Hadoop学习2
练习1 编写Java程序实现以下函数:
1.向HDFS中上传文件
2.从HDFS下载文件到本地
3.显示文件目录
4.移动文件
5.新建文件夹
6.移除文件夹
package cn.itcast.hadoop.hdfs; import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException; import org.apache.commons.compress.utils.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;
import org.junit.Before;
import org.junit.Test; public class temp { static FileSystem fs = null;
/*
* initiation
*/
@Before
public void init() throws IOException{
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://zpfbuaa:9000/");
fs = FileSystem.get(configuration);
}
/*
* upload files
*/
@Test
public void upload() throws IOException{
init(); Path dstPath = new Path("hdfs://zpfbuaa:9000/aa/my.jar"); FSDataOutputStream os = fs.create(dstPath); FileInputStream is = new FileInputStream("/home/hadoop/download/my.jar"); IOUtils.copy(is, os);
}
/*
* upload files to HDFS
*/
@Test
public void upload2() throws IOException{
fs.copyFromLocalFile(new Path("/home/hadoop/download/my.jar"), new Path("hdfs://zpfbuaa:9000/aaa/bbb/ccc/my3.jar"));
}
/*
* download files to local
*/
public void download(){ }
/*
* list the information of files
*/
@Test
public void listfile() throws FileNotFoundException, IllegalArgumentException, IOException{ RemoteIterator<LocatedFileStatus> filesIterator = fs.listFiles(new Path("/"), true); while(filesIterator.hasNext()){
LocatedFileStatus fileStatus = filesIterator.next();
Path path = fileStatus.getPath();
String filename = path.getName();
System.out.println(filename);
} System.out.println("---------------------------------------------"); FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus status : listStatus){
String name = status.getPath().getName();
System.out.println(name + (status.isDirectory()?" is a dir":" is a file"));
}
}
/*
* make a new file
*/
@Test
public void makdir() throws IllegalArgumentException, IOException{
fs.mkdirs(new Path("/aaa/bbb/ccc")); }
/*
* delete a old file
*/ public void rm() throws IllegalArgumentException, IOException{
fs.delete(new Path("/aaa/bbb"), true);
}
public static void main(String[] args) throws Exception {
// TODO Auto-generated method stub
Configuration configuration = new Configuration();
configuration.set("fs.defaultFS", "hdfs://zpfbuaa:9000/");
fs = FileSystem.get(configuration);
FSDataInputStream is = fs.open(new Path("/jdk-7u65-linux-i586.tar.gz")); FileOutputStream os = new FileOutputStream("/home/hadoop/download/my.jar"); IOUtils.copy(is,os);
} }
练习2 编写Java程序实现客户端和服务器端的socket信息交互以及函数调用
LoginServiceImpl.class 服务器实例类
package cn.itcast.hadoop.rpc;
public class LoginServiceImpl implements LoginServiceInterface{
@Override
public String Login(String username, String password) {
return username + " logged in successfully!";
}
}
package cn.itcast.hadoop.rpc;
public interface LoginServiceInterface {
public static final long versionID = 1L;
public String Login(String username,String password);
}
package cn.itcast.hadoop.rpc; import java.io.IOException; import org.apache.hadoop.HadoopIllegalArgumentException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import org.apache.hadoop.ipc.RPC.Server;
import org.apache.hadoop.ipc.RPC.Builder; public class starter { public static void main(String[] args) throws HadoopIllegalArgumentException, IOException { Builder builder = new RPC.Builder(new Configuration()); builder.setBindAddress("zpfbuaa").setPort(10000).setProtocol(LoginServiceInterface.class).setInstance(new LoginServiceImpl()); Server server = builder.build(); } }
LoginController登录类
package cn.itcast.hadoop.rpc; import java.io.IOException;
import java.net.InetSocketAddress; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC; public class LoginController { public static void main(String[] args) throws IOException { LoginServiceInterface proxy = RPC.getProxy(LoginServiceInterface.class, 1L, new InetSocketAddress("zpfbuaa", 10000), new Configuration()); String result = proxy.Login("zpfbuaa", "123456789"); System.out.println(result);
}
}
LoginServiceInterface 接口类
package cn.itcast.hadoop.rpc;
public interface LoginServiceInterface {
public static final long versionID = 1L;
public String Login(String username,String password);
}
需要注意的是:
1.为了进行远程调用的模仿,将LoginServiceImpl.class以及LoginServiceInterface.class接口类和 starter.class类放在虚拟机上。本地放LoginController类以及LoginServiceInterface接口类。
2.首先需要将服务器端的服务启动,上述例子会监听虚拟机的10000端口。
3.容易忽略的地方:版本号versionID. 对于不同的版本拥有不同的版本号。在上述例子中简单的均定义版本号为Long类型 并且为final类型 赋值为1L。
4.jar包的导入以及版本的控制。
5.本地以及服务器端的函数都要实现一样的接口类,但是为了防止调用时版本的不对应,所以在Build实例的时候需要将版本号也就是versionID声明清楚,这样调用的时候可以通过版本号的不同将函数进行区别开。
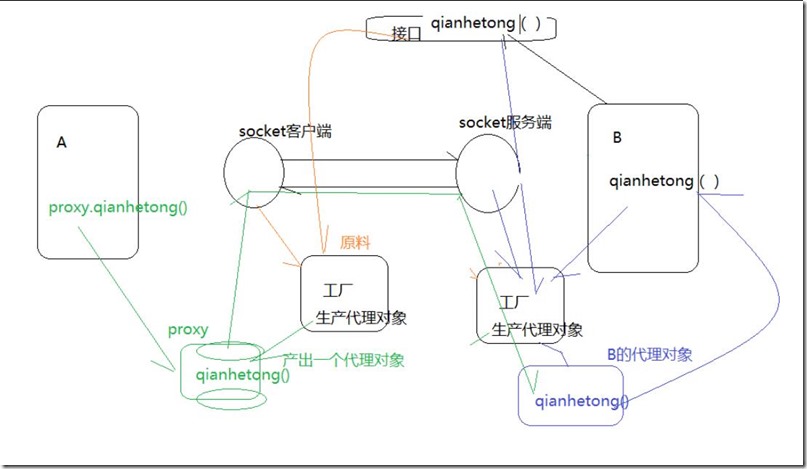
Hadoop自身的远程调用实现机制RPC主要步骤如下:
1.将本地socket以及接口类封装为一个proxy,生成动态本地代理实例。
2.该实例调用相对应的函数并且传入相应的参数。
3.本地socket得到动态代理调用的函数以及传入的参数。
4.使用网络传输协议实现本地socket与远程服务器的socket进行连接,实现信息传递。
5.服务器端socket得到调用的函数以及传入的参数,生成动态服务器端的代理实例。
6.该服务器端实例调用服务器端的函数,并且传入得到的参数。
7.函数调用结果返回给服务器端socket。
8.服务器端socket将返回结果通过网络传输协议传递给本地socket。
9.本地socket将返回结果传递给本地动态代理proxy。
RPC的优点:
1.实现了controller和implement的分离
2.利用RPC机制可以实现信息的有效传递。
3.保障数据的可靠性(DataNode需要定时向NameNode传递自身保存的blocks信息,以便NameNode进行blocks的维护)。
远程调用的底层实现机制: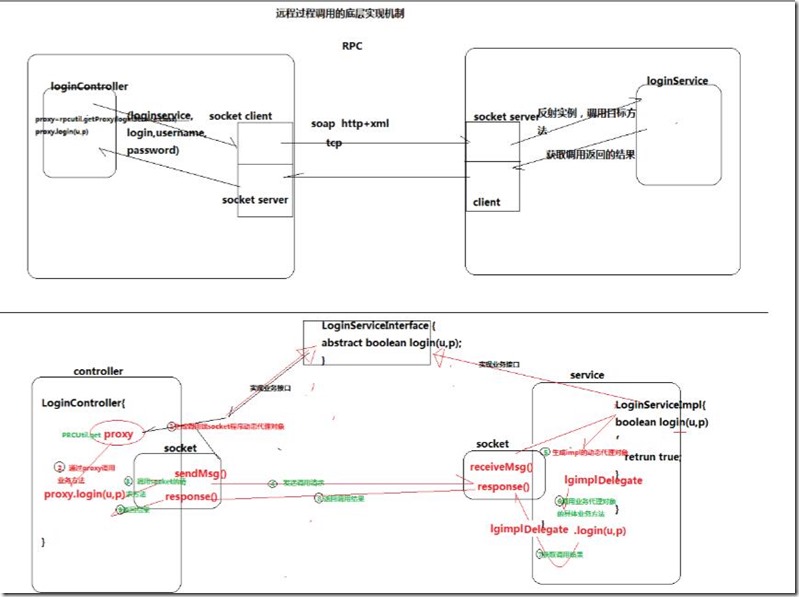
查看FileSystem fs = FileSystem.get(new Configuration());
一步一步查看fs的生成过程!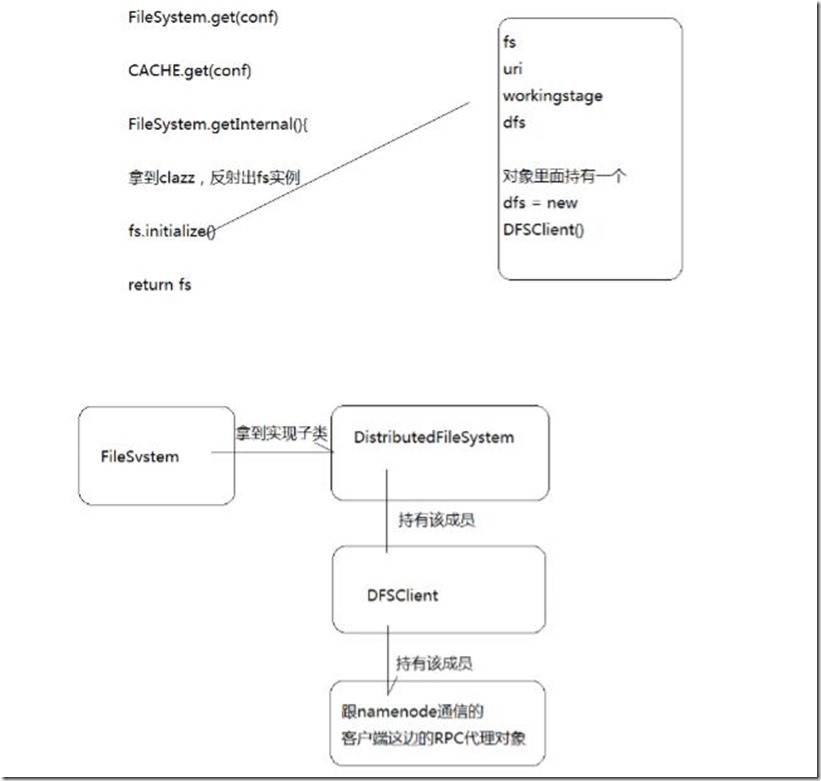
加入断点后,逐步进行查看!
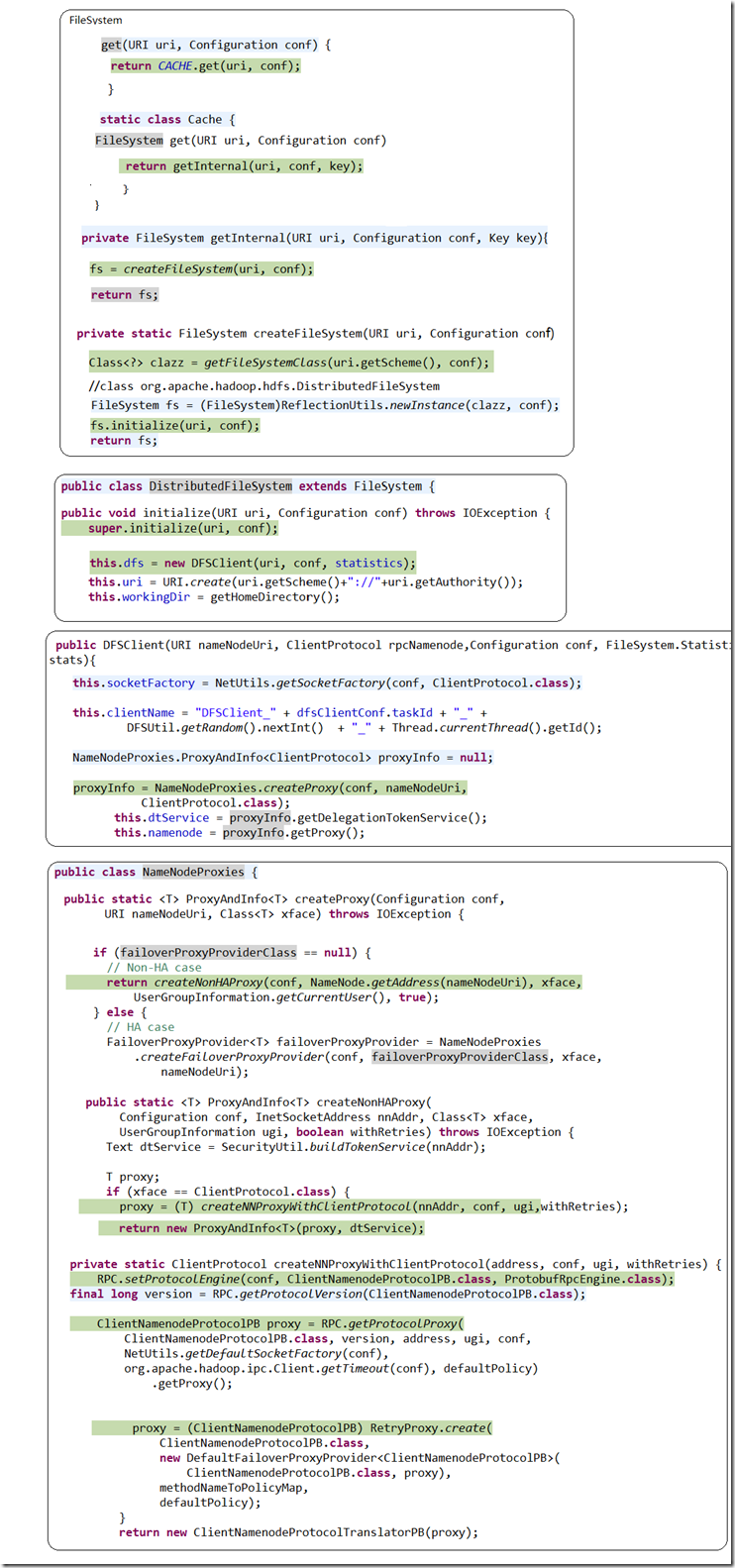
Hadoop学习2的更多相关文章
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop学习路线图
Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括, ...
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
随机推荐
- codefordream 关于js中级训练
中级训练接着就紧锣密鼓的开始了. 首先是关于变量,变量的作用是给一个数据值标注名称. 注:JavaScript中变量名,函数名,参数名的命名规范:至少由字母,下划线,美元符号,数字其中的一种组成,但不 ...
- IDDD 实现领域驱动设计-CQRS(命令查询职责分离)和 EDA(事件驱动架构)
上一篇:<IDDD 实现领域驱动设计-SOA.REST 和六边形架构> 阅读目录: CQRS-命令查询职责分离 EDA-事件驱动架构 Domin Event-领域事件 Long-Runni ...
- jdk8中java.util.concurrent包分析
并发框架分类 1. Executor相关类 Interfaces. Executor is a simple standardized interface for defining custom th ...
- [翻译]利用顶点位移的VR畸变校正
文章英文原网址: http://www.gamasutra.com/blogs/BrianKehrer/20160125/264161/VR_Distortion_Correction_using_V ...
- ZOJ Problem Set - 1006 Do the Untwist
今天在ZOJ上做了道很简单的题目是关于加密解密问题的,此题的关键点就在于求余的逆运算: 比如假设都是正整数 A=(B-C)%D 则 B - C = D*n + A 其中 A < D 移项 B = ...
- C# GZip对字符串压缩和解压
/// <summary> /// 压缩方法 /// </summary> public static string CompressString(string str) { ...
- Visual Studio Code 1.0发布,支持中文在内9种语言
Visual Studio Code 1.0发布,支持中文在内的9种语言:Simplified Chinese, Traditional Chinese, French, German, Italia ...
- C# 发送Http请求 - WebClient类
WebClient位于System.Net命名空间下,通过这个类可以方便的创建Http请求并获取返回内容. 一.用法1 - DownloadData string uri = "http:/ ...
- 解决WebApi入参时多对象的问题
我们的项目是用WebApi提供数据服务,且WebPage跟APP中都有调用到. WebApi提供的接口一多,就发现一个问题,我们项目中有很多接口是接收POST(安全原因,我们采用的是https)请求的 ...
- .net实现与excel的数据交互、导入导出
应该说,一套成熟的基于web的管理系统,与用户做好的excel表格进行数据交互是一个不可或缺的功能,毕竟,一切以方便客(jin)户(qian)为宗旨. 本人之前从事PHP的开发工作,熟悉PHP的都应该 ...