kafka HA
1、 replication
如图.1所示,同一个 partition 可能会有多个 replica(对应 server.properties 配置中的 default.replication.factor=N)。没有 replica 的情况下,一旦 broker 宕机,其上所有 patition 的数据都不可被消费,同时 producer 也不能再将数据存于其上的 patition。引入replication 之后,同一个 partition 可能会有多个 replica,而这时需要在这些 replica 之间选出一个 leader,producer 和 consumer 只与这个 leader 交互,其它 replica 作为 follower 从 leader 中复制数据。
Kafka 分配 Replica 的算法如下:
1. 将所有 broker(假设共 n 个 broker)和待分配的 partition 排序
2. 将第 i 个 partition 分配到第(i mod n)个 broker 上
3. 将第 i 个 partition 的第 j 个 replica 分配到第((i + j) mode n)个 broker上
2 leader failover
当 partition 对应的 leader 宕机时,需要从 follower 中选举出新 leader。在选举新leader时,一个基本的原则是,新的 leader 必须拥有旧 leader commit 过的所有消息。
kafka 在 zookeeper 中(/brokers/.../state)动态维护了一个 ISR(in-sync replicas),由3.3节的写入流程可知 ISR 里面的所有 replica 都跟上了 leader,只有 ISR 里面的成员才能选为 leader。对于 f+1 个 replica,一个 partition 可以在容忍 f 个 replica 失效的情况下保证消息不丢失。
当所有 replica 都不工作时,有两种可行的方案:
1. 等待 ISR 中的任一个 replica 活过来,并选它作为 leader。可保障数据不丢失,但时间可能相对较长。
2. 选择第一个活过来的 replica(不一定是 ISR 成员)作为 leader。无法保障数据不丢失,但相对不可用时间较短。
kafka 0.8.* 使用第二种方式。
kafka 通过 Controller 来选举 leader,流程请参考5.3节。
3 broker failover
kafka broker failover 序列图如下所示:
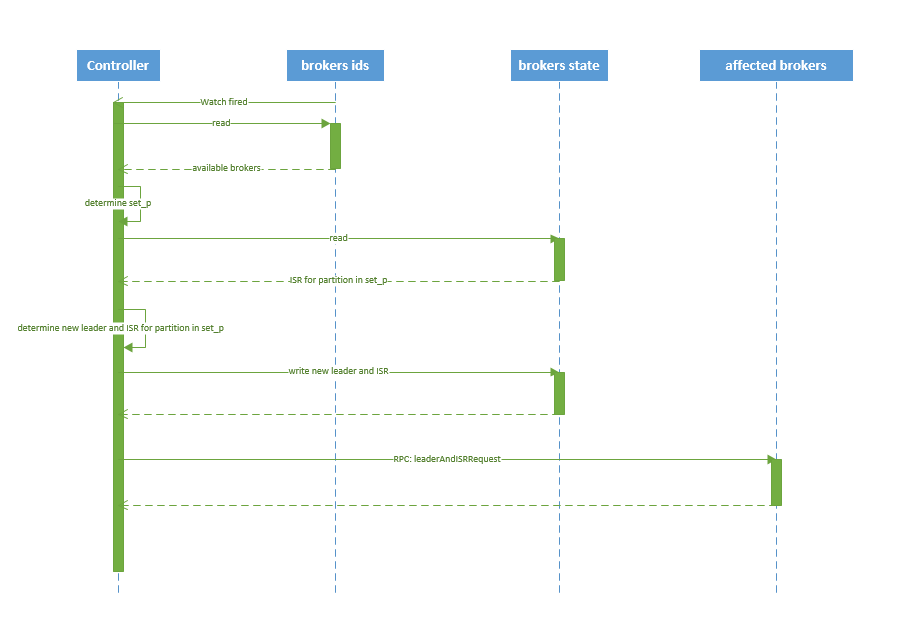
图.7
流程说明:
1. controller 在 zookeeper 的 /brokers/ids/[brokerId] 节点注册 Watcher,当 broker 宕机时 zookeeper 会 fire watch
2. controller 从 /brokers/ids 节点读取可用broker
3. controller决定set_p,该集合包含宕机 broker 上的所有 partition
4. 对 set_p 中的每一个 partition
4.1 从/brokers/topics/[topic]/partitions/[partition]/state 节点读取 ISR
4.2 决定新 leader(如4.3节所描述)
4.3 将新 leader、ISR、controller_epoch 和 leader_epoch 等信息写入 state 节点
5. 通过 RPC 向相关 broker 发送 leaderAndISRRequest 命令
4 controller failover
当 controller 宕机时会触发 controller failover。每个 broker 都会在 zookeeper 的 "/controller" 节点注册 watcher,当 controller 宕机时 zookeeper 中的临时节点消失,所有存活的 broker 收到 fire 的通知,每个 broker 都尝试创建新的 controller path,只有一个竞选成功并当选为 controller。
当新的 controller 当选时,会触发 KafkaController.onControllerFailover 方法,在该方法中完成如下操作:
1. 读取并增加 Controller Epoch。
2. 在 reassignedPartitions Patch(/admin/reassign_partitions) 上注册 watcher。
3. 在 preferredReplicaElection Path(/admin/preferred_replica_election) 上注册 watcher。
4. 通过 partitionStateMachine 在 broker Topics Patch(/brokers/topics) 上注册 watcher。
5. 若 delete.topic.enable=true(默认值是 false),则 partitionStateMachine 在 Delete Topic Patch(/admin/delete_topics) 上注册 watcher。
6. 通过 replicaStateMachine在 Broker Ids Patch(/brokers/ids)上注册Watch。
7. 初始化 ControllerContext 对象,设置当前所有 topic,“活”着的 broker 列表,所有 partition 的 leader 及 ISR等。
8. 启动 replicaStateMachine 和 partitionStateMachine。
9. 将 brokerState 状态设置为 RunningAsController。
10. 将每个 partition 的 Leadership 信息发送给所有“活”着的 broker。
11. 若 auto.leader.rebalance.enable=true(默认值是true),则启动 partition-rebalance 线程。
12. 若 delete.topic.enable=true 且Delete Topic Patch(/admin/delete_topics)中有值,则删除相应的Topic。
kafka HA的更多相关文章
- 7.kafka HA
- kafka学习笔记:知识点整理
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- Kafka设计解析(二)- Kafka High Availability (上)
本文转发自Jason’s Blog,原文链接 http://www.jasongj.com/2015/04/24/KafkaColumn2 摘要 Kafka在0.8以前的版本中,并不提供High Av ...
- 【转载】Kafka High Availability
http://www.haokoo.com/internet/2877400.html Kafka在0.8以前的版本中,并不提供High Availablity机制,一旦一个或多个Broker宕机,则 ...
- kafka原理深入研究 (转 )
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- kafka知识点
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
- [Kafka] [All about it]
Overview 设计目标: 以O(1) 常数级时间复杂度的访问性能,提供消息持久化能力. 高吞吐率. 支持 kafka server 间的消息分区,及分布式消费,同时保证每个partition内部的 ...
- Kafka基本架构及原理
本文转载自http://www.cnblogs.com/cyfonly/p/5954614.html 一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的 ...
- kafka 学习笔记
一.为什么需要消息系统 1.解耦: 允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束. 2.冗余: 消息队列把数据进行持久化直到它们已经被完全处理,通过这一方式规避了数据丢失风险. ...
随机推荐
- echarts 移动端地图数据可视化教程
如上效果图: 以下未代码: <!doctype html> <html lang="en"> <head> <meta charset ...
- 剑指Offer-链表中环的入口结点
package LinkedList; import java.util.HashSet; /** * 链表中环的入口结点 * 一个链表中包含环,请找出该链表的环的入口结点. */ public cl ...
- [SCOI2010] 连续攻击问题
题目 Description lxhgww最近迷上了一款游戏,在游戏里,他拥有很多的装备,每种装备都有2个属性,这些属性的值用[1,10000]之间的数表示.当他使用某种装备时,他只能使用该装备的某一 ...
- webpack4新特性介绍
导语: webpack是一个JS应用打包器, 它将应用中的各个模块打成一个或者多个bundle文件.借助loaders和plugins,它可以改变.压缩和优化各种各样的文件.它的输入是不同的资源,比如 ...
- Linux 绝对路径与相对路径
根据文件名写法的不同,可将所谓的路径(path)定义为绝对路径(absolute)和相对路径(relative). 绝对路径:由根目录(/)开始写起的文件名或目录名称. 相对路径:相对于当前路径的文件 ...
- Java飞机大战源代码
刚学不久java,做了一个飞机大战的小小小小游戏,现在把这个思路总结以及代码分享出来.大佬别吐槽(emmmmmm .....开发环境:jdk1.7 开发工具:eclipese PlanelJPanel ...
- linux --> 为什么寄存器比内存快?
为什么寄存器比内存快 计算机的存储层次(memory hierarchy)之中,寄存器(register)最快,内存其次,最慢的是硬盘. 原因一:距离不同 距离不是主要因素,但是最好懂,所以放在最前面 ...
- Algorithm --> 求1到n的和
求1到n的和 输入n,求和1到n,要求不能使用乘除法,不使用任何if while for 以及三目运算,怎么做? 版本一 static int f(int n) { n && (n + ...
- java程序性能调优---------------性能概述
一.程序的性能通过哪几个方面表现 1.执行速度(程序反应反应是否迅速.响应时间是否足够短) 2.分配内存 (分配内存是否合理,是否过多的消耗内存或者内存溢出) 3.启动时间(程序从运行到可以正常处理业 ...
- iOS移动端直连数据库
一个可以直接连接服务器MySQL的工具包(极不安全,如非特殊需求,不推荐使用) 这种直接连接服务器数据的方式是极为不安全的,但因为我们这个项目特殊情况,只在局域网内使用, 且只有一个pad对一台设备进 ...