关于FutureTask的探索
之前关于Java线程的时候,都是通过实现Runnable接口或者是实现Callable接口,前者交给Thread去run,后者submit到一个ExecutorService去执行。
然后知道了还有个FutrureTask接口,而且好像很有用,在刚看完线程池的相关源码还有点记忆的情况下,就再顺便研究下这个FutureTask吧。
这篇文章会从源码角度探索下FutureTask,然后再研究下ExecutorService的submit方法。
一、FutureTask的类声明

可见它实现了RunnableFuture接口,而这个RunnableFuture接口呢,

这个RuunableFuture接口呢,继承了Runnable接口还有Future。
这意味着FutureTask类可以当作一个Runnable的线程任务类来用,我们可以把它作为参数交给Thread然后搞一条线程来run;
也可以通过这个FutureTask来追踪和控制这个线程的运行,比如可以cancel线程的任务;可以查看完成了没;当然还有最有用堵塞式获得运行的结果get()方法,而且不用像以前一样先把Callable submit到线程池获得一个Future,再通过Future来get。
但问题也来了,Callable的任务可以用Future来get可以理解,因为有个带有返回值的call方法嘛,但这个FutureTask并没有实现Callable接口啊,让我们在下面的分析中看看。
二、FutureTask的应用
两种方式吧:
2.1 FutureTask + Thread
把FutureTask当作Runnable来用
//step1:封装一个计算任务,实现Callable接口
class Task implements Callable<Boolean> { @Override
public Boolean call() throws Exception {
try {
for (int i = 0; i < 10; i++) {
Log.d(TAG, "task......." + Thread.currentThread().getName() + "...i = " + i);
//模拟耗时操作
Thread.sleep(100);
}
} catch (InterruptedException e) {
Log.e(TAG, " is interrupted when calculating, will stop...");
return false; // 注意这里如果不return的话,线程还会继续执行,所以任务超时后在这里处理结果然后返回
}
return true;
}
} //step2:创建计算任务,作为参数,传入FutureTask
Task task = new Task();
FutureTask futureTask = new FutureTask(task);
//step3:将FutureTask提交给Thread执行
Thread thread1 = new Thread(futureTask);
thread1.setName("task thread 1");
thread1.start(); //step4:获取执行结果,由于get()方法可能会阻塞当前调用线程,如果子任务执行时间不确定,最好在子线程中获取执行结果
try {
// boolean result = (boolean) futureTask.get();
boolean result = (boolean) futureTask.get(5, TimeUnit.SECONDS);
Log.d(TAG, "result:" + result);
} catch (InterruptedException e) {
Log.e(TAG, "守护线程阻塞被打断...");
e.printStackTrace();
} catch (ExecutionException e) {
Log.e(TAG, "执行任务时出错...");
e.printStackTrace();
} catch (TimeoutException e) {
Log.e(TAG, "执行超时...");
futureTask.cancel(true);
e.printStackTrace();
} catch (CancellationException e) {
//如果线程已经cancel了,再执行get操作会抛出这个异常
Log.e(TAG, "future已经cancel了...");
e.printStackTrace();
}
2.2 FutureTask + ExecutorService
把FutureTask当作Runnable丢给ExecutorService的execute()方法。
//step1 ......
//step2 ......
//step3:将FutureTask提交给线程池执行
ExecutorService executorService = Executors.newCachedThreadPool();
executorService.execute(futureTask);
//step4 ......
三、成员变量
3.1 private volatile int state
状态变量,这这代表着FutureTask是有状态的。
FutureTask的所有方法都是围绕这个状态进行的,需要注意,这个值用volatile(易变的)来标记,如果有多个子线程在执行FutureTask,那么它们看到的都会是同一个state,有如下几个值:
private volatile int state;
private static final int NEW = 0;
private static final int COMPLETING = 1;
private static final int NORMAL = 2;
private static final int EXCEPTIONAL = 3;
private static final int CANCELLED = 4;
private static final int INTERRUPTING = 5;
private static final int INTERRUPTED = 6;
NEW:表示这是一个新的任务,或者还没有执行完的任务,是初始状态。
COMPLETING:表示任务执行结束(正常执行结束,或者发生异常结束),但是还没有将结果保存到outcome中。是一个中间状态。
NORMAL:表示任务正常执行结束,并且已经把执行结果保存到outcome字段中。是一个最终状态。
EXCEPTIONAL:表示任务发生异常结束,异常信息已经保存到outcome中,这是一个最终状态。
CANCELLED:任务在新建之后,执行结束之前被取消了,但是不要求中断正在执行的线程,也就是调用了cancel(false),任务就是CANCELLED状态,这时任务状态变化是NEW -> CANCELLED。
INTERRUPTING:任务在新建之后,执行结束之前被取消了,并要求中断线程的执行,也就是调用了cancel(true),这时任务状态就是INTERRUPTING。这是一个中间状态。
INTERRUPTED:调用cancel(true)取消异步任务,会调用interrupt()中断线程的执行,然后状态会从INTERRUPTING变到INTERRUPTED。
状态变化有如下4种情况:
NEW -> COMPLETING -> NORMAL --------------------------------------- 正常执行结束的流程
NEW -> COMPLETING -> EXCEPTIONAL ---------------------执行过程中出现异常的流程
NEW -> CANCELLED -------------------------------------------被取消,即调用了cancel(false)
NEW -> INTERRUPTING -> INTERRUPTED -------------被中断,即调用了cancel(true)
3.2 private Callable<V> callable
Callable类型的变量,封装了计算任务,可获取计算结果。从上面的用法中可以看到,FutureTask的构造函数中,我们传入的就是实现了Callable的接口的计算任务。Object类型的变量outcome,用来保存计算任务的返回结果,或者执行过程中抛出的异常。Callable任务的线程,runner在FutureTask中的赋值变化很值得关注,后面源码会详细介绍这个。WaitNode是FutureTask的内部类,表示一个阻塞队列,如果任务还没有执行结束,那么调用get()获取结果的线程会阻塞,在这个阻塞队列中排队等待。四、构造方法
有两个:
/**
* Creates a {@code FutureTask} that will, upon running, execute the
* given {@code Callable}.
*
* @param callable the callable task
* @throws NullPointerException if the callable is null
*/
public FutureTask(Callable<V> callable) {
if (callable == null)
throw new NullPointerException();
this.callable = callable;
this.state = NEW; // ensure visibility of callable
} /**
* Creates a {@code FutureTask} that will, upon running, execute the
* given {@code Runnable}, and arrange that {@code get} will return the
* given result on successful completion.
*
* @param runnable the runnable task
* @param result the result to return on successful completion. If
* you don't need a particular result, consider using
* constructions of the form:
* {@code Future<?> f = new FutureTask<Void>(runnable, null)}
* @throws NullPointerException if the runnable is null
*/
public FutureTask(Runnable runnable, V result) {
this.callable = Executors.callable(runnable, result);
this.state = NEW; // ensure visibility of callable
}
可以看到构造器接受一个Callable或者接受一个Runnable和一个代表计算记过的result。
但不管传的是哪个,做的工作都是一样的——1. 将类变量callable,就封装了计算任务的那个类变量,给赋值;2. 将FutureTask的状态设置为NEW。
直接传进来一个Callable的话就直接赋值类变量就可以了,那如果是传进来一个Runnable和Result呢?
源码中可以看到,是用了工具类Executors中的一个方法——Executors.callable(runnable, result);
这个方法就是把一个Runnable加上一个Result封装成一个Callable对象,具体的做法大概就用一个RunnableAdapter的类去实现了Callable接口,然后这个RunnableAdapter类中封装了一个Runnable的task还有个T(泛型)类型的result,重写call方法的适合,就用这个result的T类型作为返回值,然后在call方法中调用task的run方法,最后返回result,看看源码吧:
public static <T> Callable<T> callable(Runnable task, T result) {
if (task == null)
throw new NullPointerException();
return new RunnableAdapter<T>(task, result);
}
/**
* A callable that runs given task and returns given result
*/
static final class RunnableAdapter<T> implements Callable<T> {
final Runnable task;
final T result;
RunnableAdapter(Runnable task, T result) {
this.task = task;
this.result = result;
}
public T call() {
task.run();
return result;
}
}
五、run方法
作为Runnable的实现类,那么肯定要重写run,也就是这个FutureTask作为一个任务,它要干的事。
无论是扔给一个Thread然后start,还是把这个FutureTask交给线程池,调用的都是这里的run方法。
5.1 看源码吧:
public void run() {
//1.判断状态是否是NEW,不是NEW,说明任务已经被其他线程执行,甚至执行结束,或者被取消了,直接返回
//2.调用CAS方法,判断RUNNER为null的话,就将当前线程保存到RUNNER中,设置RUNNER失败,就直接返回
if (state != NEW ||
!U.compareAndSwapObject(this, RUNNER, null, Thread.currentThread()))
return;
try {
Callable<V> c = callable;
if (c != null && state == NEW) {
V result;
boolean ran;
try {
//3.执行Callable任务,结果保存到result中
result = c.call();
ran = true;
} catch (Throwable ex) {
//3.1 如果执行任务过程中发生异常,将调用setException()设置异常
result = null;
ran = false;
setException(ex);
}
//3.2 任务正常执行结束调用set(result)保存结果
if (ran)
set(result);
}
} finally {
// runner must be non-null until state is settled to
// prevent concurrent calls to run()
//4. 任务执行结束,runner设置为null,表示当前没有线程在执行这个任务了
runner = null;
// state must be re-read after nulling runner to prevent
// leaked interrupts
//5. 读取状态,判断是否在执行的过程中,被中断了,如果被中断,处理中断
int s = state;
if (s >= INTERRUPTING)
handlePossibleCancellationInterrupt(s);
}
}
5.2 流程大概就是:
1. 看状态是不是NEW,不是的话直接返回;
2. 如果状态是NEW,那么用UNSAFE的CAS操作来将这个FutureTask中的类变量runner换成当成线程,意味着要有线程来执行这个FutureTask了。
3. 确定没问题后,就调用类变量callable中的call方法,然后将结果用局部变量result保存,如果没问题就调用set(result),如果有异常就setException(ex)。这两个方法其实就把运行结果赋值给类百年来outCome而已。
那就顺便贴一下setException还有set的相关源码还有注解:
protected void setException(Throwable t) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {//CAS换状态成中间状态COMPLETING
outcome = t;//将结果类变量赋值成抛出的异常,竟然不用volatile也不用CAS!
UNSAFE.putOrderedInt(this, stateOffset, EXCEPTIONAL); // final state//CAS换成抛异常情况的最终状态
finishCompletion();//任务完成函数,主要是唤醒为了获取这个FutureTask的运行结果的线程
}
}
protected void set(V v) {
if (UNSAFE.compareAndSwapInt(this, stateOffset, NEW, COMPLETING)) {//CAS换状态成中间状态COMPLETING
outcome = v;//将结果类变量赋值成运行的结果,竟然不用volatile也不用CAS!
UNSAFE.putOrderedInt(this, stateOffset, NORMAL); // final state CAS换成正常运行情况的最终状态
finishCompletion();//任务完成函数,主要是唤醒为了获取这个FutureTask的运行结果的线程
}
}
/**
* Removes and signals all waiting threads, invokes done(), and
* nulls out callable.
*/
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {//看似无限循环其实就循环一次,将这个等待队列的对头赋值给q
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {//用CAS操作把等待队列赋值为null,相当于清空等待队列吧
for (;;) {//这个for是遍历等待队列,唤醒他们,不要等了,要么可能现在已经运行完了,有结果了,要么现在抛异常了,挂了
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);//UNSafe唤醒操作
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
}
done();//空方法,大概是给用户重写的吧,可以在任务结束的时候做点什么吧
callable = null; // to reduce footprint减少可达性?帮助gc吗
}
大概思路就是set完结果后,就调用finishComplemention,在这个方法中会叫醒那些在等任务完成结果的线程,同时会处理这个WaitNode队列(waiters),就把可能有的引用都置null,帮助gc。
从这里我们也可以看出一个问题:
FutureTask的get(long timeout, TimeUnit unit)方法,是等待timeout时间后,获取子线程的执行结果,但是如果子任务执行结束了,但是超时时间还没有到,这个方法也会返回结果。
4. finally中,如果state是interrupting,就要handlePossibleCancellationInterrupt(s);
private void handlePossibleCancellationInterrupt(int s) {
// It is possible for our interrupter to stall before getting a
// chance to interrupt us. Let's spin-wait patiently.
if (s == INTERRUPTING)
while (state == INTERRUPTING)
Thread.yield(); // wait out pending interrupt
}
这个中断处理其实就是,如果被中断了,如果状态是INTERRUPTING,表示正在被中断,这时就让出线程的执行权(yield),给其他线程来执行。
六、get方法
一般情况下,执行任务的线程和获取结果的线程不会是同一个,当我们在主线程或者其他线程中,获取计算任务的结果时,就会调用get方法,如果这时计算任务还没有执行完成,调用get()的线程就会阻塞等待。get()实现如下:
public V get() throws InterruptedException, ExecutionException {
int s = state;
if (s <= COMPLETING)//说明还没有完成成功
s = awaitDone(false, 0L);//堵塞,或者如果运行任务的线程interrupt,做出回应
return report(s);//返回执行结果,如果抛了异常(就outcome是exception)就抛异常
}
大概可以分为三个步骤:
1. 读取任务的执行状态 state ,如果 state <= COMPLETING,说明线程还没有执行完(run()中可以看到,只有任务执行结束,或者发生异常的时候,state才会被设置成COMPLETING)。
2. 调用awaitDone(false, 0L),进入阻塞状态。看一下awaitDone(false, 0L)的实现:
/**
* Awaits completion or aborts on interrupt or timeout.
*
* @param timed true if use timed waits
* @param nanos time to wait, if timed
* @return state upon completion
*/
private int awaitDone(boolean timed, long nanos)
throws InterruptedException {
final long deadline = timed ? System.nanoTime() + nanos : 0L;
WaitNode q = null;
boolean queued = false;
for (;;) {
if (Thread.interrupted()) {//看看执行任务的线程是不是interrupt,如果是的话做出反应——1. 在等待队列中移除这个调用get方法的线程结点;2. 抛出异常
removeWaiter(q);
throw new InterruptedException();
} int s = state;
if (s > COMPLETING) {//任务完成了,可能正常完成也可能抛异常,总之就结束了,就把这个waitNode的thread置空,但其实不太懂,不用remove吗?
//还是说1. 等其他进行removeNode的操作的线程会帮忙清除掉??
//还是说2. 等任务完成后,在set方法或者是setException中的finishComplemention那里要唤醒等待线程,顺便赋值null帮助gc的操作那里一起 //处理。
if (q != null)
q.thread = null;
return s;
}
else if (s == COMPLETING) // cannot time out yet
Thread.yield();
else if (q == null)//第一次循环,创建结点
q = new WaitNode();
else if (!queued)//一般是第二次循环,入队,头插法
queued = UNSAFE.compareAndSwapObject(this, waitersOffset,
q.next = waiters, q);
else if (timed) {
nanos = deadline - System.nanoTime();
if (nanos <= 0L) {//超时的话,移除这个因为get方法堵塞的线程wait结点,并返回
removeWaiter(q);
return state;
}
LockSupport.parkNanos(this, nanos);//不超时的话就堵塞这个设定的时间咯
}
else
LockSupport.park(this);//普通get方法但还未运行成功,堵塞
}
}
awaitDone主要有几个步骤:
a. 判断Thread.interrupted(),如果调用get()的线程被中断了,就从等待的线程栈(其实就是一个WaitNode节点队列或者说是栈)中移除这个等待节点,然后抛出中断异常。
b. 读取state,如果s > COMPLETING,表示任务已经执行结束,或者发生异常结束了,此时,调用get()的线程就不会阻塞;如果s == COMPLETING,表示任务结束(正常/异常),但是结果还没有保存到outcome字段,当前线程让出执行权,给其他线程先执行。
c. 如果state是==COMPLETING,意味着基本完成但还没保存结果,就yield。(emmm应该是先放一下处理机,然后等等获得处理机继续处理??)
d. 判断q == null,如果等待节点q为null,就创建等待节点,这个节点后面会被插入阻塞队列。
e. 判断queued,这里是将c中创建节点q加入队列头。使用Unsafe的CAS方法,对waiters进行赋值,waiters也是一个WaitNode节点,相当于队列头,或者理解为队列的头指针。通过WaitNode可以遍历整个阻塞队列。
f. 之后,判断timed,设置了超时。超时的时间是从get()传入的值。设置超时时间之后,调用get()的线程最多阻塞nanos,就会从阻塞状态醒过来。如果超时的话,就移除这个因为get方法堵塞的线程wait结点,并返回state
g. 剩下的一个else,也就是没有设置超时时间但任务又还没执行出结果,就直接进入阻塞状态,等待被其他线程唤醒。
awaitDone()方法内部有一个无限循环,看似有很多判断,比较难理解,其实这个循环最多循环3次。
假设Thread A执行了get()获取计算任务执行结果,但是子任务还没有执行完,而且Thread A没有被中断,它会进行以下步骤。
step1:Thread A执行了awaitDone(),1,2两次判断都不成立,Thread A判断q=null,会创建一个WaitNode节点q,然后进入第二次循环。
step2:第二次循环,判断4不成立,此时将step1创建的节点q加入队列头。
step3:第三次循环,判断是否设置了超时时间,如果设置了超时时间,就阻塞特定时间,否则,一直阻塞,等待被其他线程唤醒。
3. 从awaitDone()返回,最后调用report(int s),这个方法就是把类变量outcome看情况返回而已。
简单看看report(int state)源码咯
/**
* Returns result or throws exception for completed task.
*
* @param s completed state value
*/
@SuppressWarnings("unchecked")
private V report(int s) throws ExecutionException {
Object x = outcome;
if (s == NORMAL)
return (V)x;
if (s >= CANCELLED)
throw new CancellationException();
throw new ExecutionException((Throwable)x);
}
通常调用cancel()的线程和执行子任务的线程不会是同一个。当FutureTask的cancel(boolean mayInterruptIfRunning)方法被调用时,如果子任务还没有执行,那么这个任务就不会执行了,如果子任务已经执行,且mayInterruptIfRunning=true,那么执行子任务的线程会被中断(注意:这里说的是线程被中断,不是任务被取消),下面看一下这个方法的实现:
7.1 cancel源码:
public boolean cancel(boolean mayInterruptIfRunning) {
//1.判断state是否为NEW,如果不是NEW,说明任务已经结束或者被取消了,该方法会执行返回false
//state=NEW时,判断mayInterruptIfRunning,如果mayInterruptIfRunning=true,说明要中断任务的执行,NEW->INTERRUPTING
//如果mayInterruptIfRunning=false,不需要中断,状态改为CANCELLED
if (!(state == NEW &&
U.compareAndSwapInt(this, STATE, NEW,
mayInterruptIfRunning ? INTERRUPTING : CANCELLED)))
return false;
try { // in case call to interrupt throws exception
if (mayInterruptIfRunning) {//只有是mayInterruptIfRunning才进来,所以如果这个值为false的话,就不会进来,也就是状态就:NEW——》CANCELLED
try {
//2.读取当前正在执行子任务的线程runner,调用t.interrupt(),中断线程执行
Thread t = runner;
if (t != null)
t.interrupt();
} finally { // final state
//3.修改状态为INTERRUPTED
U.putOrderedInt(this, STATE, INTERRUPTED);
}
}
} finally {
finishCompletion();
}
return true;
}
7.2 流程分析:
cancel()分析:
1. 判断state,保证state = NEW才能继续cancel()的后续操作。如果不是NEW,直接return false; state=NEW且mayInterruptIfRunning=true,说明要中断任务的执行,此时,NEW->INTERRUPTING。然后读取当前执行任务的线程runner,调用t.interrupt(),中断线程执行,NEW->INTERRUPTING->INTERRUPTED,最后调用finishCompletion()。
2. 如果mayInterruptIfRunning为false,那么cancel()方法,只是修改了状态,NEW->CANCELLED,然后直接调用finishCompletion()。
所以cancel(true)方法,只是调用t.interrupt(),此时,如果t因为sleep(),wait()等方法进入阻塞状态,那么阻塞的地方会抛出InterruptedException;如果线程正常运行,需要结合Thread的interrupted()方法进行判断,才能结束,否则,cancel(true)不能结束正在执行的任务。
这也就可以解释前面我遇到的问题,有的情况下,使用 futuretask.cancel(true)方法并不能真正的结束子任务执行。
然后最后也是调用这个finishComplish方法,这个方法其实在上面介绍set和setException,竟然用了那么多次,下面再重点提一下吧(虽然不难hh)
八、子线程返回的组后一步——finishCompletion()的介绍
8.1 这个方法用到了很多次,就我们上面的分析,就在好几个地方用到了:
1. set方法中;
2. setException方法中;
3. cancel方法中。
他们都有一个特点,就是FutureTask准备进入最终状态final state的时候调用这个方法。
8.2 看源码吧:
/**
* Removes and signals all waiting threads, invokes done(), and
* nulls out callable.
*/
private void finishCompletion() {
// assert state > COMPLETING;
for (WaitNode q; (q = waiters) != null;) {//看似无限循环其实就循环一次,将这个等待队列的对头赋值给q
if (UNSAFE.compareAndSwapObject(this, waitersOffset, q, null)) {//用CAS操作把等待队列赋值为null,相当于清空等待队列吧
for (;;) {//这个for是遍历等待队列,唤醒他们,不要等了,要么可能现在已经运行完了,有结果了,要么现在抛异常了,挂了
Thread t = q.thread;
if (t != null) {
q.thread = null;
LockSupport.unpark(t);//UNSafe唤醒操作
}
WaitNode next = q.next;
if (next == null)
break;
q.next = null; // unlink to help gc
q = next;
}
break;
}
} done();//空方法,大概是给用户重写的吧,可以在任务结束的时候做点什么吧 callable = null; // to reduce footprint减少可达性?帮助gc吗
}
8.3 流程分析
这个代码其实就做了三件事:
1. 用UNSAFE的解除阻塞的方法,将还在等这个FutureTask的get结果的线程都唤醒;
2. 将waiters指向null,将链表中的next都指向null,同时也将每个结点的thread类变量指向null,这一步是为了帮助GC这个waiters等待队列。
3. 设置类变量callable为null,callable是FutureTask封装的任务,任务执行完,将callable置为null帮助gc吧。
哦还有个done方法,这个方法什么都没有做,不过子类可以实现这个方法,做一些额外的操作。
8.4 tips:
所以,
FutureTask的get(long timeout, TimeUnit unit)方法,表示阻塞timeout时间后,获取子线程的执行结果,但是如果子任务执行结束了,但是超时时间还没有到,这个方法也会返回结果。
因为任务执行完之后,会在set或者setException方法中调用这个finishCompletion方法,这个方法会遍历阻塞队列,唤醒阻塞的线程。
LockSupport.unpark(t)执行之后,阻塞的线程会从LockSupport.park(this)/LockSupport.parkNanos(this, parkNanos)醒来,然后会继续进入awaitDone(boolean timed, long nanos)的for无限循环,此时,state >= COMPLETING,然后从awaitDone()返回。此时,get()/get(long timeout, TimeUnit unit)会继续执行,return report(s)。
九、其他方法
FutureTask的还有两个方法isCancelled()和isDone(),其实就是判断state,没有过多的步骤。
public boolean isCancelled() {
return state >= CANCELLED;
}
public boolean isDone() {
return state != NEW;
}
十、ExecutorService的submit方法
我一开始接触线程池,用的就是这个submit的方法。创建一个类实现Callable接口,然后把它submit给线程池,获得一个Future实例。然后通过这个Future实例,我们可以用get()来获取你的callable任务运行的情况。那么它是怎么实现的呢?
直接看源码吧,我们发现在ThreadPoolExecutor中并没有找到submit方法的实现,于是找AbstractExecutorService类——它是ExecutorService接口的抽象实现类。
果然在这里实现了submit方法。
10.1 AbstractExecutorService中的submit方法源码:
/**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public Future<?> submit(Runnable task) {
if (task == null) throw new NullPointerException();
RunnableFuture<Void> ftask = newTaskFor(task, null);
execute(ftask);
return ftask;
} /**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Runnable task, T result) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task, result);
execute(ftask);
return ftask;
} /**
* @throws RejectedExecutionException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public <T> Future<T> submit(Callable<T> task) {
if (task == null) throw new NullPointerException();
RunnableFuture<T> ftask = newTaskFor(task);
execute(ftask);
return ftask;
}
可见在这个类中一共重载了三个submit方法,分别以Runnable为参数;以一个Runnable和一个任务执行结果为参数;一个Callable为参数。
我们发现,不管是哪个参数,做的都是把传进来的参数转换成一个RunnableFuture类型的实例。
RunnableFuture??这个接口怎么有点熟悉,没错,就是我们FutureTask实现的接口。
我们看到,这三个submit中都是通过newTaskFor方法来生成RunnableFuture实例的,那就看看这个newTaskFor方法吧:
10.2 newTaskFor方法:
/**
* Returns a {@code RunnableFuture} for the given runnable and default
* value.
*
* @param runnable the runnable task being wrapped
* @param value the default value for the returned future
* @param <T> the type of the given value
* @return a {@code RunnableFuture} which, when run, will run the
* underlying runnable and which, as a {@code Future}, will yield
* the given value as its result and provide for cancellation of
* the underlying task
* @since 1.6
*/
protected <T> RunnableFuture<T> newTaskFor(Runnable runnable, T value) {
return new FutureTask<T>(runnable, value);
} /**
* Returns a {@code RunnableFuture} for the given callable task.
*
* @param callable the callable task being wrapped
* @param <T> the type of the callable's result
* @return a {@code RunnableFuture} which, when run, will call the
* underlying callable and which, as a {@code Future}, will yield
* the callable's result as its result and provide for
* cancellation of the underlying task
* @since 1.6
*/
protected <T> RunnableFuture<T> newTaskFor(Callable<T> callable) {
return new FutureTask<T>(callable);
}
好的现在看到了,原来最后是转换成FutureTask的一个实例!
10.3 好的总结一下线程池的submit流程吧:
1. 传参数给submit,Runnable或者Runnable + result或Callable
2. 如果你传的只有Runnable,那么submit会调用 RunnableFuture<Void> ftask = newTaskFor(task, null),因为你没有定义返回的结果类型,所以直接泛型是void;如果你传的是Runnable + result,会调用newTaskFor(Runnable,result);如果你传的是Callable会调用newTaskFor(Callable)。
3. newTaskFor(Runnable, T result)是通过调用FutureTask<T>(runnable, value);这个构造器做的就是把这个Runnable和result(可能为空)转换成Callable,作为这个FutureTask要执行的任务,用的是工具类Executors.callable(Runnable, result)方法;然后newTaskFor(Callable)就很显然了,就直接把这个Callable作为要执行的任务赋值给这个FutureTask实例。
用一个图来理解过程:
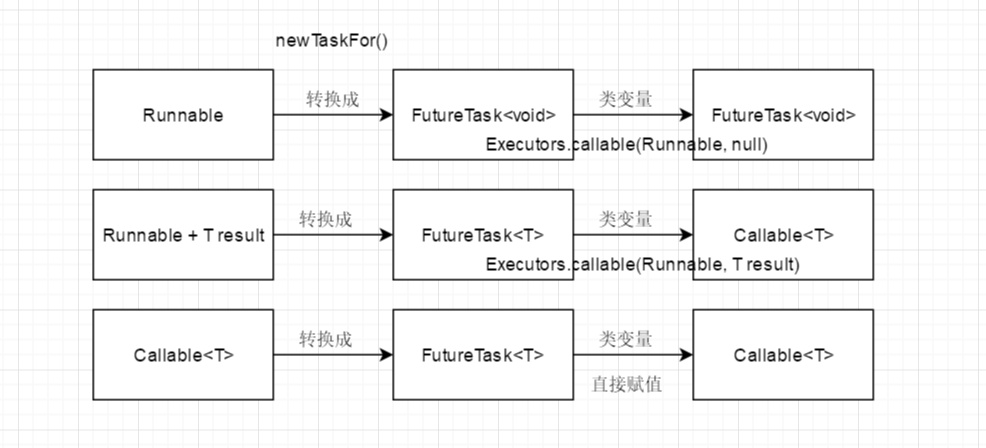
补充下……第一行第三列的那个框搞错了,应该是Callable,懒得改了哈哈哈
4. 调用execute(ftask)来执行刚刚生成的FutureTask封装的任务。之前我们对这个线程池的execute源码的分析我们知道,这个方法接受的是Runnable类型,进来的相当于是Runnable的任务,要么直接新建一个工作线程Worker执行这个Runnable任务;要么在WorkQueue中排队等。而execute线程池在执行execute,主要是通过addWorker来进行相关工作线程的添加还有任务的执行,Worker是一个Runnable和AQS的实现,它是工作线程的抽象代表,它的run方法是不断地去Workqueue里面拿task(其实是我们的FutureTask)来run,然后FutureTask跑起来之后,就进入我们上面讲的FutureTask的逻辑流程了,也可以通过cancel啊get啊等方法来控制这个FutureTask的run过程了。
呼终于有点连起来了………………
参考文章:
https://www.jianshu.com/p/55221d045f39——《可取消的异步任务——FutureTask用法及解析》
关于FutureTask的探索的更多相关文章
- 【并发编程】【JDK源码】J.U.C--组件FutureTask、ForkJoin、BlockingQueue
原文:慕课网实战·高并发探索(十三):并发容器J.U.C -- 组件FutureTask.ForkJoin.BlockingQueue FutureTask FutureTask是J.U.C中的类,是 ...
- 【探索】机器指令翻译成 JavaScript
前言 前些时候研究脚本混淆时,打算先学一些「程序流程」相关的概念.为了不因太枯燥而放弃,决定想一个有趣的案例,可以边探索边学. 于是想了一个话题:尝试将机器指令 1:1 翻译 成 JavaScript ...
- 【探索】利用 canvas 实现数据压缩
前言 HTTP 支持 GZip 压缩,可节省不少传输资源.但遗憾的是,只有下载才有,上传并不支持.如果上传也能压缩,那就完美了.特别适合大量文本提交的场合,比如博客园,就是很好的例子. 虽然标准不支持 ...
- 探索C#之6.0语法糖剖析
阅读目录: 自动属性默认初始化 自动只读属性默认初始化 表达式为主体的函数 表达式为主体的属性(赋值) 静态类导入 Null条件运算符 字符串格式化 索引初始化 异常过滤器when catch和fin ...
- Mysql事务探索及其在Django中的实践(二)
继上一篇<Mysql事务探索及其在Django中的实践(一)>交代完问题的背景和Mysql事务基础后,这一篇主要想介绍一下事务在Django中的使用以及实际应用给我们带来的效率提升. 首先 ...
- Linux学习之探索文件系统
Linux,一起学习进步- ls With it, we can see directory contents and determine a variety of important file ...
- 马里奥AI实现方式探索 ——神经网络+增强学习
[TOC] 马里奥AI实现方式探索 --神经网络+增强学习 儿时我们都曾有过一个经典游戏的体验,就是马里奥(顶蘑菇^v^),这次里约奥运会闭幕式,日本作为2020年东京奥运会的东道主,安倍最后也已经典 ...
- C++随笔:.NET CoreCLR之GC探索(4)
今天继续来 带大家讲解CoreCLR之GC,首先我们继续看这个GCSample,这篇文章是上一篇文章的继续,如果有不清楚的,还请翻到我写的上一篇随笔.下面我们继续: // Initialize fre ...
- C++随笔:.NET CoreCLR之GC探索(2)
首先谢谢 @dudu 和 @张善友 这2位大神能订阅我,本来在写这个系列以前,我一直对写一些核心而且底层的知识持怀疑态度,我为什么持怀疑态度呢?因为一般写高层语言的人99%都不会碰底层,其实说句实话, ...
随机推荐
- highcharts 图例全选按钮方法
$('#uncheckAll').click(function(){ var chart = $('#container').highcharts(); var series = chart.seri ...
- 集训Day1
雅礼集训2017Day1的题 感觉上不可做实际上还挺简单的吧 T1 区间加 区间除法向下取整 查询区间和 区间最小值 大力上线段树,把除法标记推到底,加法标记就是按照线段树的来 先拿30 然后60的数 ...
- docker镜像管理基础
[root@node01 ~]# docker pull quay.io/coreos/flannel:v0.10.0-amd64 v0.10.0-amd64: Pulling from coreos ...
- MySQL上周新增激活用户在上周下单情况_20161107周一
上周新增激活用户在上周下单情况 1.上周激活用户明细 #上周激活用户明细 SELECT a.城市,a.用户ID,a.用户名称,b.用户地址,b.联系电话,a.订单日期,c.年周,c.上周一,a.订单I ...
- 【Lintcode】028.Search a 2D Matrix
题目: Write an efficient algorithm that searches for a value in an m x n matrix. This matrix has the f ...
- HL7 Event Type
Table 0003 - Event type Value Description A01 ADT/ACK - Admit / visit notification A02 ADT/ACK - Tra ...
- Ubuntu vim使用
vim安装:apt-get install vim-gtk vim使用:默认启动插入模式,或者按‘I’进入插入模式,退出插入模式按‘esc’,用冒号‘:wq’进行保存退出: 其复制和粘贴是靠鼠标右键中 ...
- 动态库*.so制作
转自:http://www.2cto.com/os/201308/238936.html 在linux下制作动态库*.so. 1.linux下动态库的制作 //so_test.h #include ...
- matlab 函数 bwarea
Matlab函数bwarea简介 函数功能:计算二值图像中对象的总面积. 调用格式: total = bwarea(BW) 估算二值图像BW中对象的总面积. 返回的total是一个标量, 它的值大致地 ...
- 使用远程线程来注入DLL
使用远程线程来注入DLL DLL注入技术要求我们目标进程中的一个线程调用LoadLibrary来载入我们想要的DLL (1)用OpenProcess函数打开目标进程(2)用VirtualAllocEx ...