HashMap源码(一)
本文主要是从学习的角度看HashMap源码
HashMap的数据结构
- HashMap是一个数组+链表的结构(链表散列),每个节点在HashMap中以一个Node存在;
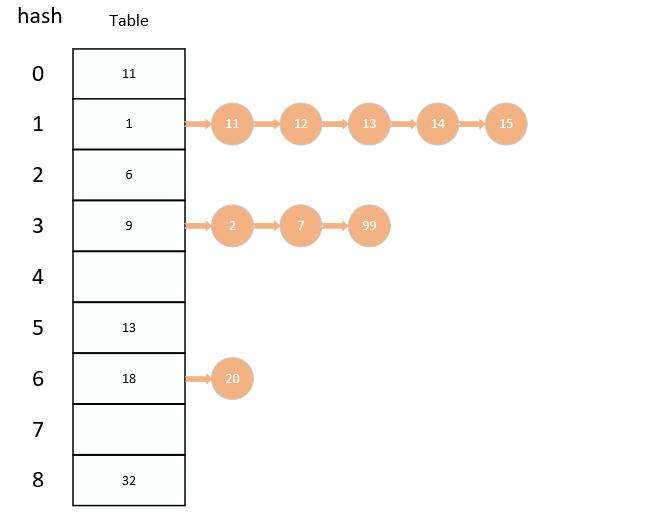
HashMap的初始化
public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
// 这里的MAXIMUM_CAPACITY=1 << 30(问题一: 为什么是30?)
if (initialCapacity > MAXIMUM_CAPACITY)
// 如果传入初始值大于1<<30 则默认值为最大;
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
// 这里是根据传入的初始值算得 大于输入参数且最近的2的整数次幂的数
this.threshold = tableSizeFor(initialCapacity);
}
HashMap中初始化方法如上。
- initialCapacity参数为初始化大小的值,默认为16,问题二:这里为什么为16?;
- loadFactor参数我理解为扩容权重比,默认值为0.75,问题三:这里为什么是0.75?,就是当HashMap的容量达到HashMap的数组长度*loadFactor时就会进行扩容。也就是HashMap中的 resize 方法
初始化方法代码不多,此处为了效率运用了很多的位运算;
首先: 为什么HashMap的容量永远是2的整数倍?
- 首先我们可以看源码知道HashMap中元素的位置计算是 hash & (n- 1),为啥要这么算我也不知道,反正这样的算法下 如果hashmap的长度刚好是2的倍数那么元素的分布相对来说是比较均匀的。减少元素碰撞的几率; 具体详细的可以看下这篇博文
- 所以这也解释了问题二的初始值为16即2的四次方;至于为啥一定是16,我也不知道,可能我比较杠精;
- 更新(12-11 ): 此处为什么是16在关于这个默认容量的选择,JDK并没有给出官方解释,我也没有在网上找到关于这个任何有价值的资料。(如果哪位有相关的权威资料或者想法,可以留言交流)
- 更新(12-23):详见问题二
问题一:MAXIMUM_CAPACITY = 1 << 30
- 首先这个值符合上面的原则,即大小为2的整数倍;而1<<30这个值我们可以尝试发现:
System.out.println(1<<30); // 1073741824
System.out.println(1<<31); // -2147483648
System.out.println(1<<32); // 1
- 因为int类型是32位整型,1左移31位的为 16进制的0x80000000代表的是-2147483648, 所以最大值只能为1>>30;至于为什么初始值不用Integer.MAX_VALUE,其实在resize方法中有下面这段代码:
if (oldCap >= MAXIMUM_CAPACITY) {
//若数组长度大于1>>30,这里则扩容Integer.MAX_VALUE;
threshold = Integer.MAX_VALUE;
return oldTab;
}
问题二:initialCapacity初始值为16
因为在使用是2的幂的数字的时候,Length-1的值是所有二进制位全为1,这种情况下,index的结果等同于HashCode后几位的值。
只要输入的HashCode本身分布均匀,Hash算法的结果就是均匀的。
这是为了实现均匀分布。
问题三: loadFactor默认值0.75
JDK 1.7中:
As a general rule, the default load factor (.75) offers a good tradeoff between time and space costs. Higher values decrease the space overhead but increase the lookup cost (reflected in most of the operations of the HashMap class, including get and put). The expected number of entries in the map and its load factor should be taken into account when setting its initial capacity, so as to minimize the number of rehash operations. If the initial capacity is greater than the maximum number of entries divided by the load factor, no rehash operations will ever occur.
翻译过来就是:
作为一般规则,默认负载因子(0.75)在时间和空间成本上提供了很好的折衷。较高的值会降低空间开销,但提高查找成本(体现在大多数的HashMap类的操作,包括get和put)。设置初始大小时,应该考虑预计的entry数在map及其负载系数,并且尽量减少rehash操作的次数。如果初始容量大于最大条目数除以负载因子,rehash操作将不会发生。理想状态下,在随机哈希值的情况,对于loadfactor = 0.75 ,虽然由于粒度调整会产生较大的方差,桶中的Node的分布频率服从参数为0.5的泊松分布。
接下来我们会具体看下HashMap的resize方法
博文推荐:https://www.hollischuang.com/archives/4320 (掘金看见的,写的很好)
HashMap源码(一)的更多相关文章
- HashMap 源码解析
HashMap简介: HashMap在日常的开发中应用的非常之广泛,它是基于Hash表,实现了Map接口,以键值对(key-value)形式进行数据存储,HashMap在数据结构上使用的是数组+链表. ...
- HashMap源码分析
最近一直特别忙,好不容易闲下来了.准备把HashMap的知识总结一下,很久以前看过HashMap源码.一直想把集合类的知识都总结一下,加深自己的基础.我觉的java的集合类特别重要,能够深刻理解和应用 ...
- JAVA源码分析-HashMap源码分析(一)
一直以来,HashMap就是Java面试过程中的常客,不管是刚毕业的,还是工作了好多年的同学,在Java面试过程中,经常会被问到HashMap相关的一些问题,而且每次面试都被问到一些自己平时没有注意的 ...
- Java集合---HashMap源码剖析
一.HashMap概述二.HashMap的数据结构三.HashMap源码分析 1.关键属性 2.构造方法 3.存储数据 4.调整大小 5.数据读取 ...
- 【转】Java HashMap 源码解析(好文章)
.fluid-width-video-wrapper { width: 100%; position: relative; padding: 0; } .fluid-width-video-wra ...
- 【JAVA集合】HashMap源码分析(转载)
原文出处:http://www.cnblogs.com/chenpi/p/5280304.html 以下内容基于jdk1.7.0_79源码: 什么是HashMap 基于哈希表的一个Map接口实现,存储 ...
- HashMap源码解读(转)
http://www.360doc.com/content/10/1214/22/573136_78188909.shtml 最近朋友推荐的一个很好的工作,又是面了2轮没通过,已经是好几次朋友内推没过 ...
- HashMap源码剖析
HashMap源码剖析 无论是在平时的练习还是项目当中,HashMap用的是非常的广,真可谓无处不在.平时用的时候只知道HashMap是用来存储键值对的,却不知道它的底层是如何实现的. 一.HashM ...
- Java中HashMap源码分析
一.HashMap概述 HashMap基于哈希表的Map接口的实现.此实现提供所有可选的映射操作,并允许使用null值和null键.(除了不同步和允许使用null之外,HashMap类与Hashtab ...
- 转:【Java集合源码剖析】HashMap源码剖析
转载请注明出处:http://blog.csdn.net/ns_code/article/details/36034955 您好,我正在参加CSDN博文大赛,如果您喜欢我的文章,希望您能帮我投一票 ...
随机推荐
- 何时使用异步或同步AJAX
通常最好使用异步调用 通过优锐课核心java学习笔记中,我们可以看到,码了很多专业的相关知识, 分享给大家参考学习. AJAX代表异步JavaScript和XML,是一项允许异步更新网页的技术,这意味 ...
- [菜b]Isaunoya 的一些学习笔记…[保持咕咕咕]
fread/fwrite标记永久化 分块 树链剖分 莫比乌斯反演 斜率优化/单调队列 kruskal重构树 回滚莫队 可持久化线段树/trie树 Link-Cut-Tree dsu on tree F ...
- lucas定理及其拓展的推导
lucas定理及其拓展的推导 我的前一篇博客-- lucas定理 https://mp.csdn.net/mdeditor/100550317#主要是给出了lucas的结论和模板,不涉及推导. 本篇文 ...
- MATLAB代码v2.0
% % V 原始评价指标矩 % % v_ij 第i个地区第j个指标的初始值 % % r_ij 第i个地区第j个指标的标准化值 % % R 标准化后的评价矩阵 % % m 统计地区总个数 % % n 已 ...
- TTradmin v2.1 【2019年12月12日更新】简单好用的临时远程协助软件
TTradmin 是一款免端口映射可直接穿透任何内网,基于VNC核心的即时远程协助软件.在使用的时候只需要保证“协助端”和“被协助端”使用同一个验证码即可实现安全便捷的远程控制,不需要进入路由 ...
- RS323串口连接仪器,接收仪器信息
SerialPort sp1 = new SerialPort(); getBloodPressur(); public void getBloodPressur() { try { string[] ...
- python3-cookbook笔记:第三章 数字日期和时间
python3-cookbook中每个小节以问题.解决方案和讨论三个部分探讨了Python3在某类问题中的最优解决方式,或者说是探讨Python3本身的数据结构.函数.类等特性在某类问题上如何更好地使 ...
- Java数列循环左移
描述 有n个整数组成一个数组(数列).现使数列中各数顺序依次向左移动k个位置,移出的数再从尾部移入.输出移动后的数列元素. 题目没有告诉你n的范围,要求不要提前定义数组的大小. 另外要求定义并使用函数 ...
- sql注入常见绕过技巧
参考链接:https://blog.csdn.net/huanghelouzi/article/details/82995313 https://www.cnblogs.com/vincy99/p/9 ...
- c#在类里不能使用Response解决方法
response对应的类是HttpResponse, 在System.Web 命名字间里, 如果你在类中要使用 Response 的话, 需要使用System.Web.HttpConte ...