Python-将json文件写入ES数据库
1、安装Elasticsearch数据库
PS:在此之前需首先安装Java SE环境
下载elasticsearch-6.5.2版本,进入/elasticsearch-6.5.2/bin目录,双击执行elasticsearch.bat 打开浏览器输入http://localhost:9200 显示以下内容则说明安装成功

安装head插件,便于查看管理(还可以用kibana)
首先安装Nodejs(下载地址https://nodejs.org/en/)
再下载 elasticsearch-head-master包解压到/elasticsearch-6.5.2/下(链接:https://pan.baidu.com/s/1oX9wKuAYrvY2ZRBT0cos6A
提取码:5ik4)
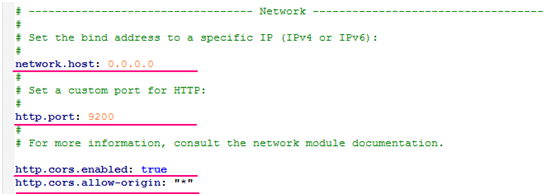
修改配置文件elasticsearch-6.5.2\config\elasticsearch.yml如下:
进入elasticsearch-head-master目录下执行 npm install -g grunt-cli,再执行npm install 安装依赖
在elasticsearch-head-master目录下找到Gruntfile.js文件修改服务器监听地址如下:

执行grunt server命令启动head服务

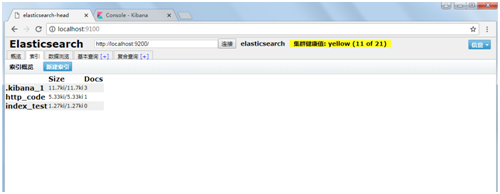
访问地址http://localhost:9100/即可访问head管理页面
2、将json文件写入ES数据库(py脚本如下)
# -*- coding: UTF-8 -*- from itertools import islice
import json , sys
from elasticsearch import Elasticsearch , helpers
import threading _index = 'indextest' #修改为索引名
_type = 'string' #修改为类型名
es_url = 'http://192.168.116.1:9200/' #修改为elasticsearch服务器 reload(sys)
sys.setdefaultencoding('utf-8')
es = Elasticsearch(es_url)
es.indices.create(index=_index, ignore=400)
chunk_len = 10
num = 0 def bulk_es(chunk_data):
bulks=[]
try:
for i in xrange(chunk_len):
bulks.append({
"_index": _index,
"_type": _type,
"_source": chunk_data[i]
})
helpers.bulk(es, bulks)
except:
pass with open(sys.argv[1]) as f:
while True:
lines = list(islice(f, chunk_len))
num =num +chunk_len
sys.stdout.write('\r' + 'num:'+'%d' % num)
sys.stdout.flush()
bulk_es(lines)
if not lines:
print "\n"
print "task has finished"
break
Python-将json文件写入ES数据库的更多相关文章
- JSON文件存入MySQL数据库
目标:将不同格式的JSON文件存入MySQL数据库 涉及的点有: 1. java处理JSON对象,直接见源码. 2. java.sql.SQLException: Incorrect string v ...
- Python读取Json字典写入Excel表格的方法
需求: 因需要将一json文件中大量的信息填入一固定格式的Excel表格,单纯的复制粘贴肯定也能完成,但是想偷懒一下,于是借助Python解决问题. 环境: Windows7 +Python2.7 + ...
- python解析jSON文件
一.jSON文件 http://baike.baidu.com/link?url=wYeeLnhpXX-Tt8AoBRSNPh2P7Z2YHyK2tdD1tbBOQMfJIpA-YNHMOg2ZN6a ...
- Python学习笔记——文件写入和读取
1.文件写入 #coding:utf-8 #!/usr/bin/env python 'makeTextPyhton.py -- create text file' import os ls = os ...
- 使用json文件给es中导入数据
使用json文件可以给es中导入数据,10万条左右的数据可以一次导入,数量太大时导入就会报错.大数量的到导入还是需要用bulk方式. accounts.json文件格式如下: {"index ...
- python中json文件处理涉及的四个函数json.dumps()和json.loads()、json.dump()和json.load()的区分
一.概念理解 1.json.dumps()和json.loads()是json格式处理函数(可以这么理解,json是字符串) (1)json.dumps()函数是将一个Python数据类型列表进行js ...
- python 读 json 文件
一个汽车图标的训练集:train.json [{"items": [{"label_id": "0028", "bbox" ...
- python 读写json文件(dump, load),以及对json格式的数据处理(dumps, loads)
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式.它基于ECMAScript的一个子集. 1.json.dumps()和json.loads()是json ...
- python笔记20-yaml文件写入(ruamel.yaml)
前言 yaml作为配置文件是非常友好的一种格式,前面一篇讲了yaml的一些基础语法和读取方法,本篇继续讲yaml文件写入方法 用yaml模块写入字典嵌套字典这种复杂的数据,会出现大括号{ },不是真正 ...
随机推荐
- restrict关键字(暗示编译器,某个指针指向的空间,只能从该指针访问)
我们希望某个对象(内存空间)不被修改的通常做法是什么?声明该空间的const类型,但是这样真的可以吗?是不是的,由于const空间对象的指针是可以付给一个非const值指针的.所以这仍然无法不让该空间 ...
- Linux时间子系统之五:低分辨率定时器的原理和实现
专题文档汇总目录 Notes:低精度timer在内核中的数据结构以及API接口:低精度timer精巧高效的分组,使用cascade进行定时器移位,组内Timer FIFO:低精度Timer的初始化流程 ...
- Debian虚拟机安装VirtualBox增强功能
作者:荒原之梦 原文链接:http://zhaokaifeng.com/?p=573 本文中使用的Debian是安装在VirtualBox中的虚拟机,具体参数如下: Debian版本:Linux de ...
- Java Code Examples for org.apache.ibatis.annotations.Insert
http://www.programcreek.com/java-api-examples/index.php?api=org.apache.ibatis.annotations.Insert htt ...
- Java 学习笔记 (七) Java 参数
head first java page 74 实参: argument 形参: parameter 方法会运用形参, 调用的一方会传入实参. 实参是传给方法的值.当它传入方法后就成了形参, 参数跟局 ...
- index_levedb.go
) binary.BigEndian.PutUint64(key, fid) return l.db.Delete(key, nil) } //关闭资源 func (l *LevelD ...
- 十条有用的GO技术
十条有用的 Go 技术 这里是我过去几年中编写的大量 Go 代码的经验总结而来的自己的最佳实践.我相信它们具有弹性的.这里的弹性是指: 某个应用需要适配一个灵活的环境.你不希望每过 3 到 4 个月就 ...
- 【莫比乌斯反演】BZOJ3309 DZY Loves Math
Description 对于正整数n,定义f(n)为n所含质因子的最大幂指数.例如f(1960)=f(2^3 * 5^1 * 7^2)=3, f(10007)=1, f(1)=0. 给定正整数a,b, ...
- linux系统日志查看
系统 日志文件( 可以通过cat 或tail 命令来查看) /var/log/message 系统启动后的信息和错误日志,是Red Hat Linux中最常用的日志之一/var/log/secure ...
- EffictiveC++笔记 第2章
Chapter 2 构造 / 析构 / 赋值 条款 05:了解C++ 默默编写并调用哪些函数 如果你写下: class Empty{ }; 事实上编译器会帮你补全: class Empty{ publ ...