算法工程师<深度学习基础>
<深度学习基础>
卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构,各类优化方法
1、卷积神经网络工作原理的直观解释
https://www.zhihu.com/question/39022858
简单来说,在一定意义上,训练CNN就是在训练每一个卷积层的滤波器。让这些滤波器组对特定的模式有高的激活能力,以达到CNN网络的分类/检测等目的。
2、卷积神经网络的复杂度分析
https://zhuanlan.zhihu.com/p/31575074
3、CNN(卷积神经网络)、RNN(循环神经网络)、DNN(深度神经网络)的内部网络结构有什么区别?
https://www.zhihu.com/question/34681168
4、BP算法中为什么会产生梯度消失?
https://www.zhihu.com/question/49812013
5、梯度下降法是万能的模型训练算法吗?
https://www.zhihu.com/question/38677354
6、LSTM如何来避免梯度消失和梯度爆炸?
https://www.zhihu.com/question/34878706
7、SGD有多种改进的形式(rmsprop、adadelta等),为什么大多数论文中仍然用SGD?
https://www.zhihu.com/question/42115548
8、你有哪些deep learning(rnn,cnn)调参的经验?
https://www.zhihu.com/question/41631631
https://zhuanlan.zhihu.com/p/32230623
10、全连接层的作用是什么?
https://www.zhihu.com/question/41037974
11、深度学习中 Batch Normalization为什么效果好?
https://www.zhihu.com/question/38102762
12、为什么现在的CNN模型都是在GoogleNet、Vggnet或者Alexnet上调整的?
https://www.zhihu.com/question/43370067
13、Krizhevsky等人是怎么想到在CNN里面用Dropout和ReLU的?
https://www.zhihu.com/question/28720729
14、 什么是凸集、凸函数、凸学习问题?
凸集:若对集合C中任意两点u和v,连接他们的线段仍在集合C中,那么集合C是凸集。
公式表示为:αu+(1-α)v∈C α∈[0, 1]
凸函数:凸集上的函数是凸函数。凸函数的每一个局部极小值也是全局极小值( f(x) = 0.5x^2 )。
公式表示为:f(αu + (1-α)v) ≤ αf(u)+ (1-α)f(v)
15、L0、L1、L2正则化?
L0范数:计算向量中非0元素的个数。
L1范数:计算向量中各元素绝对值之和。
L2范数:计算向量中各元素平方和的开方。
L0范数和L1范数目的是使参数稀疏化。L1范数比L0范数容易优化求解。
L2范数是防止过拟合,提高模型的泛化性能。
16、无监督学习方法有哪些?
强化学习、K-means 聚类、自编码、受限波尔兹曼机
17、对空洞卷积(dilated convolution)的理解?
基于FCN的语义分割问题中,需保持输入图像与输出特征图的size相同。
若使用池化层,则降低了特征图size,需在高层阶段使用上采样,由于池化会损失信息,所以此方法会影响导致精度降低;
若使用较小的卷积核尺寸,虽可以实现输入输出特征图的size相同,但输出特征图的各个节点感受野小;
若使用较大的卷积核尺寸,由于需增加特征图通道数,此方法会导致计算量较大;
所以,引入空洞卷积(dilatedconvolution),在卷积后的特征图上进行0填充扩大特征图size,这样既因为有卷积核增大感受野,也因为0填充保持计算点不变。
18、增大感受野的方法?
空洞卷积、池化操作、较大卷积核尺寸的卷积操作
19、卷积层中感受野大小的计算?
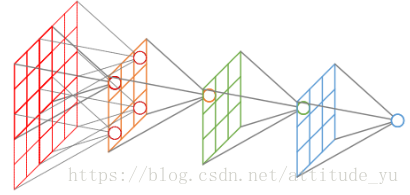
卷积层的感受野大小与其之前层的卷积核尺寸和步长有关,与padding无关。基于从深层向浅层递归计算的方式。计算公式为:Fj-1 = Kj + (Fj - 1)*Sj(最后一层特征图的感受野大小是其计算卷积核大小)
20、梯度下降法和牛顿法的优缺点?
优点:
梯度下降法:可用于数据量较大的情况;
牛顿法:收敛速度更快;
缺点:
梯度下降法:每一步可能不是向着最优解的方向;
牛顿法:每次迭代的时间长;需要计算一阶和二阶导数;
21、解决训练样本类别不平衡问题?
现象:训练样本中,正负样本数量的比例较大。
1. 过采样。增加正例样本数量,使得正负样本数量接近,然后再进行学习。
2. 欠采样。去除反例样本数量,使得正负样本数量接近,然后再进行学习。
3. 设置阈值。基于原始数据集学习,当使用已训练好的分类器进行预测时,将正负样本数量的比例作为阈值嵌入到决策过程中。
22、各个激活函数的优缺点?
Sigmoid激活函数 缺点:
1. 不是关于原点对称;
2. 需要计算exp
Tanh 激活函数 优点:
1. 关于原点对称
2. 比sigmoid梯度更新更快
ReLU激活函数 优点:
1. 神经元输出为正时,没有饱和区
2. 计算复杂度低,效率高
3. 在实际应用中,比sigmoid、tanh更新更快
4. 相比于sigmoid更加符合生物特性
Leaky ReLU激活函数 优点:
1. 解决了ReLU激活函数Dead ReLU问题;
Maxout激活函数max(w1*x+b1,w2*x+b2) 缺点:
2. 参数较多;
23、神经网络的正则化方法?/过拟合的解决方法?
数据增强(镜像对称、随机裁剪、旋转图像、剪切图像、局部弯曲图像、色彩转换)
early stopping(比较训练损失和验证损失曲线,验证损失最小即为最优迭代次数)
L2正则化(权重参数的平方和)
L1正则化(权重参数的绝对值之和)
dropout 正则化(设置keep_pro参数随机让当前层神经元失活)
24、目标检测领域的常见算法?
两阶段检测器:R-CNN、Fast R-CNN、Faster R-CNN
单阶段检测器:YOLO、YOLO9000、SSD、DSSD、RetinaNet
25、Batch Normalization如何实现?作用?
实现过程
计算训练阶段mini_batch数量激活函数前结果的均值和方差,然后对其进行归一化,最后对其进行缩放和平移。
作用
1. 限制参数对隐层数据分布的影响,使其始终保持均值为0,方差为1的分布;
2. 削弱了前层参数和后层参数之间的联系,使得当前层稍稍独立于其他层,加快收敛速度;
3. 有轻微的正则化效果。
26、Momentum优化算法原理?作用?
原理:在梯度下降算法中引入指数加权平均数,在更新梯度方向的过程中,在一定程度上保留了之前梯度更新的方向,同时利用当前mini_batch的梯度方向微调最终的更新方向。
作用:在一定程度上增加梯度更新方向的稳定性,从而使得收敛速度更快。
27、群卷积?
假设上一层的特征图通道数为N,群卷积数目为M,则每个群卷积层上的特征图通道数为N/M,然后将其分配在不同的GPU上,待卷积完成后将输出叠加在一起。
28、反卷积?
卷积的逆过程,GANs基于反卷积操作生成图片。
29、梯度消失和梯度爆炸?
原因:激活函数的选择。
梯度消失:令bias=0,则神经网络的输出结果等于各层权重参数的积再与输入数据集相乘,若参数值较小时,则权重参数呈指数级减小。
梯度爆炸:令bias=0,则神经网络的输出结果等于各层权重参数的积再与输入数据集相乘,若参数值较大时,则权重参数呈指数级增长。
30、质数与互质数
质数是能被1和其本身整除的数;比如2,3,5,7是质数;
互质数是两个数的公因数只有一个1的数;比如8和9、27和32是互质数;
31、生成模型和判别模型
生成方法是首先基于数据学习联合概率分布P(X,Y),然后获得条件概率分布P(Y|X)作为预测模型。
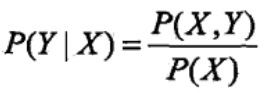
常用模型:隐马尔可夫模型(HMM)、朴素贝叶斯
判别方法是直接基于数据学习到决策函数F或条件概率分布P(Y|X)作为预测模型。
常用模型:支持向量机、K近邻算法、决策树、逻辑回归、感知机、最大熵等
32、从贝叶斯的角度来看,正则化等价于对模型参数引入先验分布,谈谈你对正则化的理解,并且阐述引入L2和L1分别对应什么分布。
正则化的理解:正则化是在损失函数中加入对模型参数的惩罚项,以平衡因子lamda控制惩罚力度,其通过在训练过程中降低参数的数量级,从而降低模型的过拟合现象。
从贝叶斯的角度来看,正则化等价于对模型参数引入先验分布:对参数引入高斯先验分布等价于L2正则化,对参数引入拉普拉斯分布等价于L1正则化。
33、从变换矩阵和变换效果等方面阐述相似变换、仿射变换、投影变换的区别。
等距变换:图像旋转+平移
相似变换:图像旋转+平移+缩放(放大或缩小原图)
仿射变换:图像旋转+平移+缩放+切变(虽改变图像的形状,但未改变图像中的平行线)
投影变换:图像旋转+平移+缩放+切变+射影(不仅改变了图像的形状,而且改变了图像中的平行线)
34、 HOG特征的计算流程
直方图:横轴:间隔,纵轴为各间隔统计值的个数。特点1:显示此数据的的分布情况;特点2:显示各组统计数据的差异;
HOG(histogram of oriented gradient)通过获得局部区域像素的梯度直方图来构成特征。
1. 转化为灰度图;
2. 图像的归一化;
3. 计算各个像素的梯度;
4. 将图像划分为cell(6*6个像素是一个cell)
5. 计算cell区域的梯度直方图(统计各个梯度的数量),构成cell的discripter
6. 将cell划分为block(3*3个cell是一个block),串联block内的cell discripter即可得到此区域的HOG特征discripter
7. 将一幅图像中的Hog discripter串联就是用于分类的特征向量;
35、简述回归,分类,聚类方法的区别和联系并分别举出一个例子,简要介绍算法思路
回归:对连续随机变量建模预测的监督学习算法;经典案例:房价预测;算法举例:线性回归,建立数据的拟合曲线作为预测模型(y = wx + b);
分类:对离散随机变量建模预测的监督学习算法;经典案例:垃圾邮件分类;算法举例:支持向量机,寻找二类支持向量的最大切分超平面;
聚类:基于数据的内部规律,寻找其属于不同族群的无监督学习算法;算法举例:k-means;
36、列举至少三种损失函数,写出数学表达式并简述各自优点
https://blog.csdn.net/heyongluoyao8/article/details/52462400
0-1损失 感知机损失 绝对值损失
平方误差损失(线性回归)
对数损失(逻辑回归)
指数损失(Adaboost)
铰链损失(SVM)
37、分类问题的评价标准
准确率 = (TP+TN)/总样本数
精确率 = TP/(TP+FP) = 所有预测为正类样本中正类的概率
召回率 = TP/(TP+FN) = 所有真正类样本中正类的概率
2/调和平均值 = 1/精确率+1/召回率
P-R曲线:纵轴为精确率,横轴为召回率,基于平衡点(P=R)度量各个基分类器的优劣;
ROC曲线:纵轴为TPR,横轴为FPR
TPR = TP/(TP+FN) FPR = FP/(FP+TN)
AUC:ROC曲线下的面积
mAP = 所有类别的AP之和/类别数量
P = (一张图片类别C识别正确数量)/(一张图片类别C的总数量)
AP = 每张图片的P之和/图片数量
38、回归问题的评价指标
平均绝对值误差(MAE)
均方差(MSE)
39、逻辑回归和SVM的区别和联系
1.损失函数不同,LR损失函数是对数损失;SVM损失函数是hinge损失;参考https://www.cnblogs.com/daguankele/p/6652597.html
2.LR考虑了所有点的损失,但通过非线性操作大大减小离超平面较远点的权重;SVM仅考虑支持向量的损失
3.LR受类别平衡的影响;SVM则不受类别平衡的影响;
4.LR适合较大数据集;SVM适合较小数据集
40、深度学习为什么在计算机视觉领域这么好
以目标检测为例,传统的计算机视觉方法需首先基于经验手动设计特征,然后使用分类器分类,这两个过程都是分开的。而深度学习里的卷积网络可实现对局部区域信息的提取,获得更高级的特征,当神经网络层数越多时,提取的特征会更抽象,将更有助于分类,同时神经网路将提取特征和分类融合在一个结构中。
41、 Bagging和Boosting之间的区别?
1.从样本选择角度:
Bagging采用随机有放回的采样方式(Boostraping);Boosting使用所有样本,但每个样本的权重不同;
2.从决策方式角度:
Bagging分类预测采用大多数投票选举法,回归预测采用各基分类器预测结果的平均值;Boosting采用各基分类器在不同权重作用下预测结果的累加和;
3.从方差、偏差角度:
Bagging以减小方差为目的;Boosting以减少偏差为目的;
模型过拟合,则方差大,Bagging以随机采样样本的方式减少异常样本的选择比例,从而可以降低过拟合,随之也就减小了方差;
Boosting的损失函数就是以减少偏差为目的来训练下一个基分类器;
4.从权重角度:
Bagging各个样本的权重相同,各个基分类器权重相同;Boosting各个样本的权重不同,正确预测的样本权重减小,错误预测的样本权重增大;各个基分类器的权重不同,预测准确率高的权重大,预测准确率低的权重小;
42、常用的池化操作有哪些?
1.Max pooling:选取滑动窗口的最大值
2.Average pooling:平均滑动串口的所有值
3.Global average pooling:平均每页特征图的所有值
优点:
1.解决全连接层所造成的过拟合问题
CNN网络需要将特征图reshape成全连接层,然后再连接输出层,而global average pooling不需要此操作,直接将特征图pooling成输出层
2.没有权重参数
43、朴素贝叶斯的朴素是什么意思?
朴素指的是各个特征之间相互独立。
44、1*1卷积核的作用?
1.跨通道信息的融合;
2.通过对通道数的降维和升维,减少计算量;
45、 随机森林的随机性指的是?
1.决策树训练样本是有放回随机采样的;
2.决策树节点分裂特征集是有放回随机采样的;
46、 随机森林和GBDT算法的区别?
1.并行和串行
随机森林是并行算法,GBDT算法是串行算法
2.决策方式
随机森林分类问题采用大多数投票选举法,回归问题采用各基分类器结果的平均值;GBDT算法采用各基分类器预测结果的累加和;
3.样本选择
随机森林各基分类器采用有放回随机采样的方式;GBDT则使用所有的样本;
4.偏差、方差
随机森林通过降低方差提高性能;GBDT通过降低偏差提高性能;
5.异常值
随机森林对异常值不敏感;GBDT对异常值敏感;
47、为什么ReLU常用于神经网络的激活函数?
1.在前向传播和反向传播过程中,ReLU相比于Sigmoid等激活函数计算量小;
2.在反向传播过程中,Sigmoid函数存在饱和区,若激活值进入饱和区,则其梯度更新值非常小,导致出现梯度消失的现象。而ReLU没有饱和区,可避免此问题;
3.ReLU可令部分神经元输出为0,造成网络的稀疏性,减少前后层参数对当前层参数的影响,提升了模型的泛化性能;
48、卷积层和全连接层的区别?
1.卷积层是局部连接,所以提取的是局部信息;全连接层是全局连接,所以提取的是全局信息;
2.当卷积层的局部连接是全局连接时,全连接层是卷积层的特例;
49、偏差和方差的区别?
偏差是真实值和预测值之间的偏离程度;方差是预测值得分散程度,即越分散,方差越大;
50、机器学习和深度学习的区别?
机器学习在训练模型之前,需要手动设置特征,即需要做特征工程;深度学习可自动提取特征;所以深度学习自动提取的特征比机器学习手动设置的特征鲁棒性更好;
51、神经网络的优缺点?
优点:
1.拟合复杂的函数
随着神经网络层数的加深,网络的非线性程度越来越高,从而可拟合更加复杂的函数;
2.结构灵活
神经网络的结构可根据具体的任务进行相应的调整,选择适合的网络结构;
3.神经网络可自动提取特征,比人工设置的特征鲁棒性更好;
缺点:
1.由于神经网络强大的假设空间,使得神经网络极易陷入局部最优,使得模型的泛化能力较差;
2.当网络层数深时,神经网络在训练过程中容易产生梯度消失和梯度下降的问题;
3.随着网络层数的加深,神经网络收敛速度越来越慢;
4.神经网络训练参数多,占用内存大;
52、 解决过拟合的方法
1.数据增强
2.Ealy stopping
3.Dropout
4.交叉验证
5.L1、L2正则化
算法工程师<深度学习基础>的更多相关文章
- 算法工程师<编程题>
<编程题> 1.[Maximum Product Subarray 求最大子数组乘积] 这个求最大子数组乘积问题是由最大子数组之和问题演变而来,但是却比求最大子数组之和要复杂,因为在求和的 ...
- (C/C++) 算法,编程题
注: 如下的题目皆来自互联网,答案是结合了自己的习惯稍作了修改. 1. 求一个数的二进制中的1的个数. int func(int x) { ; while (x) { count++; x = x&a ...
- 网易开发工程师编程题 比较重量 Java
比较重量 小明陪小红去看钻石,他们从一堆钻石中随机抽取两颗并比较她们的重量.这些钻石的重量各不相同.在他们们比较了一段时间后,它们看中了两颗钻石g1和g2.现在请你根据之前比较的信息判断这两颗钻石的哪 ...
- 链家2018春招Java工程师编程题题解
Light 题目描述 在小红家里面,有n组开关,触摸每个开关,可以使得一组灯泡点亮.现在问你,使用这n组开关,最多能够使得多少个灯泡点亮呢? 输入 第一行一个n,表示有n组开关.接下来n行,每行第一个 ...
- 京东2019春招Java工程师编程题题解
生成回文串 题目描述 对于一个字符串,从前开始读和从后开始读是一样的,我们就称这个字符串是回文串. 例如"ABCBA","AA","A"是回 ...
- 爱奇艺2018春招Java工程师编程题题解
字典序最大子序列 题目描述 对于字符串a和b,如果移除字符串a中的一些字母(可以全部移除,也可以一个都不移除)就能够得到字符串b我们就称b是a的子序列. 例如."heo"是&quo ...
- 寻找第K大 网易2016实习研发工程师编程题
有一个整数数组,请你根据快速排序的思路,找出数组中第K大的数. 给定一个整数数组a,同时给定它的大小n和要找的K(K在1到n之间),请返回第K大的数,保证答案存在. 测试样例: [1,3,5,2,2] ...
- 网易2016 实习研发工程师 [编程题]寻找第K大 and leetcode 215. Kth Largest Element in an Array
传送门 有一个整数数组,请你根据快速排序的思路,找出数组中第K大的数. 给定一个整数数组a,同时给定它的大小n和要找的K(K在1到n之间),请返回第K大的数,保证答案存在. 测试样例: [1,3,5, ...
- 算法是什么我记不住,But i do it my way. 解一道滴滴出行秋招编程题。
只因在今日头条刷到一篇文章,我就这样伤害我自己,手贱. 刷头条看到一篇文章写的滴滴出行2017秋招编程题,后来发现原文在这里http://www.cnblogs.com/SHERO-Vae/p/588 ...
- C算法编程题系列
我的编程开始(C) C算法编程题(一)扑克牌发牌 C算法编程题(二)正螺旋 C算法编程题(三)画表格 C算法编程题(四)上三角 C算法编程题(五)“E”的变换 C算法编程题(六)串的处理 C算法编程题 ...
随机推荐
- for循环增强
for(声明语句 : 表达式) { //代码句子 } 声明语句:声明新的局部变量,该变量的类型必须和数组元素的类型匹配.其作用域限定在循环语句块,其值与此时数组元素的值相等. 表达式:表达式是要访问的 ...
- 【linux】Python3.6安装报错 configure: error: no acceptable C compiler found in $PATH
安装python的时候出现如下的错误: [root@master ~]#./configure --prefix=/usr/local/python3.6 checking build system ...
- springdata 一对多 级联操作 在注解里面开启级联操作@OneToMany(mappedBy = "customer",cascade = CascadeType.ALL)
- 代理与hook
参考:Java 动态代理 代理是什么 为什么需要代理呢?其实这个代理与日常生活中的“代理”,“中介”差不多:比如你想海淘买东西,总不可能亲自飞到国外去购物吧,这时候我们使用第三方海淘服务比如惠惠购物助 ...
- C# 中使用面向切面编程(AOP)中实践代码整洁
1. 前言 最近在看<架构整洁之道>一书,书中反复提到了面向对象编程的 SOLID 原则(在作者的前一本书<代码整洁之道>也是被大力阐释),而面向切面编程(Aop)作为面向对象 ...
- Gradle+IDEA使用说明
Gradle+IDEA使用说明 导语: IDEA拥有大量的JAVA开发者拥护,相比于开源的eclipse,IDEA拥有更简洁直观的界面,拥有更强大的自动补全功能,号称能“一路敲回车完成编码”.如果把I ...
- Linux keepalived+nginx实现主从模式
双机高可用方法目前分为两种: 主从模式:一台主服务器和一台从服务器,当配置了虚拟vip的主服务器发送故障时,从服务器将自动接管虚拟ip,服务将不会中断.但主服务器不出现故障的时候,从服务器永远处于浪费 ...
- 牛客网 272B Xor Path(树上操作)
题目链接:Xor Path 题意:每个顶点的点权为Ai,任意两点路径上点权异或和为Path(i,j),求所有Path(i,j)和. 题解:考虑每个顶点被用到的次数,分以下三种情况: 1.本身和其他顶点 ...
- MySql存储过程 CURSOR循环
游标 游标(Cursor)是处理数据的一种方法,为了查看或者处理结果集中的数据,游标提供了在结果集中一次一行或者多行前进或向后浏览数据的能力. 使用步骤 声明一个游标: declare 游标名称 CU ...
- Spring Cloud微服务实践之路- Eureka Server 中的第一个异常
EMERGENCY! EUREKA MAY BE INCORRECTLY CLAIMING INSTANCES ARE UP WHEN THEY'RE NOT. RENEWALS ARE LESSER ...