Apache Druid架构原理与应用场景
为了帮助卖家提高运营水平,卖家管理后台会展示一些访客、订单等趋势和指标数据,如PV,UV,转化率,GMV等;
这些指标的计算依靠前端埋点和订单详情等数据,其特点是数据量大,并有一定的实时性要求。
Druid本质是一个分布式时序数据库,其设计恰好满足这个场景:
Historical数据存储使用HDFS等成熟的分布式文件系统方案,高可用、水平扩容
Lambda架构,Realtime部分使用LSM-Tree实现,满足流数据的即时查询需求
下面从2方面,整理一下Druid的关键技术点:
Druid架构设计
数据摄入
几个重要配置
一、Druid架构设计
Druid自身包含下面4类节点:
Realtime Node:即时摄入实时数据,生成Segment(LSM-Tree实现与Hbase基本一致,不再赘述)文件。
Historical Node:加载已生成好的数据文件,以供数据查询。
Broker Node:对外提供数据查询服务,并同时从Realtime Node和Historical Node查询数据,合并后返回给调用方。
Coordinator Node:负责Historical Node的数据负载均衡,以及通过Rule管理数据生命周期。

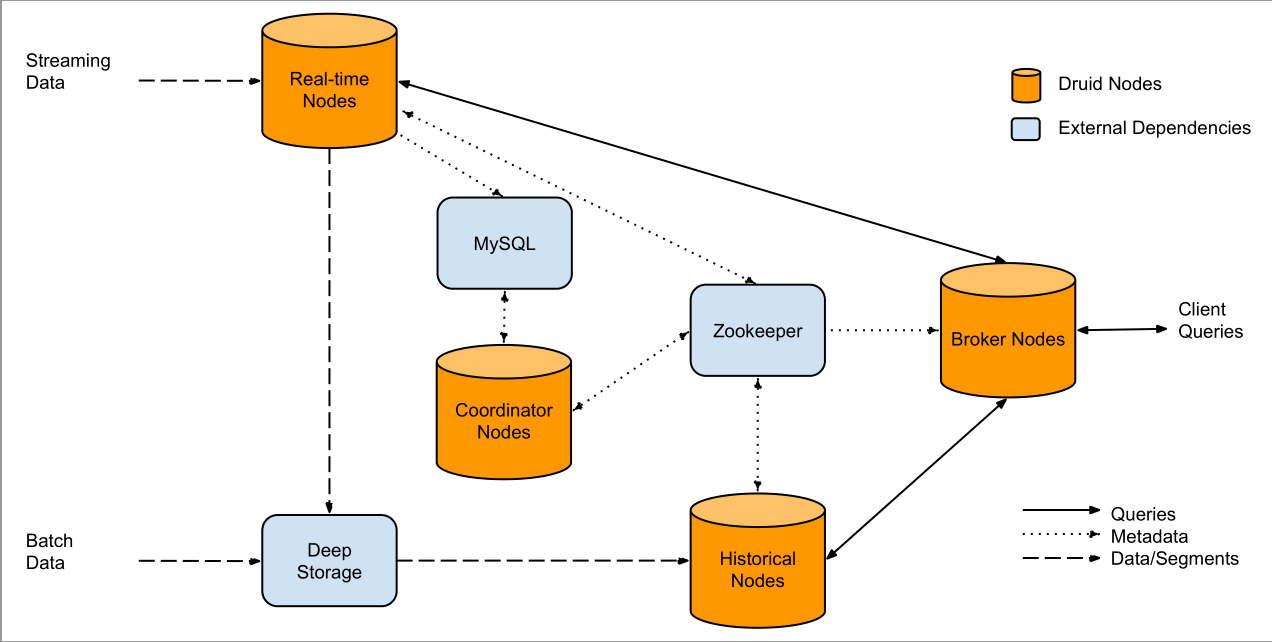
同时,Druid集群还包含以下3类外部依赖:
元数据库(Metastore):存储druid集群的元数据信息,如Segment的相关信息,一般使用MySQL或PostgreSQL
分布式协调服务(Coordination):为Druid集群提供一致性服务,通常为zookeeper
数据文件存储(DeepStorage):存储生成的Segment文件,供Historical Node下载,一般为使用HDFS
二、数据摄入
Realtime Node为LSM-Tree架构,与Hbase实现不同,Druid未提供WAL功能,牺牲数据可靠性,换写入速度。
实时数据到达Realtime Node后,被直接加载到堆缓冲区(Hbase memtable -> RB-Tree),当堆缓冲区大小达到阈值,数据被冲洗到磁盘,形成一个Segment(SSTable),同时Realtime Node立即将新生成的Segment加载到内存非堆区。堆区与非堆区都可以被Broker Node查询。
同时,Realtime Node周期性扫描磁盘Segment,将同一时间段生成的所有Segment合并为一个大的Segment。这个过程叫Segment Merge(相当于hbase中的compaction)。合并完的Segment被Realtime Node上传到DeepStorage,随后Coordinator Node通知一个Historical Node去Deepstorage将新生成的Segment下载到本地,并加载到内存(尽可能使用内存,不足时LRU淘汰),成功加载后,Historical Node通知Coordinator Node,声明其接管这个Segment的查询操作,Realtime Node收到声明后,也向Coordinator Node声明,其不再提供此Segment查询。
除了Segment,Druid设计还有一个重要数据结构:Datasource。Datasource可理解为RDBMS数据库中的表,其包含以下几个方面:
时间列(Timestamp):表明每行数据的时间值,默认使用UTC时间格式且精确到ms级别。这个列是数据聚合与范围查询的重要维度
维度列(Dimension)
指标列(Metric):指标对应于OLAP中的Fact,是用于聚合和计算的列。这些指标列通常是一些数字,计算操作通常包括Count, Sum和Mean等
相对于其它时序数据库,Druid在数据存储时便可以对数据进行聚合操作,该特点使Druid不仅能够节省存储空间,而且提高聚合查询效率。
Datasource是一个逻辑概念,Segment却是数据的实际物理存储格式,Druid通过Segment实现对数据的横各与纵向切割。
从数据按时间分布角度看,通过参数segmentGranularity的设置,Druid将不同时间范围内的数据存储在不同的Segment数据块中,这是数据的横向切割。这种设计带来的优点是:按时间范围查询数据时,仅需访问对应时间段内的Segment,而不需要全表扫描。
同时Segment中也面向列进行数据压缩(列式存储),这是纵向切割。
总结一下数据摄入过程:
Realtime Node生成Segment数据文件,并上传到Deepstorage(HDFS)
Segment相关元数据信息被保存到Metastore中(MySQL)
Coordinator Node收到通知从Metastore获取Segment数据文件的相关元数据,将其根据Rule分配给符合条件的Historical Node
Historical Node得到命令,主动从Deepstorage拉取Segment文件,并通过Zookeeper向集群声明其负责该Segment的查询服务
Realtime Node丢弃该Segment文件,并向集群声明不再提供该Segment查询服务
三、几个重要配置
segmentGranularity
The granularity to create segments at. default == 'DAY'
queryGranularity
Druid数据进行Roll-up的时间间隔
The minimum granularity to be able to query results at and the granularity of the data inside the segment. E.g. a value of "minute" will mean that data is aggregated at minutely granularity. That is, if there are collisions in the tuple (minute(timestamp), dimensions), then it will aggregate values together using the aggregators instead of storing individual rows. A granularity of 'NONE' means millisecond granularity. default == 'NONE'
intermediatePersistPeriod
The period that determines the rate at which intermediate persists occur. These persists determine how often commits happen against the incoming realtime stream. If the realtime data loading process is interrupted at time T, it should be restarted to re-read data that arrived at T minus this period. default == PT10M
windowPeriod
Druid数据丢失的问题
The windowPeriod is the slack time permitted for events. For example, a windowPeriod of ten minutes (the default) means that any events with a timestamp older than ten minutes in the past, or more than ten minutes in the future, will be dropped.
These are important configurations because they influence how long tasks will be alive for, and how long data stays in the realtime system before being handed off to the historical nodes. For example, if your configuration has segmentGranularity "hour" and windowPeriod ten minutes, tasks will stay around listening for events for an hour and ten minutes. For this reason, to prevent excessive buildup of tasks, it is recommended that your windowPeriod be less than your segmentGranularity.
Apache Druid架构原理与应用场景的更多相关文章
- RocketMQ架构原理解析(四):消息生产端(Producer)
RocketMQ架构原理解析(一):整体架构 RocketMQ架构原理解析(二):消息存储(CommitLog) RocketMQ架构原理解析(三):消息索引(ConsumeQueue & I ...
- NET/ASP.NET Routing路由(深入解析路由系统架构原理)(转载)
NET/ASP.NET Routing路由(深入解析路由系统架构原理) 阅读目录: 1.开篇介绍 2.ASP.NET Routing 路由对象模型的位置 3.ASP.NET Routing 路由对象模 ...
- 谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景?
在日常开发中,尤其是业务开发,少不了利用 Java 对数据库进行基本的增删改查等数据操作,这也是 Java 工程师的必备技能之一.做好数据操作,不仅仅需要对 Java 语言相关框架的掌握,更需要对各种 ...
- Hive的配置| 架构原理
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能. 本质是:将HQL转化成MapReduce程序 1)Hive处理的数据存储在HDFS 2)Hi ...
- 简单理解Hadoop架构原理
一.前奏 Hadoop是目前大数据领域最主流的一套技术体系,包含了多种技术. 包括HDFS(分布式文件系统),YARN(分布式资源调度系统),MapReduce(分布式计算系统),等等. 有些朋友可能 ...
- 【Shiro】Apache Shiro架构之权限认证(Authorization)
Shiro系列文章: [Shiro]Apache Shiro架构之身份认证(Authentication) [Shiro]Apache Shiro架构之集成web [Shiro]Apache Shir ...
- Elasticsearch架构原理
架构原理 本书作为 Elastic Stack 指南,关注于 Elasticsearch 在日志和数据分析场景的应用,并不打算对底层的 Lucene 原理或者 Java 编程做详细的介绍,但是 Ela ...
- zz《分布式服务架构 原理、设计与实战》综合
这书以分布式微服务系统为主线,讲解了微服务架构设计.分布式一致性.性能优化等内容,并介绍了与微服务系统紧密联系的日志系统.全局调用链.容器化等. 还是一样,每一章摘抄一些自己觉得有用的内容,归纳整理, ...
- 第36讲 谈谈MySQL支持的事务隔离级别,以及悲观锁和乐观锁的原理和应用场景
在日常开发中,尤其是业务开发,少不了利用 Java 对数据库进行基本的增删改查等数据操作,这也是 Java 工程师的必备技能之一.做好数据操作,不仅仅需要对 Java 语言相关框架的掌握,更需要对各种 ...
随机推荐
- 【转】 svn: Server sent unexpected return value (403 Forbidden) in response to CHECKOUT request for-解决方法
来源:http://blog.csdn.net/xhu_eternalcc/article/details/18454481 ------------------------------------- ...
- python note 4
1.使用命令行打开文件 t=open('D:\py\123.txt','r') t.read() 在python和很多程序语言中""转义符号,要想输出\要么多加一个\写成\ 要么在 ...
- 接口压力测试--Jmeter
1.Jmeter简介 JMeter就是一个测试工具,相比于LoadRunner等测试工具,此工具免费,且比较好用,但是前提当然是安装Java环境: JMeter可以做 (1)压力测试及性能测试: (2 ...
- tensorflow estimator API小栗子
TensorFlow的高级机器学习API(tf.estimator)可以轻松配置,训练和评估各种机器学习模型. 在本教程中,您将使用tf.estimator构建一个神经网络分类器,并在Iris数据集上 ...
- JS 函数参数 及 函数数组
<script> function a(){ alert("a"); } function b(){ alert("b"); } var arr = ...
- 多选框取值checkbox
取值//js var obj = document.getElementsByName("NAME"); var s=''; for(var i=0;i<obj.length ...
- Windows Server 2008 R2 服务器系统安装及配置全过程图文详解
前言 本文主要介绍了 windows Server 2008 R2 服务器系统的安装及相关配置. 介绍的是以优盘的方式安装. 写这篇博文的目的一来是为了供有需要的网友参考, 二来自己也在此做个记载. ...
- 实训任务04 MapReduce编程入门
实训任务04 MapReduce编程入门 1.实训1:画图mapReduce处理过程 使用有短句“A friend in need is a friend in deed”,画出使用MapReduce ...
- MyLog
using System;using System.Collections.Generic;using System.IO;using System.Linq;using System.Text;us ...
- [转]sqlldr 导入乱码,Oracle客户端字符集问题
1,查Oracle数据库创建时候的字符集:oracle服务器端执行 SQL> select name, value$ from sys.props$ where name like 'NLS%' ...