WHERE id=1 and hired='1990-01-01 10:00:00';

由于分区是组合字段,filtered只有50%,对于组合分区索引也最好是建组合索引,其实如果能通过id字段刷选出数据,单独建id字段的索引也是有效果的,但是组合索引的效果是最好的,其实和非分区键索引的概念差不多。
ALTER TABLE listvardou ADD INDEX ix_hired1(id,hired);

备注:文章中的示例摘自mysql官方参考手册
三、移除表的分区
ALTER TABLE tablename
REMOVE PARTITIONING ;
注意:使用remove移除分区是仅仅移除分区的定义,并不会删除数据和drop PARTITION不一样,后者会连同数据一起删除
分区系列文章:
RANGE分区:http://www.cnblogs.com/chenmh/p/5627912.html
LIST分区:http://www.cnblogs.com/chenmh/p/5643174.html
HASH分区:http://www.cnblogs.com/chenmh/p/5644496.html
KEY分区:http://www.cnblogs.com/chenmh/p/5647210.html
子分区:http://www.cnblogs.com/chenmh/p/5649447.html
指定各分区路径:http://www.cnblogs.com/chenmh/p/5644713.html
分区建索引:http://www.cnblogs.com/chenmh/p/5761995.html
分区介绍总结:http://www.cnblogs.com/chenmh/p/5623474.html
总结
RANGE COLUMNS和LIST COLUMNS分区其实是RANG和LIST分区的升级,所以可以直接使用COLUMN分区。注意COLUMNS分区不支持timestamp字段类型。
|
备注: 作者:pursuer.chen 博客:http://www.cnblogs.com/chenmh 本站点所有随笔都是原创,欢迎大家转载;但转载时必须注明文章来源,且在文章开头明显处给明链接。 《欢迎交流讨论》 |
MySQL COLUMNS分区的更多相关文章
- Mysql --分区表(5)Columns分区
COLUMNS分区 COLUMNS分区是RANGE和LIST分区的变种.COLUMNS分区支持多列作为分区键进行分区 RANGE COLUNMS分区和LIST COLUMNS都支持非INT型列作为分区 ...
- MySQL表分区技术
MySQL表分区技术 MySQL有4种分区类型: 1.RANGE 分区 - 连续区间的分区 - 基于属于一个给定连续区间的列值,把多行分配给分区: 2.LIST 分区 - 离散区间的分区 - 类似于按 ...
- MYSQL的分区字段,必须包含在主键字段内
MYSQL的分区字段,必须包含在主键字段内 MYSQL的分区字段,必须包含在主键字段内 在对表进行分区时,如果分区字段没有包含在主键字段内,如表A的主键为ID,分区字段为createtime ,按 ...
- mysql的分区技术(建立分区)
-- mysql建立表分区,使用range方法建立: create table t_range( id int(11), money int(11) unsigned not null, date d ...
- mysql的分区技术
一.概述 当 MySQL的总记录数超过了100万后,会出现性能的大幅度下降吗?答案是肯定的,但是,性 能下降>的比率不一而同,要看系统的架构.应用程序.还有>包括索引.服务器硬件等多种因素 ...
- MySQL partition分区I
http://blog.csdn.net/binger819623/article/details/5280267 一. 分区的概念二. 为什么使用分区?(优点)三. ...
- Mysql 表分区和性能
以下内容节选自<Mysql技术内幕InnoDB存储引擎> mysql表分区: 分区功能并不是所有存储引擎都支持的,如CSV.MERGE等就不支持.mysql数据库支持的分区类型为水平分区( ...
- mysql 表分区技术
表分区,是指根据一定规则,将数据库中的一张表分解成多个更小的,容易管理的部分.从逻辑上看,只有一张表,但是底层却是由多个物理分区组成. 表分区有什么好处: a.分区表的数据可以分布在不同的物理设备上, ...
- mysql表分区案例
0.整理表空间碎片optimize table tablename 1.表分区按年分区,季度子分区 alter table key_part partition by range(year(creat ...
随机推荐
- Xamarin 与VS2015RC(xamarin 3.11.450) 报空指针错误。
在Android开发中发现的一个“初步认为是调试器的bug”. 于早些时候发布在公司论坛上,传送门: http://www.newlifex.com/showtopic-1400.aspx 使用vs2 ...
- 产品经理 - 移动支付+Pos收单分析
产品经理 - 移动支付+Pos收单分析
- 更改pip安装源的镜像解决安装总是timeout的情况
由于国外的pip源总是由于各种原因不能被访问或者网速过慢,而造成的timeout错误 解决方法是修改pip的配置文件(如果没有配置文件在相应的地方新建,配置文件的路径和名字参考这里),设置安装包时候访 ...
- 用vue2 +vue-router2 + es6 +webpack 高仿饿了么app(干货满满)
#高仿饿了么app商家详情 (vue2 +vue-router2 + es6 +webpack ) ##demo [demo 地址](http://liangxiaojuan.github.io/ ...
- 指定eclipse启动使用的JVM
不同eclispe对运行时要求不一样,而一台电脑只能同时使用一个运行时,当多个要求不同版本jvm的eclipse需要在一台电脑工作时,需要手动指定eclipse启动使用的jvm. [eclipse-j ...
- 全局变量 HInstance 到底是在什么时候赋值的?
在学习 资源文件 和 钩子函数 时, 经常用到当前模块句柄(HInstance)这个全局变量. 今天特别想知道, 它到底是在什么时候给赋值的. 输入 HInstance; "Ctrl+鼠标& ...
- TFS 分支导致nuget项目依赖丢失
问题: 项目的代码 在tfs上分支后,签出项目.编译时发现无法编译,原有的nuget来的包的dll都丢失了(项目签入时,默认会忽略dll) 在网上找了下,发现一个简单的解决方法: 在"程序包 ...
- CSS3动画制作
CSS3动画制作 rotate 绕中心旋转 fadeInPendingFadeOutUp 先渐现,停留2s,再向上滑动并逐渐消失 fadeInUp2D 向上滑动并渐现, 因Animate.css的fa ...
- three.js贴图
使用图像作为材质.这时候,就需要导入图像作为纹理贴图,并添加到相应的材质中 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//E ...
- [ACM训练] ACM中巧用文件的输入输出来改写acm程序的输入输出 + ACM中八大输入输出格式
ACM中巧用文件的输入输出来改写acm程序的输入输出 经常有见大神们使用文件来代替ACM程序中的IO,尤其是当程序IO比较复杂时,可以使自己能够更专注于代码的测试,而不是怎样敲输入. C/C++代码中 ...