排序学习实践---ranknet方法
要: 1 背景 随着移动互联网的崛起,越来越多的用户开始习惯于从手机完成吃、喝、玩、乐、衣、食、住、行等各个方面的需求。打开手机,点开手淘、美团等APP,商品玲玲满目,而让用户将所有商品一页页看完已经不现实,通常情况下用户也就查看前几页,如果找不到满意的商品则退出,从而造成流单。
1 背景
随着移动互联网的崛起,越来越多的用户开始习惯于从手机完成吃、喝、玩、乐、衣、食、住、行等各个方面的需求。打开手机,点开手淘、美团等APP,商品玲玲满目,而让用户将所有商品一页页看完已经不现实,通常情况下用户也就查看前几页,如果找不到满意的商品则退出,从而造成流单。因此如何对商品进行排序使得用户能尽快完成购买流程已经成为这些平台的重要攻克方向。
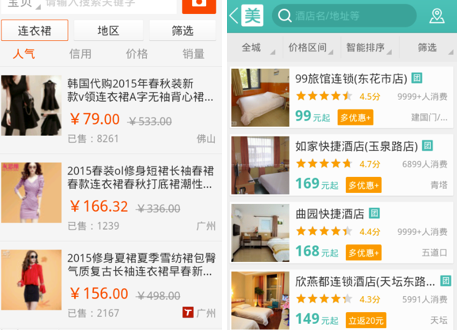
图1 手机淘宝、美团等app的商品排序示意
传统的方法是找几个特征比如评分、销量等,然后找个打分函数如简单的线性函数:F=w1*评分+w2*销量+...,并通过手工调整权重值w并结合abtest实验来达到排序的目的(分数越高排名越高)。
这种方法非常简单,但面临着一些问题:1)每当增加一个特征都得调整所有特征的权重,并在线上进行abtest,费时费力;2)特征较多时(当引入个性化特征时),这种手工调整权重的方式已经不可能完成,很难找到一个较优解;3)随着数据的不断变化,每隔一段时间都需要人工重新调节权重。总体来讲人工调参费时费力、效果也差!
为了避免人工调参,现在工业界主要采用排序学习方法。
2 排序学习简介
排序学习的目的就是通过一些自动化的方法完成模型参数的训练。根据不同类型的训练数据可以将排序学习方法分为以下三类:a)单点标注(point wise);b)两两标注(pair wise);c)列表标注(list wise)。
2.1 point wise过程
下面介绍如何使用point wise方法来完成排序学习。
排序学习最重要的工作就是构造训练样本,即得到一组(V1,V2,V3,..., Y),其中V是特征,Y是label,得到样本之后带入相应的机器学习模型即可完成训练。
一般来说特征可分成以下几类(根据业务不同可自行添加特征):a)商品(文档)本身特征如:评分、销量、价格等;b)用户本身特征如:性别、年龄、用户的商品类型偏好等;c)用户-商品关联特征如:是否看过此商品、是否买过此商品、对此商品的历史评价等;d)场景特征如:时间(早中晚)、与商品的距离、是否是节假日等。一般来说我们需要将这些特征进行归一化,原因参见:为什么一些机器学习模型需要对数据进行归一化?
找到特征后需要定义label。我们认为给用户展示过的商品label为1,用户点击过的商品label为3,用户购买过的商品label为7。
通过对历史日志数据的清洗整理我们可以得到成千上万的样本(V1,V2,V3,..., Y)。
得到样本之后我们可以将此排序问题转换为多分类问题(样本特征-类别标记)或者回归问题(样本特征-连续值)。如果转换为多分类问题,我们模型最后的输出只能1、3或是7,往往导致在同一类中的文档(比如两个文档输入模型的得到的结果都是7)不好继续排序,因此实际使用中往往将问题转换为回归问题,常常采用LR、GBDT等来解决。
2.2 point wise缺点
point wise方法很直观,非常容易将问题转换为我们所熟知的问题,但其缺点是完全从单文档的分类角度计算,没有考虑文档之间的相对顺序。
举个例子。假设图2左图红框为某一次用户点击的事件,这时候我们获得一条样本i (V1i,V2i,V3i,...,Xni, 3)。右图红框为某一次用户点击的事件,我们获得一条样本j (V1j,V2j,V3j,...,Vnj, 3)。按照pointwise的思想,我们认为这两条样本的label都是3。但在第二张图包含更重要的信息,“用户只点了红框内的酒店,而没有点绿框内的酒店(绿框内的酒店和左图点击的酒店一致)”,即说明样本j的label应该比样本i的label大(样本j排名比样本i更靠前),而pointwise并没有利用到这个信息。
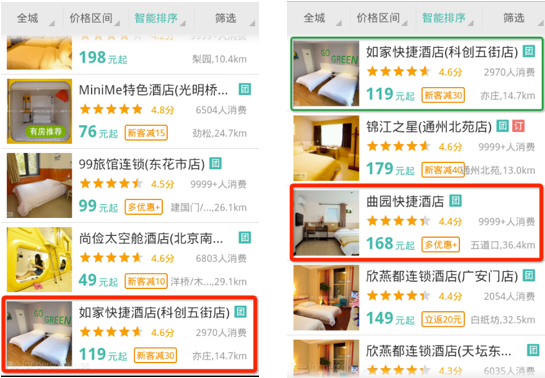
图2 point wise缺点示意图
自然我们的问题就是:如何将文档之间相对顺序信息利用进去呢?
2.3 pair wise方法
在pairwise方法中,我们不再从从单文档的分类角度来看待问题,而是从一个文档对如<d1,d2>来看待问题,即如图2右图所示,用户点击了红框的商品(d1)而没有点击绿框中的商品(d2),那这个时候认为d1的相关性大于d2,那么我们可以把 d1-d2的label设置为+1,d2-d1的label设置为为 -1。按照这种方式,我们就得到了二元分类器训练所需的样本了。预测时,只需要对所有pair进行分类,便可以得到文档集的一个偏序关系,从而实现排序。Pairwise方法有很多的实现,比如SVM Rank、RankNet、FRank、RankBoost等。
下面我们着重介绍下ranknet的原理以及应用。
3 ranknet
3.1 ranknet原理
假设有文档i和j,其中文档i的特征向量是Xi(1i, v2i, v3i, ..., vni),文档j的特征向量是Xj(v1i, v2j, v3j, ..., vnj),我们要找一个打分函数F,假设F是线性函数,F(Xi)=W*Xi=w1*v1i + w1*v2i + ... + wn*vni,其中w表示权重系数,F(Xi)表示针对文档Xi给出的得分。
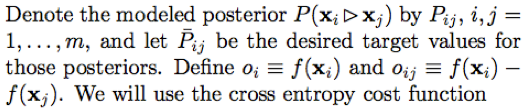
我们希望找出这样一个函数F(本质上是训练得到这些权重w),当文档X1比X2排名高时,我们希望F(Xi) > F(Xj)。
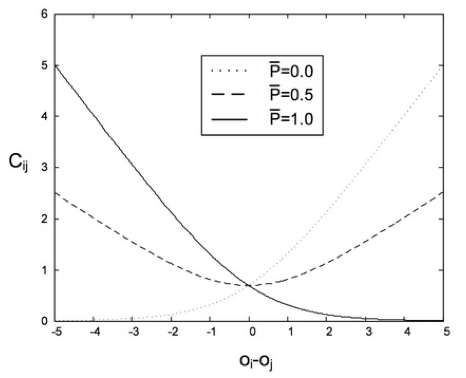
下面我们需要定义损失函数了。首先定义概率Pij,用于表示Xi比Xj排名高的概率,直观上可以设Pij=F(Xi)-F(Xj),这样F(Xi)-F(Xj)越大表示Xi比Xj排名高的概率越大,但这里问题的关键是概率值是在[0,1]区间范围内的,因此需要归一化。可以参考逻辑斯蒂回归的归一化函数:
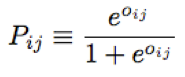
其中Oi=F(i),Oij=F(i)-F(j),这个函数有比较好的特质,当Oij=0时,Pij=0.5,当Oij>0时,Pij>0.5,并且当Oij趋向于无穷大时,Pij=1,反之当Oij<0时,Pij<0.5,当Oij趋向于无穷小时,Pij=0。
这个时候我们就可以定义损失函数了。损失函数常用有两种类型:
1)平方损失函数
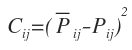
这是最常用的损失函数,但是现在由于已经做了归一化逻辑映射,使得平方损失函数不再是一个凸函数,这给我们最优化求解造成了比较大的挑战,因此实际常常使用另一种损失函数---交叉熵。
2)交叉熵

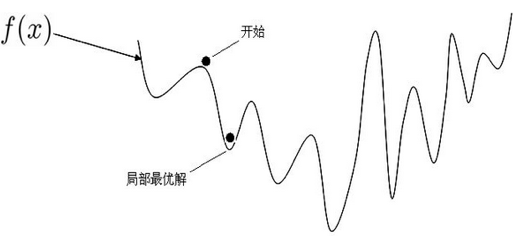
这里插句题外话,为什么非凸函数的最优解不好求?
如下图所示一个非凸函数,要求最小值,我们常使用的梯度下降法或者牛顿迭代法往往限于局部最优解,很难找到全局最优解。
下面看看交叉熵损失函数是否能满足我们的需求。

得到了凸损失函数之后,就可以使用梯度下降方法求解最优化参数。
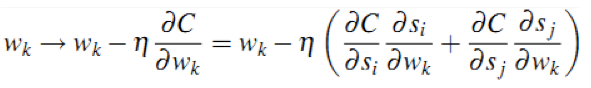
如果直接这么训练最终得到的是线性模型,不能学习特征之间的非线性关系,一般学习非线性关系有几种方法:1)一种是对特征进行高维映射,例如svm的核方法;2)树模型;3)带有隐藏层的神经网络。
3.2 基于神经网络的ranknet
在实际使用中,ranknet采用神经网络方法进行学习,一般采用的是带有隐层的神经网络。学习过程一般使用误差反向传播方法来训练。
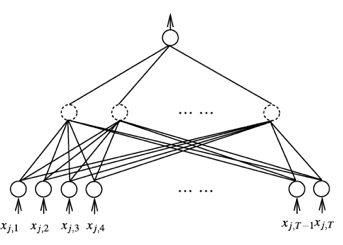
这里的输入层(最底部)的神经元代表了样本的每一个特征,虚线的神经元代表隐藏层,最终输出只有一个神经元。
如何训练呢?这里提供了两种思路:
1)取一个样本对(Xi, Xj),首先对Xi带入神经网络进行前向反馈,其次将Xj带入神经网络进行前向反馈,然后计算差分结果并进行误差反向传播,接着取下一个样本对。。。
这种方法很直观,缺点是收敛速度慢。
2)批量训练。我们可以对同一个排序下的所有文档pair全部带入神经网络进行前向反馈,然后计算总差分并进行误差反向传播,这样将大大减少误差反向传播的次数,原理如下公式推导所示。
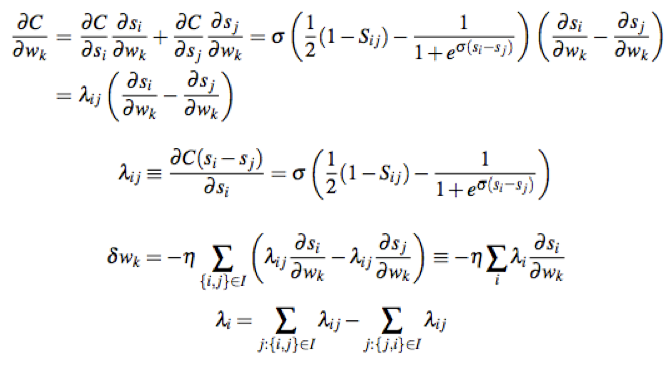
3.3 ranknet代码实现
开源ranknet实现:http://people.cs.umass.edu/~vdang/ranklib.html
3.4 应用
我们输入的样本如下所示:相应的字段为:<target> qid:<qid> <feature>:<value> <feature>:<value> ... <feature>:<value> # <info>。其中target就是label,购买label=7,点击label=3,展示label=1;qid代表一次排序的标识,feature就是特征,#后面是注释信息。
7 qid:1 1:1 2:1 3:0 4:0.2 5:0 # 1A
3 qid:1 1:0 2:0 3:1 4:0.1 5:1 # 1B
1 qid:1 1:0 2:1 3:0 4:0.4 5:0 # 1C
1 qid:1 1:0 2:0 3:1 4:0.3 5:0 # 1D
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2A
3 qid:2 1:1 2:0 3:1 4:0.4 5:0 # 2B
1 qid:2 1:0 2:0 3:1 4:0.1 5:0 # 2C
1 qid:2 1:0 2:0 3:1 4:0.2 5:0 # 2D
1 qid:3 1:0 2:0 3:1 4:0.1 5:1 # 3A
3 qid:3 1:1 2:1 3:0 4:0.3 5:0 # 3B
7 qid:3 1:1 2:0 3:0 4:0.4 5:1 # 3C
1 qid:3 1:0 2:1 3:1 4:0.5 5:0 # 3D
将样本输入到ranknet进行训练,最终得到如下所示结果,其中我们特征为46个,即输入层中神经元个数为46个,隐藏层只设置了1层,隐藏层神经元个数设置为10个。
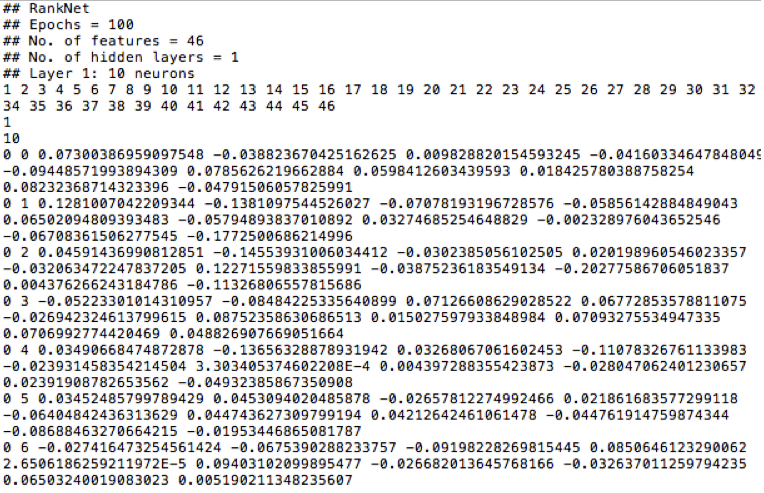
得到模型结果后,将此模型保存到缓存中。假设来一个线上请求,我们首先提取出各个文档的特征向量(V1, V2, V3, ..., Vn),带入此神经网络模型得到各个文档的评分,并按照评分进行排序。
4 小结
本文对排序学习做了一个简单的介绍,并着重介绍了ranknet的原理以及应用,后面会对其他pair wise方法、list wise方法做一些探讨。
排序学习实践---ranknet方法的更多相关文章
- 排序学习(learning to rank)中的ranknet pytorch简单实现
一.理论部分 理论部分网上有许多,自己也简单的整理了一份,这几天会贴在这里,先把代码贴出,后续会优化一些写法,这里将训练数据写成dataset,dataloader样式. 排序学习所需的训练样本格式如 ...
- 使用sklearn进行集成学习——实践
系列 <使用sklearn进行集成学习——理论> <使用sklearn进行集成学习——实践> 目录 1 Random Forest和Gradient Tree Boosting ...
- 个性化排序算法实践(五)——DCN算法
wide&deep在个性化排序算法中是影响力比较大的工作了.wide部分是手动特征交叉(负责memorization),deep部分利用mlp来实现高阶特征交叉(负责generalizatio ...
- 个性化排序算法实践(三)——deepFM算法
FM通过对于每一位特征的隐变量内积来提取特征组合,最后的结果也不错,虽然理论上FM可以对高阶特征组合进行建模,但实际上因为计算复杂度原因,一般都只用到了二阶特征组合.对于高阶特征组合来说,我们很自然想 ...
- 前端学习实践笔记--JavaScript深入【1】
这一年中零零散散看过几本javascript的书,回过头看之前写过的javascript学习笔记,未免有点汗颜,突出“肤浅”二字,然越深入越觉得javascript的博大精深,有种只缘身在此山中的感觉 ...
- ReactNative学习实践--Navigator实践
离上次写RN笔记有一段时间了,期间参与了一个新项目,只在最近的空余时间继续学习实践,因此进度比较缓慢,不过这并不代表没有新进展,其实这个小东西离上次发文时已经有了相当大的变化了,其中影响最大的变化就是 ...
- ReactNative学习实践--动画初探之加载动画
学习和实践react已经有一段时间了,在经历了从最初的彷徨到解决痛点时的兴奋,再到不断实践后遭遇问题时的苦闷,确实被这一种新的思维方式和开发模式所折服,react不是万能的,在很多场景下滥用反而会适得 ...
- 深度学习实践系列(2)- 搭建notMNIST的深度神经网络
如果你希望系统性的了解神经网络,请参考零基础入门深度学习系列,下面我会粗略的介绍一下本文中实现神经网络需要了解的知识. 什么是深度神经网络? 神经网络包含三层:输入层(X).隐藏层和输出层:f(x) ...
- 【前端,干货】react and redux教程学习实践(二)。
前言 这篇博文接 [前端]react and redux教程学习实践,浅显易懂的实践学习方法. ,上一篇简略的做了一个redux的初级demo,今天深入的学习了一些新的.有用的,可以在生产项目中使用的 ...
随机推荐
- 4.镜像管理【Docker每天5分钟】
Docker给PaaS世界带来的“降维打击”,其实是提供了一种非常便利的打包机制.该机制打包了应用运行所需要的整个操作系统,从而保证了本地环境和云端环境的高度一致,避免了用户通过“试错”来匹配不同运行 ...
- 痞子衡嵌入式:语音处理工具Jays-PySPEECH诞生记(3)- 音频显示实现(Matplotlib, NumPy1.15.0)
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是语音处理工具Jays-PySPEECH诞生之音频显示实现. 音频显示是Jays-PySPEECH的主要功能,Jays-PySPEECH借 ...
- 用TensorFlow教你手写字识别
博主原文链接:用TensorFlow教你做手写字识别(准确率94.09%) 如需转载,请备注出处及链接,谢谢. 2012 年,Alex Krizhevsky, Geoff Hinton, and Il ...
- 算法工程师想进一步提高竞争力?向TensorFlow开源社区贡献你的代码吧
算法工程师为什么也要向社区贡献代码? [作者:DeepLearningStack,阿里巴巴算法工程师,开源TensorFlow Contributor] “做算法的人要熟悉算法框架源码吗?算法工程师难 ...
- demo_3
## 控制器层 需求分析: 访问路径:`/user/reg.do`请求参数:`username=xx&password=xx&&phone=xx&email=xx`请求 ...
- Java 由浅入深GUI编程实战练习(三)
一,項目介紹 1.可以查看年,月,日等功能.能获取今天的日期,并且能够通过下拉年,月的列表. 2.当程序运行时,显示的时间是系统当前时间. 3.可以手动输入时间,确定后系统跳转到制定的时间. 4.提供 ...
- 使用python操作XML增删改查
使用python操作XML增删改查 什么是XML? XML 指可扩展标记语言(EXtensible Markup Language) XML 是一种标记语言,很类似 HTML XML 的设计宗旨是传输 ...
- 总结:BGP和静态路由并存,达到故障自动倒换的目的。
总体结论: 在上云的场景中,客户需要本地数据中心到云上VPC,出现网络故障时做到自动倒换,保证业务不中断. 一.客户需求 1.客户有总厂.分厂.总厂是通过专线和VPN连接上云,分厂是通过专线先连接到总 ...
- iOS----------取数据的两种取法
NSMutableArray * dataArray =[responseDictionary valueForKeyPath:@"data.list_dic.list"]; NS ...
- 操作系统:修改VirtualBox for Mac的虚拟硬盘大小
我安装的是Mac版的VirtualBox,不能从GUI上修改硬盘大小,但是实在是大小不够用了. 百度后得知,可以用命令行修改. 1.打开终端,输入sudo su,取得管理员权限 $ sudo su P ...