0010 基于DRF框架开发(03 模型序列化器)
序列化器:是指从数据库提取数据,转化前端所需要的数据格式并返回到前端。
反序列化器:是指把前端传回的数据,转换成数据库需要的格式,存入数据库。
DRF提供了两种序列化器:
模型序列化器:是指和模型关联的序列化器,需要引入模型来定义序列化器。
普通序列化器:是指和模型无关的序列化器,和模型无关,只是一个序列化器。
本节主要介绍模型序列化器
1 创建模型序列化器
在Applications/Examples/views下创建文件,名为:Schools.py
from rest_framework import serializers
from Applications.Examples.models import Schools
from rest_framework.viewsets import ModelViewSet
import re class SchoolsSerializer(serializers.ModelSerializer):
"""
【功能描述】模型序列化器,主要针对模型生成的序列化器。
1 临时字段
模型序列化器中可定义临时字段,用于上传用户数据,或下发从其它模型或内存中的数据。
如果上传临时字段,则设置为write_only=True
如果下发临时字段,则设置为read_only=True
2 重新定义模型字段
对于模型中已存在的字段,可以在此重新定义约束。如:手机号,座机号,可以用正则表达式来定义。
"""
# 手机验证码是用于前端上传的,而不需要后端下发,故定义write_only=True
sms_code = serializers.CharField(min_length=6, max_length=6, write_only=True, help_text='手机验证码') class Meta:
"""
【功能描述】
1 指定模型名
2 指定需要上传或下载的模型字段名
如果所有字段全部选择,则使用fields = '__all__'
如果手工指定字段,则用元组列出要指定的字段名
"""
model = Schools
fields = ('id', 'name', 'email', 'phone', 'employment_rate', 'sms_code', 'teacher_quantity', 'student_quantity')
extra_kwargs = {
'id': {
'read_only': True, # 用户ID是只读的,故只能读取不能填写
'help_text': '学校ID'
},
'name': {
'help_text': '学校名',
'min_length': 2,
'max_length': 10,
'error_messages': {
'min_length': '用户名不能少于两个中文字符',
'max_length': '用户名不能大于20个中文字符',
},
},
'employment_rate': {
'help_text': '就业率(%)',
} } @classmethod
def validate_phone(cls, value):
"""
【功能描述】用于验证某个字段,则用'validate_'+字段名来命名函数,validate_<field_name>
"""
if not re.match(r'\(?0\d{2,3}[)-]?\d{7,8}', value): # 正则表达式匹配座机号
raise serializers.ValidationError('不是有效的座机号')
return value @classmethod
def validate_employment_rate(cls, value):
"""
【功能描述】用于验证某个字段,则用'validate_'+字段名来命名函数,validate_<field_name>
"""
if value > 100:
raise serializers.ValidationError('就业率不能超过100%')
if value < 0:
raise serializers.ValidationError('就业率不能小于0%')
return value @classmethod
def validate_sms_code(cls, value):
"""
【功能描述】用于处理接收的临时字段,比如验证码是否过期等操作。验证完后,在保存前要删除临时字段。
"""
return value @classmethod
def validate(cls, attrs):
"""
【功能描述】用于同时验证多个字段
"""
if attrs['teacher_quantity'] <= 0:
raise serializers.ValidationError('教师人数不能小于等于0')
if attrs['student_quantity'] <= 0:
raise serializers.ValidationError('学生人数不能小于等于0')
if attrs['teacher_quantity'] >= attrs['student_quantity']:
raise serializers.ValidationError('教师人数不能大于等于学生人数')
return attrs def create(self, validated_data):
del validated_data['sms_code'] # 临时字段仅用于上传,保存数据库之前要删除
return Schools.objects.create(**validated_data) def update(self, instance, validated_data):
"""
【功能描述】用于处理只更新部分字段的情况
"""
instance.name = validated_data.get('name')
# Email允许为空,前端可传可不传,如果传了,则修改,如果没传,则维持原数据
if validated_data.get('email'):
instance.email = validated_data.get('email')
instance.phone = validated_data.get('phone')
instance.employment_rate = validated_data.get('employment_rate')
instance.teacher_quantity = validated_data.get('teacher_quantity')
instance.student_quantity = validated_data.get('student_quantity')
instance.save()
return instance class SchoolsViewSet(ModelViewSet):
queryset = Schools.objects.all()
serializer_class = SchoolsSerializer
2 增加视图
class SchoolsViewSet(ModelViewSet):
queryset = Schools.objects.all()
serializer_class = SchoolsSerializer
3 增加路由
在Examples分路由urls.py中增加一个路由:
router.register('Schools', SchoolsViewSet) # 向路由器中注册视图集
4 运行工程,测试自动生成的所有接口。共六个接口,页面如下:
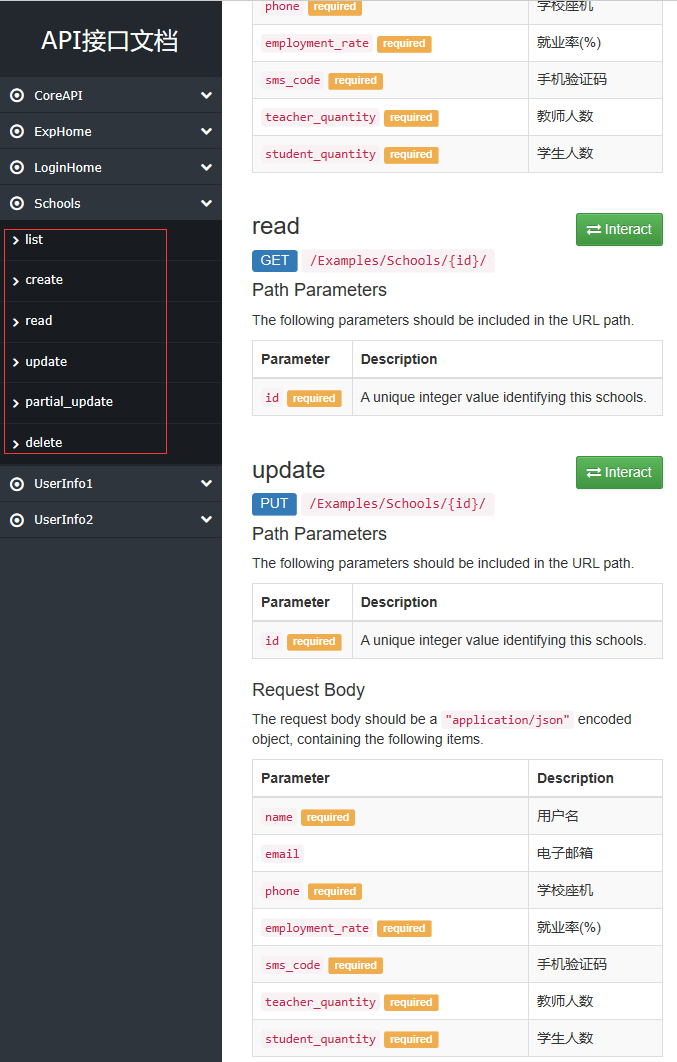
0010 基于DRF框架开发(03 模型序列化器)的更多相关文章
- 0012 基于DRF框架开发(04 序列化器的字段与选项)
1 常用字段类型 字段 构造方式 BooleanField BooleanField() NullBooleanField NullBooleanField() CharField CharField ...
- 0009 基于DRF框架开发(02 创建模型)
上一节介绍了DRF开发的基本流程,共五个步骤: 1 创建模型 2 创建序列化器 3 编写视图 4 配置URL 5 运行测试 本节主要讲解创建模型. 构建学校,教师,学生三个模型,这三个模型之间的关系是 ...
- 0011 基于DRF框架开发(04 普通序列化器)
普通序列化器和模型无关,只是对针对提交字段的定义. 本文定义三个序列化器: 教师序列化器,学生序列化器,教师学生序列化器.这三个序列化器都使用普通序列化器. 1 教师序列化器 在Application ...
- 0013 基于DRF框架开发(01 基类视图 APIView)
之前学习了模型序列化和普通序列化,我们用最简单的视图和url实现了对序列化的操作. 而实际上,象之前那种由DRF自动生成所有的视图和url的情况,在应用是使用很少.而需要用户根据实际业务需求,自定义视 ...
- 0008 基于DRF框架开发(01 DRF开发的基本流程)
1 创建模型 由于之前在<004 工程配置>中,已在Applications/Organizations/models中创建了一个UserInfo模型.此处引用这个模型. from dja ...
- 0014 基于DRF框架开发(02 基类视图 GenericAPIView)
前端于对数据操作的请求基本上就分为四类:增删改查,即增加.删除.修改.查询. 而DRF把前端请求分为两个大类:带ID参数请求和不带ID参数请求. 不带ID参数请求包括:增加.分布多条查询 带ID参数请 ...
- MapReduce教程(一)基于MapReduce框架开发<转>
1 MapReduce编程 1.1 MapReduce简介 MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,用于解决海量数据的计算问题. MapReduce分成了两个部分: ...
- 基于SSH框架开发的《高校大学生选课系统》的质量属性的实现
基于SSH框架开发的<高校大学生选课系统>的质量属性的实现 对于可用性采取的是错误预防战术,即阻止错误演变为故障:在本系统主要体现在以下两个方面:(1)对于学生登录模块,由于初次登陆,学生 ...
- 基于NopCommerce框架开发的微信小程序UrShop
Urshop小程序商城 介绍 UrShop小程序商城 2.0发布啦,发布地址https://gitee.com/urselect/urshop UrShop 根据NopCommerce框架开发的,基于 ...
随机推荐
- One Stage目标检测
在计算机视觉中,目标检测是一个难题.在大型项目中,首先需要先进行目标检测,得到对应类别和坐标后,才进行之后的各种分析.如人脸识别,通常是首先人脸检测,得到人脸的目标框,再对此目标框进行人脸识别.如果该 ...
- Linux访问权限控制及时间同步实践
1.编写脚本/root/bin/checkip.sh,每5分钟检查一次,如果发现通过ssh登录失败 次数超过10次,自动将此远程IP放入Tcp Wrapper的黑名单中予以禁止防问 方式一:脚本+定时 ...
- VMware复制Linux虚拟机后网络配置
1.启动虚拟机,点击我已复制 点击已复制后,VMware将会为重置虚拟机网卡mac地址. 2.修改网卡mac地址 3.ifconfig显示网卡名称与配置不一致处理 Centos6中ifconfig显示 ...
- mysql 支持emoji表情
在mysql插入emoji表情,出现错误: java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x8A' for column ' ...
- Centos 下设置静态ip地址
今天小编遇到了需要设置centos(6.4) 下静态ip地址,下面把详细步骤记录下来. 1> 首先打开这个 vi /etc/sysconfig/network-scripts/ifcfg- ...
- 使用gRPC-Web从浏览器调用.NET gRPC服务
我很高兴宣布通过.NET对gRPC-Web进行实验性支持.gRPC-Web允许从基于浏览器的应用程序(例如JavaScript SPA或Blazor WebAssembly应用程序)调用gRPC. . ...
- SNMP协议交互学习-获取udp的udpindatagrams
MIB的组织结构,如下左图,对于udp来说1.3.6.1.2.1.7,组织如下右图,包括4个标量和1个表格 udp节点在LwIP中的定义如下: ] = { , , , , }; ] = { (stru ...
- 处理异常未知端口 Lsof命令
需要使用的命令: ss -tnl 显示所有tcp已被监听的端口 lsof -i:端口 显示所有打开该端口的进程 工作实例: 某天通过ss -tnl发现有不认识的正在被监听的端口 ? 于是使用lso ...
- rysnc知识梳理
rsync语法: Local: rsync [OPTION...] SRC... [DEST] #<===本地传输数据 Access via remote shell: #<===借助通道 ...
- 优雅地使用 C++ 制作表格:tabulate
作者:HelloGitHub-ChungZH 0x00 介绍 tabulate tabulate 是一个使用 C++ 17 编写的库,它可以制作表格.使用它,把表格对齐.格式化和着色,不在话下!你甚至 ...