python爬虫学习笔记(二)——基础篇之爬虫基本原理
1.什么是爬虫?
请求网站并提取数据的自动化程序
2.爬虫基本流程
2.1发起请求
通过HTTP库向目标站点发起请求,即发起一个Request,请求可以包含额外的headers等信息,等待服务器响应;
2.2获取响应内容
如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML, Json字符串,二进制数据(如图片视频)等类型;
2.3解析内容
得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析;可能是Json,可以直接转为Json对象解析;可能是二进制数据,可以做保存或者进一步的处理。
2.4保存数据
保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件。
3.什么是Request和Response?
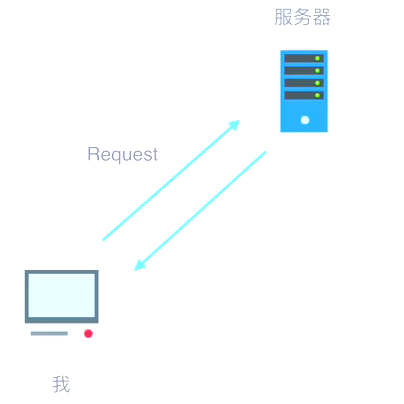
- 浏 览 器 发 送 消 息 给 该 网 址 所 在 的 服 务 器 , 这 个 过 程 叫 做 HTTP Request;
- 服 务 器 收 到 浏 览 器 发 送 的 消 息 后 , 能 够 根 据 浏 览 器 发 送 消 息 的 内 容 , 做 相 应 处 理 , 然 后 把 消 息 回 传 给 浏 览 器 。 这 个 过 程 叫 做 HTTP Response;
- 浏 览 器 收 到 服 务 器 的 Response 信 息 后 , 会 对 信 息 进 行 相 应 处 理 , 然后 展 示 。
3.1request中包含什么?
3.1.1请求方式
主要有GET、POST两种类型,另外还有HEAD、PUT、DELETE、OPTIONS等
- GET:请求的参数已经包含在请求的网址上,网页网址栏,url后的一长串信息就是GET的参数;可以直接输入URL回车访问
- POST:请求的信息在FORM DATA中;构造表单信息,提交后请求(如登陆)
3.1.2请求URL
URL全程:统一资源定位符,如一个网页文档、一张图片、一个视频都可以用URL唯一确定
3.1.3请求头
包含请求时的头部信息,如User-Agent、Host、Cookies等信息;
包含一些比较重要的配置信息
3.1.4请求体
请求时额外携带的数据,如表单提交时的表单数据
3.2.Response
3.2.1响应状态
有多种相应状态,如200代表成功、301跳转、404找不到页面、502服务器错误
3.2.2响应头
如内容类型、内容长度、服务器信息、设置cookie等等
3.2.3响应体
最主要的部分,包含了请求资源的内容,如网页HTML、图片二进制数据等
3.3程序演示
通过request请求,得到response,判断相应状态,成功获取响应体
import requests
response=requests.get('http://www.baidu.com')
if response.status_code==200:#成功
re_text=response.text
re_head=response.headers
print(re_text.encode(encoding='utf-8'))#响应体,这里注意编码
print(re_head)#响应头
4.可以抓怎样的数据?
网页文本
如HTML文档、Json格式文本等
图片
获取的是二进制文件,保存为图片格式
【示例】
1 #requset获取
import requests
response=requests.get('https://www.baidu.com/img/bd_logo1.png')
#print(response.content) with open('baidu.png','wb')asf:
f.write(response.content)
f.close()
视频
同为二进制文件,保存为视频格式即可
其他
只要是能请求到的,都能获取
5.怎样来解析
直接处理
网页本身构成简单,返回内容简单,比如可能返回就是一个最简单的字符串,简单处理去除头尾空格即可
Json解析
正则表达式
BeautifulSoup库解析
PyQuery库解析
XPath库解析
6.为什么抓取数据与获得数据不同?
request只得到源代码(相当于加密过后的):包括js、jss
js、jss后续加载起来后,后台会获取数据,渲染后才会变成我们看到的网页----我们要获取的
7.怎样解决JavaScript渲染的问题?
分析Ajax请求;
Selenium/webdriver;
Splash; ----------后三个模拟加载JS
PyV8、Ghost.py
8.怎样保存数据?
文本
纯文本、Json、XML
关系型数据库
MYSQL、Ocacle、SQL Server
非关系型数据库
MongoDB、Redis等Key-Value形式存储
二进制文件
图片、视频、音频
python爬虫学习笔记(二)——基础篇之爬虫基本原理的更多相关文章
- Python学习笔记之基础篇(-)python介绍与安装
Python学习笔记之基础篇(-)初识python Python的理念:崇尚优美.清晰.简单,是一个优秀并广泛使用的语言. python的历史: 1989年,为了打发圣诞节假期,作者Guido开始写P ...
- Django学习笔记(基础篇)
Django学习笔记(基础篇):http://www.cnblogs.com/wupeiqi/articles/5237704.html
- scrapy爬虫学习系列二:scrapy简单爬虫样例学习
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
- Python 学习笔记(基础篇)
背景:今年开始搞 Data science ,学了 python 小半年,但一直没时间整理整理.这篇文章很基础,就是根据廖雪峰的 python 教程 整理了一下基础知识,再加上自己的一些拓展,方便自己 ...
- mysql学习笔记之基础篇
数据库学习之基础篇 ① 开放数据库互连(Open Database Connectivity,ODBC ② 结构化查询语言(Structured Query Language) ③ 进入mysql:M ...
- java学习笔记之基础篇
java选择语句之switch //switch可以用于等值判断 switch (e) //int ,或则可以自动转化成int 的类型,(byte char short)枚举jdk 7中可以防止字 ...
- Python学习笔记之基础篇(二)python入门
一.pycharm 的下载与安装: 使用教程:https://www.cnblogs.com/jin-xin/articles/9811379.html 破解的方法:http://xianchang. ...
- https学习笔记二----基础密码学知识和python pycrypto库的介绍使用
在更详细的学习HTTPS之前,我也觉得很有必要学习下HTTPS经常用到的加密编码技术的背景知识.密码学是对报文进行编解码的机制和技巧.可以用来加密数据,比如数据加密常用的AES/ECB/PKCS5Pa ...
- Python学习笔记之基础篇(三)python 数据类型 int str bool 详谈
python 的数据类型: 1.int:存放 1,2,3 等数据 ,用于数字的运算 2.bool :True, False 用于判断 3.str:字符串,用来存储少量的数据 4.list : 数组的 ...
- Python学习笔记之基础篇(五)字典
#数据类型划分:可变数据类型 不可变数据类型 #不可变数据类型 : 元组 bool int str --> 可哈希 #可变数据类型 list ,dict set --->不可哈希 ''' ...
随机推荐
- JS Math方法
- wpf binging (六)多绑定
场景 比如我用四个textbox 需要每个控件都输入正确的数据以后 下方的 button才变成可用状态 需要把四个textbox的值转换成 true或者false 效果
- ajax如何渲染数据
染数据的方法 1).字符串拼接, 最常用的方法 优点:只进行一次dom回流 缺点:原有dom的事件都会丢失 原因:就在于innerHTML这个属性,这个属性是返回或设置dom中的内容,以字符串形式返 ...
- python之路之简单介绍:
python介绍: a. python 基础 - 基础 - 基本的数据类型 - 函数 - 面向对象 python 安装 python 安装在os上 执行操作: 写一个文件,文件中按照python规则写 ...
- read读文件
FILE *fp=fopen("F:\\QQBrowser_Setup_DNF.exe", "rb"); fseek(fp, , SEEK_END); long ...
- 2PC(Two Phase Commitment Protocol)原理
读TiDB原理部分,知道其分布式事务是参考的Google percolator.而percolator是一种2PC的优化. 分布式事务解决的是什么问题呢? 假设一个场景,一个电商网站,用户在购买商品时 ...
- Python3.7 练习题(二) 使用Python进行文本词频统计
# 使用Python进行词频统计 mytext = """Background Industrial Light & Magic (ILM) was starte ...
- MATLAB实现Brovey图像融合
自定义函数: function BF=Brovey_fuse(Hyperspectral_image,High_resolution_image) x0=imread(Hyperspectral_im ...
- 12集合(1)-----List
一.总体分类 Collection(包括方法add,remove,contains,clear,size) List(接口) LinkedList ArrayList Vector---Stack 2 ...
- MySQL Sending data导致查询很慢的问题详细分析【转载】
转自http://blog.csdn.net/yunhua_lee/article/details/8573621 [问题现象] 使用sphinx支持倒排索引,但sphinx从mysql查询源数据的时 ...