Java:逐行读、写文件、文件目录过滤的用法
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List; public class HelloWord {
public static void main(String[] args) throws IOException {
String filePath = "my File.txt";
File file = new File(filePath);
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(file),"utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader); List<String> lineItems=new ArrayList<String>();
String line = null;
while ((line = bufferedReader.readLine()) != null) {
String[] items = line.split(","); String item= items[1];
if(item.indexOf("花园")!=-1){
lineItems.add(line);
}
} bufferedReader.close();
inputStreamReader.close(); for(String my : lineItems){
System.out.println(my);
}
}
}
- 写文件用法:
List<String> lines = new ArrayList<>();
String wfilePath="e:\\1.txt";
File wfile = new File(wfilePath);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream(wfile), "utf-8");
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
for (String eLine : lines) {
bufferedWriter.write(eLine);
bufferedWriter.newLine();
} bufferedWriter.close();
outputStreamWriter.close(); System.out.println("Complete...");
- 文件目录过滤:
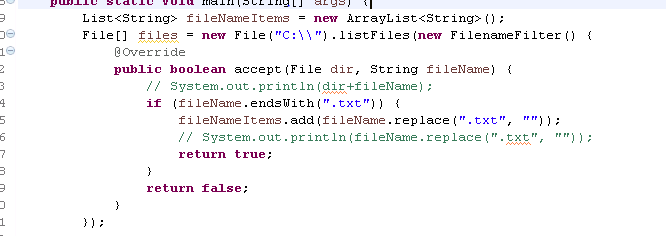
实例:
package com.dx.hibernate5.test; import java.io.BufferedReader;
import java.io.BufferedWriter;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.io.UnsupportedEncodingException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map; public class HelloWord {
public static void main(String[] args) throws IOException {
String filePath = "E:\\丽水";
String wfilePath = "E:\\丽水_New";
parserCountyVsCode(filePath); parseCityCounty(filePath, wfilePath); System.out.println("Complete...");
} private static void parserCountyVsCode(String filePath)
throws UnsupportedEncodingException, FileNotFoundException, IOException {
File file = new File(filePath);
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(file), "utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
// 缙云县:5782
// 云和县:5784
// 开发区:578B
// 龙泉市:5786
// 景宁县:5789
// 青田县:5783
// 景宁畲族自治县:5789
// 松阳县:5788
// 庆元县:5785
// 莲都区:5781
// 遂昌县:5787
List<String> countyList = new ArrayList<>();
countyList.add("5782");
countyList.add("5784");
countyList.add("578B");
countyList.add("5786");
countyList.add("5789");
countyList.add("5783");
countyList.add("5788");
countyList.add("5785");
countyList.add("5781");
countyList.add("5787"); Map<String, String> lineItems = new HashMap<String, String>();
String line = null;
while ((line = bufferedReader.readLine()) != null) {
String[] items = line.split(","); String address = items[3];
String county = items[2]; if (address.indexOf("莲都区") != -1) {
lineItems.put("莲都区", county);
} else if (address.indexOf("开发区") != -1) {
lineItems.put("开发区", county);
} else if (address.indexOf("青田县") != -1) {
lineItems.put("青田县", county);
} else if (address.indexOf("缙云县") != -1) {
lineItems.put("缙云县", county);
} else if (address.indexOf("遂昌县") != -1) {
lineItems.put("遂昌县", county);
} else if (address.indexOf("松阳县") != -1) {
lineItems.put("松阳县", county);
} else if (address.indexOf("云和县") != -1) {
lineItems.put("云和县", county);
} else if (address.indexOf("庆元县") != -1) {
lineItems.put("庆元县", county);
} else if (address.indexOf("景宁县") != -1 || address.indexOf("景宁畲族自治县") != -1) {
lineItems.put("景宁县", county);
} else if (address.indexOf("龙泉市") != -1) {
lineItems.put("龙泉市", county);
} else {
Boolean hasContains = false;
for (String coun : countyList) {
if (coun.equals(county)) {
hasContains = true;
}
}
if (!hasContains) {
System.out.println(line);
}
}
} bufferedReader.close();
inputStreamReader.close(); for (Map.Entry<String, String> kvEntry : lineItems.entrySet()) {
System.out.println(kvEntry.getKey() + ":" + kvEntry.getValue());
}
} private static void parseCityCounty(String filePath, String wfilePath)
throws UnsupportedEncodingException, FileNotFoundException, IOException {
Map<String, String> idVsCountry = new HashMap<>();
idVsCountry.put("5782", "缙云县");
idVsCountry.put("5784", "云和县");
idVsCountry.put("578B", "开发区");
idVsCountry.put("5786", "龙泉市");
idVsCountry.put("5789", "景宁县");
idVsCountry.put("5783", "青田县");
idVsCountry.put("5788", "松阳县");
idVsCountry.put("5785", "庆元县");
idVsCountry.put("5781", "莲都区");
idVsCountry.put("5787", "遂昌县"); List<String> lines = new ArrayList<>();
lines.add("abc0");
lines.add("abc1");
lines.add("abc2");
File file = new File(filePath);
InputStreamReader inputStreamReader = new InputStreamReader(new FileInputStream(file), "utf-8");
BufferedReader bufferedReader = new BufferedReader(inputStreamReader);
String line = null;
while ((line = bufferedReader.readLine()) != null) {
String[] items = line.split(","); String address = items[3];
String county = items[2];
String newLine = items[0] + ",丽水市," + idVsCountry.get(county) + "," + address;
// System.out.println(newLine);
lines.add(newLine);
} bufferedReader.close();
inputStreamReader.close(); File wfile = new File(wfilePath);
OutputStreamWriter outputStreamWriter = new OutputStreamWriter(new FileOutputStream(wfile), "utf-8");
BufferedWriter bufferedWriter = new BufferedWriter(outputStreamWriter);
for (String eLine : lines) {
bufferedWriter.write(eLine);
bufferedWriter.newLine();
} bufferedWriter.close();
outputStreamWriter.close();
}
}
Java:逐行读、写文件、文件目录过滤的用法的更多相关文章
- 关于使用 Java 分片读\写文件
分片读取文件方法: /** * 分片读取文件块 * * @param path 文件路径 * @param position 角标 * @param blockSize 文件块大小 * @return ...
- java读/写文件
读取文件参考:https://blog.csdn.net/weixin_42129373/article/details/82154471 写入文件参考:https://blog.csdn.net/B ...
- Java基础之写文件——将素数写入文件中(PrimesToFile)
控制台程序,计算素数.创建文件路径.写文件. import static java.lang.Math.ceil; import static java.lang.Math.sqrt; import ...
- java中多种写文件方式的效率对比实验
一.实验背景 最近在考虑一个问题:“如果快速地向文件中写入数据”,java提供了多种文件写入的方式,效率上各有异同,基本上可以分为如下三大类:字节流输出.字符流输出.内存文件映射输出.前两种又可以分为 ...
- C++ 二进制文件 读 写文件
1 #include <iostream> 2 #include <string> 3 #include<fstream> 4 using namespace st ...
- read(),write() 读/写文件
read read()是一个系统调用函数.用来从一个文件中,读取指定长度的数据到 buf 中. 使用read()时需要包含的头文件: <unistd.h> 函数原型: ssize_t re ...
- 在Java中怎样逐行地写文件?
下边是写东西到一个文件里的Java代码. 执行后每一次,一个新的文件被创建,而且之前一个也将会被新的文件替代.这和给文件追加内容是不同的. public static void writeFile1( ...
- Java基础之写文件——从多个缓冲区写(GatheringWrite)
控制台程序,使用单个写操作将数据从多个缓冲区按顺序传输到文件,这称为集中写(GatheringWrite)操作.这个功能的优势是能够避免在将信息写入到文件中之前将信息复制到单个缓冲区中.从每个缓冲区写 ...
- java中IO写文件工具类
以下是一些依据经常使用java类进行组装的对文件进行操作的类,平时,我更喜欢使用Jodd.io中提供的一些对文件的操作类,里面的方法写的简单易懂. 当中jodd中提供的JavaUtil类中提供的方法足 ...
随机推荐
- 走近webpack(0)--正文之前的故事
在前端工作的过程中,只要你接触过vue,angular,react,gulp就一定知道webpack或者听说过或者使用过webpack,但是或许你对webpack的使用方法并不是十分了解,只是会用写好 ...
- 详解小白利用eclipse+CDT+MinGW搭建C++开发环境
安装JDK.安装Eclipse 2.打开Eclipse 找到“help”下的“Eclipse marketplace” 如图: 3.选择相应的C插件: 因为安装过所以显示installe ...
- postman 简单教程-实现简单的接口测试
最近开始做接口测试了,因为公司电脑刚好有postman,于是就用postman来做接口测试,哈哈哈哈,...postman 功能蛮强大的,还比较好用,下面说下postman如何来测试接口 1.下载po ...
- 关于js中promise的面试题。
核心点promise在生命周期内有三种状态,分别是pending,fulfilled或rejected,状体改变只能是 pending-fulfilled,或者pending-rejected.而且状 ...
- 程序猿媛 九:Adroid zxing 二维码3.1集成(源码无删减)
Adroid zxing 二维码3.1集成 声明:博文为原创,文章内容为,效果展示,思路阐述,及代码片段. 转载请保留原文出处“http://my.oschina.net/gluoyer/blog”, ...
- 一个典型的kubernetes工作流程 - kubernetes
1.准备好一个包含应用程序的Deployment的yml文件,然后通过kubectl客户端工具发送给ApiServer. 2.ApiServer接收到客户端的请求并将资源内容存储到数据库(etcd)中 ...
- 事后诸葛亮分析——Beta版本
事后诸葛亮分析 请两个小组在Deadline之前,召开事后诸葛亮会议,发布一篇事后分析报告. 软件工程课的目的,主要是让大家通过做项目,学到软件工程的知识,而不是低水平重复. 软件=程序+软件工程,软 ...
- 项目Beta预备
项目名称:城市安全风险管控系统 Beta预备: 讨论组长是否重选的议题和结论 项目组长可以说是一个团队的灵魂和核心.一个好的领导者可以激发团队成员的工作热情,提高开发效率,保质保量的完成工作.虽然在A ...
- 【iOS】Swift LAZY 修饰符和 LAZY 方法
延时加载或者说延时初始化是很常用的优化方法,在构建和生成新的对象的时候,内存分配会在运行时耗费不少时间,如果有一些对象的属性和内容非常复杂的话,这个时间更是不可忽略.另外,有些情况下我们并不会立即用到 ...
- jwt验证登录信息
为什么要告别session?有这样一个场景,系统的数据量达到千万级,需要几台服务器部署,当一个用户在其中一台服务器登录后,用session保存其登录信息,其他服务器怎么知道该用户登录了?(单点登录), ...