Java集合实现
set:
public class BSTSet<E extends Comparable<E>> implements Set<E> {
private BST<E> bst;
public BSTSet(){
bst=new BST<>();
}
@Override
public int getSize(){
return bst.size();
}
@Override
public boolean isEmpty(){
return bst.isEmpty();
}
@Override
public void add(E e){
bst.add(e);
}
@Override
public boolean contains(E e){
return bst.contains(e);
}
@Override
public void remove(E e){
bst.remove(e);
}
}
public class LinkedListSet<E> implements Set<E> {
private LinkedList<E> list;
public LinkedListSet(){
list=new LinkedList<>();
}
@Override
public int getSize(){
return list.getSize();
}
@Override
public boolean isEmpty(){
return list.isEmpty();
}
@Override
public boolean contains(E e){
return list.contains(e);
}
@Override
public void add(E e){
if(!list.contains(e))
list.addFirst(e);
}
@Override
public void remove(E e){
list.removeElement(e);
}
}
public class Main {
private static double testSet(Set<String> set,String fileName){
long startTime=System.nanoTime();
System.out.println(fileName);
ArrayList<String> words=new ArrayList<>();
if(FileOperation.readFile(fileName, words)){
System.out.println("Total words:"+words.size());
for(String word:words)
set.add(word);
System.out.println("Total different words: "+set.getSize());
}
long endTime=System.nanoTime();
return (endTime-startTime)/1000000000.0;
}
public static void main(String[] args){
String fileName="a-tale-of-two-cities.txt";
BSTSet<String> bstSet=new BSTSet<String>();
double time1=testSet(bstSet, fileName);
System.out.println("BST Set:"+time1+" s");
System.out.println();
LinkedListSet<String> linkedListSet=new LinkedListSet<String>();
double time2=testSet(linkedListSet, fileName);
System.out.println("Linked List Set:"+time2+" s");
}
}
文件操作:
import java.io.FileInputStream;
import java.util.ArrayList;
import java.util.Scanner;
import java.util.Locale;
import java.io.File;
import java.io.BufferedInputStream;
import java.io.IOException; // 文件相关操作
public class FileOperation { // 读取文件名称为filename中的内容,并将其中包含的所有词语放进words中
public static boolean readFile(String filename, ArrayList<String> words){ if (filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
} // 文件读取
Scanner scanner; try {
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis), "UTF-8");
scanner.useLocale(Locale.ENGLISH);
}
else
return false;
}
catch(IOException ioe){
System.out.println("Cannot open " + filename);
return false;
} // 简单分词
// 这个分词方式相对简陋, 没有考虑很多文本处理中的特殊问题
// 在这里只做demo展示用
if (scanner.hasNextLine()) { String contents = scanner.useDelimiter("\\A").next(); int start = firstCharacterIndex(contents, 0);
for (int i = start + 1; i <= contents.length(); )
if (i == contents.length() || !Character.isLetter(contents.charAt(i))) {
String word = contents.substring(start, i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents, i);
i = start + 1;
} else
i++;
} return true;
} // 寻找字符串s中,从start的位置开始的第一个字母字符的位置
private static int firstCharacterIndex(String s, int start){ for( int i = start ; i < s.length() ; i ++ )
if( Character.isLetter(s.charAt(i)) )
return i;
return s.length();
}
}
import java.util.TreeSet;
public class Solution {
public int uniqueMorseRepresentations(String[] words){
String[] codes = {".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."};
TreeSet<String> set=new TreeSet<>();
for(String word:words){
StringBuilder res=new StringBuilder();
for(int i=0;i<word.length();i++)
res.append(codes[word.charAt(i)-'a']); //返回指定索引处的字符
set.add(res.toString());
}
return set.size();
}
}
有序集合中的元素具有顺序性,基于搜索树的实现
无序集合中的元素没有顺序,基于哈希表实现
public class LinkedListMap<K, V> implements Map<K, V> {
private class Node{
public K key;
public V value;
public Node next;
public Node(K key, V value, Node next){
this.key = key;
this.value = value;
this.next = next;
}
public Node(K key, V value){
this(key, value, null);
}
public Node(){
this(null, null, null);
}
@Override
public String toString(){
return key.toString() + " : " + value.toString();
}
}
private Node dummyHead;
private int size;
public LinkedListMap(){
dummyHead = new Node();
size = 0;
}
@Override
public int getSize(){
return size;
}
@Override
public boolean isEmpty(){
return size == 0;
}
private Node getNode(K key){
Node cur = dummyHead.next;
while(cur != null){
if(cur.key.equals(key))
return cur;
cur = cur.next;
}
return null;
}
@Override
public boolean contains(K key){
return getNode(key) != null;
}
@Override
public V get(K key){
Node node = getNode(key);
return node == null ? null : node.value;
}
@Override
public void add(K key, V value){
Node node = getNode(key);
if(node == null){
dummyHead.next = new Node(key, value, dummyHead.next);
size ++;
}
else
node.value = value;
}
@Override
public void set(K key, V newValue){
Node node = getNode(key);
if(node == null)
throw new IllegalArgumentException(key + " doesn't exist!");
node.value = newValue;
}
@Override
public V remove(K key){
Node prev = dummyHead;
while(prev.next != null){
if(prev.next.key.equals(key))
break;
prev = prev.next;
}
if(prev.next != null){
Node delNode = prev.next;
prev.next = delNode.next;
delNode.next = null;
size --;
return delNode.value;
}
return null;
}
public static void main(String[] args){
System.out.println("Pride and Prejudice");
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("Total words: " + words.size());
LinkedListMap<String, Integer> map = new LinkedListMap<>();
for (String word : words) {
if (map.contains(word))
map.set(word, map.get(word) + 1);
else
map.add(word, 1);
}
System.out.println("Total different words: " + map.getSize());
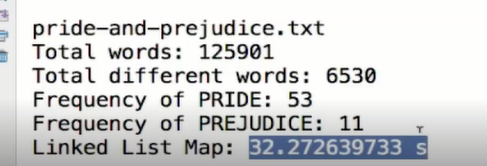
System.out.println("Frequency of PRIDE: " + map.get("pride"));
System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));
}
System.out.println();
}
}
public interface Map<K, V> {
void add(K key, V value);
V remove(K key);
boolean contains(K key);
V get(K key);
void set(K key, V newValue);
int getSize();
boolean isEmpty();
}
二分搜索树的映射实现:
public interface Map<K, V> {
void add(K key, V value);
boolean contains(K key);
V get(K key);
void set(K key, V value);
V remove(K key);
int getSize();
boolean isEmpty();
}
import java.util.ArrayList;
public class BSTMap<K extends Comparable<K>, V> implements Map<K, V> {
private class Node{
public K key;
public V value;
public Node left, right;
public Node(K key, V value){
this.key = key;
this.value = value;
left = null;
right = null;
}
}
private Node root;
private int size;
public BSTMap(){
root = null;
size = 0;
}
@Override
public int getSize(){
return size;
}
@Override
public boolean isEmpty(){
return size == 0;
}
// 向二分搜索树中添加新的元素(key, value)
@Override
public void add(K key, V value){
root = add(root, key, value);
}
// 向以node为根的二分搜索树中插入元素(key, value),递归算法
// 返回插入新节点后二分搜索树的根
private Node add(Node node, K key, V value){
if(node == null){
size ++;
return new Node(key, value);
}
if(key.compareTo(node.key) < 0)
node.left = add(node.left, key, value);
else if(key.compareTo(node.key) > 0)
node.right = add(node.right, key, value);
else // key.compareTo(node.key) == 0
node.value = value;
return node;
}
// 返回以node为根节点的二分搜索树中,key所在的节点
private Node getNode(Node node, K key){
if(node == null)
return null;
if(key.equals(node.key))
return node;
else if(key.compareTo(node.key) < 0)
return getNode(node.left, key);
else // if(key.compareTo(node.key) > 0)
return getNode(node.right, key);
}
@Override
public boolean contains(K key){
return getNode(root, key) != null;
}
@Override
public V get(K key){
Node node = getNode(root, key);
return node == null ? null : node.value;
}
@Override
public void set(K key, V newValue){
Node node = getNode(root, key);
if(node == null)
throw new IllegalArgumentException(key + " doesn't exist!");
node.value = newValue;
}
// 返回以node为根的二分搜索树的最小值所在的节点
private Node minimum(Node node){
if(node.left == null)
return node;
return minimum(node.left);
}
// 删除掉以node为根的二分搜索树中的最小节点
// 返回删除节点后新的二分搜索树的根
private Node removeMin(Node node){
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
node.left = removeMin(node.left);
return node;
}
// 从二分搜索树中删除键为key的节点
@Override
public V remove(K key){
Node node = getNode(root, key);
if(node != null){
root = remove(root, key);
return node.value;
}
return null;
}
private Node remove(Node node, K key){
if( node == null )
return null;
if( key.compareTo(node.key) < 0 ){
node.left = remove(node.left , key);
return node;
}
else if(key.compareTo(node.key) > 0 ){
node.right = remove(node.right, key);
return node;
}
else{ // key.compareTo(node.key) == 0
// 待删除节点左子树为空的情况
if(node.left == null){
Node rightNode = node.right;
node.right = null;
size --;
return rightNode;
}
// 待删除节点右子树为空的情况
if(node.right == null){
Node leftNode = node.left;
node.left = null;
size --;
return leftNode;
}
// 待删除节点左右子树均不为空的情况
// 找到比待删除节点大的最小节点, 即待删除节点右子树的最小节点
// 用这个节点顶替待删除节点的位置
Node successor = minimum(node.right);
successor.right = removeMin(node.right);
successor.left = node.left;
node.left = node.right = null;
return successor;
}
}
public static void main(String[] args){
System.out.println("Pride and Prejudice");
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile("pride-and-prejudice.txt", words)) {
System.out.println("Total words: " + words.size());
BSTMap<String, Integer> map = new BSTMap<>();
for (String word : words) {
if (map.contains(word))
map.set(word, map.get(word) + 1);
else
map.add(word, 1);
}
System.out.println("Total different words: " + map.getSize());
System.out.println("Frequency of PRIDE: " + map.get("pride"));
System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));
}
System.out.println();
}
}
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.ArrayList;
import java.util.Locale;
import java.util.Scanner; // 文件相关操作
public class FileOperation { // 读取文件名称为filename中的内容,并将其中包含的所有词语放进words中
public static boolean readFile(String filename, ArrayList<String> words){ if (filename == null || words == null){
System.out.println("filename is null or words is null");
return false;
} // 文件读取
Scanner scanner; try {
File file = new File(filename);
if(file.exists()){
FileInputStream fis = new FileInputStream(file);
scanner = new Scanner(new BufferedInputStream(fis), "UTF-8");
scanner.useLocale(Locale.ENGLISH);
}
else
return false;
}
catch(IOException ioe){
System.out.println("Cannot open " + filename);
return false;
} // 简单分词
// 这个分词方式相对简陋, 没有考虑很多文本处理中的特殊问题
// 在这里只做demo展示用
if (scanner.hasNextLine()) { String contents = scanner.useDelimiter("\\A").next(); int start = firstCharacterIndex(contents, 0);
for (int i = start + 1; i <= contents.length(); )
if (i == contents.length() || !Character.isLetter(contents.charAt(i))) {
String word = contents.substring(start, i).toLowerCase();
words.add(word);
start = firstCharacterIndex(contents, i);
i = start + 1;
} else
i++;
} return true;
} // 寻找字符串s中,从start的位置开始的第一个字母字符的位置
private static int firstCharacterIndex(String s, int start){ for( int i = start ; i < s.length() ; i ++ )
if( Character.isLetter(s.charAt(i)) )
return i;
return s.length();
}
}
测试:
import java.util.ArrayList;
public class {
private static double testMap(Map<String, Integer> map, String filename){
long startTime = System.nanoTime();
System.out.println(filename);
ArrayList<String> words = new ArrayList<>();
if(FileOperation.readFile(filename, words)) {
System.out.println("Total words: " + words.size());
for (String word : words){
if(map.contains(word))
map.set(word, map.get(word) + 1);
else
map.add(word, 1);
}
System.out.println("Total different words: " + map.getSize());
System.out.println("Frequency of PRIDE: " + map.get("pride"));
System.out.println("Frequency of PREJUDICE: " + map.get("prejudice"));
}
long endTime = System.nanoTime();
return (endTime - startTime) / 1000000000.0;
}
public static void main(String[] args) {
String filename = "pride-and-prejudice.txt";
BSTMap<String, Integer> bstMap = new BSTMap<>();
double time1 = testMap(bstMap, filename);
System.out.println("BST Map: " + time1 + " s");
System.out.println();
LinkedListMap<String, Integer> linkedListMap = new LinkedListMap<>();
double time2 = testMap(linkedListMap, filename);
System.out.println("Linked List Map: " + time2 + " s");
}
}

有序映射中的键具有顺序性,---基于搜索树的实现
无序映射中的键没有顺序性 ----基于哈希表实现
Java集合实现的更多相关文章
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- Scala集合和Java集合对应转换关系
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 用Scala编码的时候,经常会遇到scala集合和Java集合互相转换的case,特意mark一 ...
- java集合你了解多少?
用了java集合这么久,还没有系统的研究过java的集合结构,今天亲自画了下类图,总算有所收获. 一.所有集合都实现了Iterable接口. Iterable接口中包含一个抽象方法:Iterator& ...
- 深入java集合学习1-集合框架浅析
前言 集合是一种数据结构,在编程中是非常重要的.好的程序就是好的数据结构+好的算法.java中为我们实现了曾经在大学学过的数据结构与算法中提到的一些数据结构.如顺序表,链表,栈和堆等.Java 集合框 ...
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- Java集合框架练习-计算表达式的值
最近在看<算法>这本书,正好看到一个计算表达式的问题,于是就打算写一下,也正好熟悉一下Java集合框架的使用,大致测试了一下,没啥问题. import java.util.*; /* * ...
- 【集合框架】Java集合框架综述
一.前言 现笔者打算做关于Java集合框架的教程,具体是打算分析Java源码,因为平时在写程序的过程中用Java集合特别频繁,但是对于里面一些具体的原理还没有进行很好的梳理,所以拟从源码的角度去熟悉梳 ...
- Java 集合框架
Java集合框架大致可以分为五个部分:List列表,Set集合.Map映射.迭代器.工具类 List 接口通常表示一个列表(数组.队列.链表 栈),其中的元素 可以重复 的是:ArrayList 和L ...
- Java集合概述
容器,是用来装东西的,在Java里,东西就是对象,而装对象并不是把真正的对象放进去,而是指保存对象的引用.要注意对象的引用和对象的关系,下面的例子说明了对象和对象引用的关系. String str = ...
- 深入java集合系列文章
搞懂java的相关集合实现原理,对技术上有很大的提高,网上有一系列文章对java中的集合做了深入的分析, 先转载记录下 深入Java集合学习系列 Java 集合系列目录(Category) HashM ...
随机推荐
- mysql 导入出csv
load data infile '/var/lib/mysql-files/ip_address.csv' into table ip_address fields terminated by ', ...
- Python——迭代器
一.概述 迭代器是访问集合元素的一种方式.迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束.迭代器只能往前不会后退. 二.可迭代的对象 序列:字符串.列表.元组 非序列:字典.文件 三 ...
- iOS 利用高德地图WMS服务
Demo: https://github.com/xushiyou23/AMapTesting 转: 版权声明:本文为博主原创文章,未经博主允许不得转载. https://blog.csdn.net ...
- mongoDB 小练习
1 创建数据库名为 grade > use grade switched to db grade 2 创建集合 class 3 插入若干数据 格式如下{name:xxx,age:xxx,sex: ...
- python学习日记(内置函数补充)
剩余匿名函数 序列 序列——列表和元组相关的:list和tuple 序列——字符串相关的:str,format,bytes,bytearry,memoryview,ord,chr,ascii,repr ...
- Linux-服务器创建swap交换分区
服务器 swap 交换分区制作 作用:‘提升‘ 内存的容量,防止OOM(Out Of Memory) 查看当前的交换分区 # cat /proc/swaps # free -m # swapon -s ...
- Unity 阴影的制作方式
Unity阴影制作的三种方式. 方式一:Light中Shadow Type的类型 包括Hard Shadows.Soft Shadows.No Shadows: Mesh Renderer中的属性 ...
- Python通过分页对数据进行展示
# 通过分页对数据进行展示 """ 要求: 每页显示10条数据 让用户输入要查看的页面:页码 """ USER_LIST = [] for ...
- 深入浅出mybatis之映射器
目录 概述 XML映射器 定义xml映射器 配置xml映射器 使用xml映射器 接口映射器 定义接口映射器 配置接口映射器 使用接口映射器 总结与对比 概述 映射器是MyBatis中最核心的组件之一, ...
- SpringBoot系列: 使用 Swagger 生成 API 文档
SpringBoot非常适合开发 Restful API程序, 我们都知道为API文档非常重要, 但要维护好难度也很大, 原因有: 1. API文档如何能被方便地找到? 以文件的形式编写API文档都有 ...