Hadoop架构的初略总结(2)
Hadoop架构的初略总结(2)
回顾一下前文,我们总结了以下几个方面。我们为什么需要Hadoop;Hadoop2.0生态系统的构成;Hadoop1.0中HDFS和MapReduce的结构模型。
我们大致了解了1.0,现在我们来说说2.0。
首先,我们需要理清以下几个问题:
1.Hadoop1.0自身有哪些缺陷呢?
解:从两个大的方面来说,HDFS和MapReduce。
HDFS:
1) NameNode中的单点故障问题。
针对Hadoop1.0中HDFS单点故障进行以下解释:
HDFS仿照google GFS实现的分布式存储系统,由NameNode和DataNode两种服务组成,其中NameNode是存储了元数据信息(fsimage)和操作日志(edits),由于它是唯一的,其可用性直接决定了整个存储系统的可用性。因为客户端对HDFS的读、写操作之前都要访问name node服务器,客户端只有从name node获取元数据之后才能继续进行读、写。一旦NameNode出现故障,将影响整个存储系统的使用。
这里需要提到一点,在Hadoop架构的初略总结(2)中提到的SecondaryNameNode,其作用合并NameNode节点中的fsimage和edits。首先,SecondaryNameNode从NameNode中通过网络拷贝一份fsimage(元数据信息)与edits(操作日志)到自己进程的那一块,然后将fsimage与edits进行合并,生成新的fsimage,并将新生成的fsimage推送到NameNode节点中一份,并将NameNode中edits的内容进行清空。
2) 不能进行大量的小文件存取(占用namenode大量内存,浪费磁盘空间)扩展性差。也就是说,Hadoop1.0单NameNode制约HDFS扩展性,因为NameNode含有我们用户存储文件的全部的元数据信息,当我们的NameNode无法在内存中加载全部元数据信息的时候,集群的寿命就到头了,NameNode内存大小限制了从节点的个数,大体为4000个节点个数。
3) 其它缺陷:HDFS中的权限设计不够彻底,即HDFS的数据隔离性不是很好;数据丢失问题,访问效率问题。
改进:略。(了解了一下,看不懂,暂且略过吧,现阶段这不是重点)
MapReduce:
1) 扩展性:集群最大节点数4000(也就是4000节点主机上线);最大并发任务数40000。
2) 可用性,可靠性:JobTracker同时管理作业的调度和计算,在Hadoop1.0中,假设有100个作业,根据Hadoop访问和更新的特性,批处理,一次写入多次读写,JobTracker会同时管理这100个作业,负担太重。其次,存在单点故障,一旦故障,所有执行的任务全部失败。
3) 批处理模式,时效低:仅仅使用MapReduce一种计算方式。
4) 其他缺陷:低效的资源管理。在Hadoop1.0中不支持多框架。
2.说完Hadoop1.0的缺陷,我们来说说Hadoop2.0,Hadoop2.0生态系统的构成在前篇博客中有所提到。这里,我们从以下几个方面进行了解。
解:
在Hadoop2.0中,针对HDFS1.0中NameNode的内存容量不足以及NameNode的单点故障问题,在2.0中分别作了以下的改进:
- 在1.0中,既然一个NameNode会导致内存容量不足,我们引入两个NameNode,组成HDFS联邦,这样NameNode存储的元数据信息就可以翻倍了,所谓HDFS联邦就是有多个HDFS集群同时工作,数据节点DataNode存储的数据是服务于两个HDFS文件系统的,体系结构如下图所示:
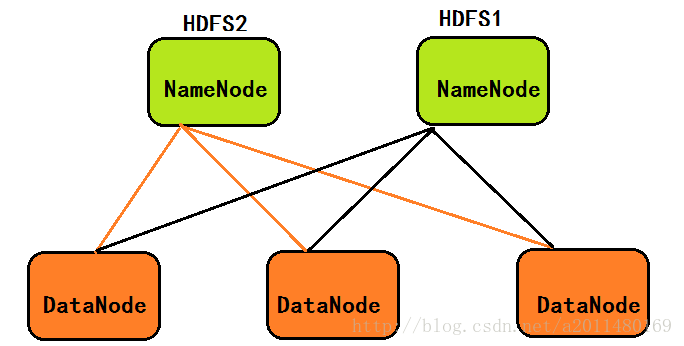
- 在2.0中,针对1.0中NameNode的单点故障问题,在2.0中引入了新的HA机制:即如果Active(活跃的)的NameNode节点挂掉,处于Standby(备份的)的NameNode节点将替换掉它继续工作,下面的图示方便大家的理解:

在这里大家一定要注意:2.0中处于HDFS联邦的也是两个NameNode节点,处于HA的也是两个NameNode节点,但是联邦中的两个NameNode节点由于使用的是不同的命名空间(Name Space),因此两个NameNode节点存储的元数据信息并不相同,但是处于HA中的两个NameNode节点由于使用的相同的命名空间,因此两个NameNode节点存储的元数据信息是相同的。
了解了Hadoop2.0中针对Hadoop1.0中HDFS缺陷而改进的联邦和HA,下面了解下MRv1和MRv2。
MRv1和MRv2在前文博客 Hadoop第三课中有所讲解,这里就不重复了。
接下来,了解下在博客Hadoop第三课中提到的HDFS Federation 。
作为这方面的小白,上网搜索了下,有位前辈写的浅显易懂,从很大层次上解决了我的问题。
http://blog.csdn.net/androidlushangderen/article/details/52135506
同样,我们要了解ResourceManager、ApplicationMaster以及Map Task和Reduce Task,这些就不得不说Hadoop2.0中的YARN了。
参考文献:
http://blog.csdn.net/a2011480169/article/details/53647012
https://www.cnblogs.com/sxt-zkys/archive/2017/07/24/7229857.html
Hadoop架构的初略总结(2)的更多相关文章
- Hadoop架构的初略总结(1)
Hadoop架构的初略总结(1) Hadoop是一个开源的分布式系统基础架构,此架构可以帮助用户可以在不了解分布式底层细节的情况下开发分布式程序. 首先我们要理清楚几个问题. 1.我们为什么需要Had ...
- FireMonkey 结构性初略分析
Delphi 下的FireMonkey,很好地实现了 DirectUI与跨平台.学习了解他,对DirectUI编程及项目的跨平台实现有一定帮助.虽然作为开发者个体,并不需要了解太多这些东西,只要求拿来 ...
- Hadoop 架构与原理
1.1. Hadoop架构 Hadoop1.0版本两个核心:HDFS+MapReduce Hadoop2.0版本,引入了Yarn.核心:HDFS+Yarn+Mapreduce Yarn是资源调度框 ...
- Hadoop架构及集群
Hadoop是一个由Apache基金会所开发的分布式基础架构,Hadoop的框架最核心的设计就是:HDFS和MapReduce.HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了 ...
- Hadoop架构: 流水线(PipeLine)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 流水线(PipeLine),简单地理解就是客户端向DataNode传输数据(Packet)和接收Dat ...
- Hadoop架构: HDFS中数据块的状态及其切换过程,GS与BGS
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 首先,我们要提出HDFS存储特点: 1.高容错 2.一个文件被切成块(新版本默认128MB一个块)在不 ...
- Hadoop架构: 关于Recovery (Lease Recovery , Block Recovery, PipeLine Recovery)
该系列总览: Hadoop3.1.1架构体系——设计原理阐述与Client源码图文详解 : 总览 在HDFS中,有三种Recovery 1.Lease Recovery 2.Block Recover ...
- hadoop知识点总结(一)hadoop架构以及mapreduce工作机制
1,为什么需要hadoop 数据分析者面临的问题 数据日趋庞大,读写都出现性能瓶颈: 用户的应用和分析结果,对实时性和响应时间要求越来越高: 使用的模型越来越复杂,计算量指数级上升. 期待的解决方案 ...
- Hadoop架构模型
1.hadoop 1.x架构模型:分布式文件存储系统:HDFSNameNode(主节点:管理元数据) secondaryNameNode(作用是合并元数据信息,辅助NameNode管理元数据信息)Da ...
随机推荐
- 【BZOJ3668】[NOI2014] 起床困难综合症(位运算思想)
点此看题面 大致题意: 给定一些位运算操作,让你在\(0\sim m\)范围内选一个初始值,使其在经过这些运算后得到的结果最大. 前置技能:关于位运算 作为一道位运算的题,如果你不知道什么是位运算,那 ...
- 【BZOJ1076】[SCOI2008] 奖励关(状压DP)
点此看题面 大致题意:总共有\(n\)个宝物和\(k\)个回合,每个回合系统将随机抛出一个宝物(抛出每个宝物的概率皆为\(1/n\)),吃掉一个宝物可以获得一定的积分(积分可能为负),而吃掉某个宝物有 ...
- URL Schemes 不能识别和不能跳转的原因
在app跳转的过程中 需要设置url schemes后,但是设置完后,却不能识别, (测试方式:URL scheme + ://)在浏览器中打开,如果能打开app,就是能跳转 今天遇到了一个坑爹的问题 ...
- 2017.12.2 用java做一个日历
1.先判断输入的日期是否为闰年 2.在判断输入的月份是否为2月 3.在获取输入的年份和月份的1月1日 的列数 4.在输出 import java.util.*; public class demo{ ...
- 2018.2.2 java中的Date如何获取 年月日时分秒
package com.util; import java.text.DateFormat; import java.util.Calendar; import java.util.Date; pub ...
- 使用webpack从零开始搭建react项目
webpack中文文档 webpack的安装 yarn add webpack@3.10.1 --dev 需要处理的文件类型 webpack常用模块 webpack-dev-server yarn a ...
- java Socket 客户端服务端对接正确写法(BIO)
之前在工作中写过一些Socket客户端与服务端的代码,但是当时没有时间仔细研究,只能不报错先过的态度,对其细节了解不深,写的代码有各种问题也浑然不知,只是业务量级以及对接方对接代码没有出现出格的情况所 ...
- python 多进程简单调用
python 多进程简 #!/usr/bin/env python #-*- coding:utf-8 -*- # author:leo # datetime:2019/5/28 10:03 # so ...
- sigqueue与kill详解及实例
/*********************************************************************************************** 相关函 ...
- 记录一些 FileZillaClient 的基本连接操作
本地主机:Window 10 FileZilla版本:3.39.0 64位 远程主机:CentOS 6.4 需安装FTP服务 小提示:查看CentOS版本命令 # cat /etc/issue Fil ...