SQL JOIN 的解析
1、SQL语句结构
select distinct < select_list >
from < left_table > < join_type >
join < right_table >
on < join_condition >
where < where_condition >
group by < group_by_list >
having < having_condition >
order by < order_by_condition >
limit < limit_number >
2、7种Join方式及实例
实验脚本:
drop table IF EXISTS shuzi ;
create table shuzi (id tinyint,note varchar(20));
insert into shuzi values (1,'一'),(2,'二'),(3,'三'),(4,'四'),(5,'五'),(6,'六'),(7,'七'),(8,'八'),(9,'九'),(10,'十');
select * from shuzi;
drop table IF EXISTS qianshu ;
create table qianshu (id int,des varchar(20));
insert into qianshu values (1,'壹'),(2,'贰'),(4,'肆'),(5,'伍'),(6,'陆'),(10,'拾'),(100,'佰'),(1000,'仟'),(10000,'万');
select * from qianshu;

- 左连接,左表的全部,右表不满足的列补空
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id order by a.id;

- 右连接,右表的全部,左表不满足的列补空
select a.id,a.note,b.id,b.des from shuzi a right join qianshu b on a.id=b.id order by b.id;
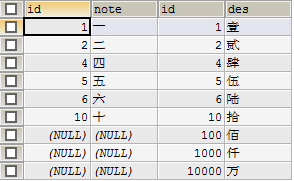
- 内连接,只输出左右表均存在的记录(默认from a,b方式)
SELECT a.id,a.note,b.id,b.des FROM shuzi a INNER JOIN qianshu b ON a.id=b.id ORDER BY b.id;

- 左连接,只保留左表特有数据(差集)
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id where b.id is null order by a.id

- 右连接,只保留右表特有数据(差集)
SELECT a.id,a.note,b.id,b.des FROM shuzi a RIGHT JOIN qianshu b ON a.id=b.id WHERE a.id IS NULL ORDER BY b.id;

- 全外连接,获取左右表的所有记录,各自没有时补空
mysql不支持full outer join,要实现全外连接可以通过合并左,右外连接结果集实现
select a.id,a.note,b.id,b.des from shuzi a left join qianshu b on a.id=b.id
union
select a.id,a.note,b.id,b.des from shuzi a right join qianshu b on a.id=b.id
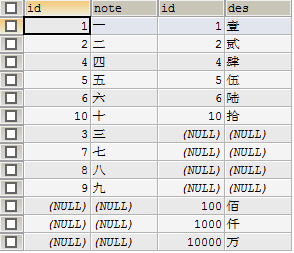
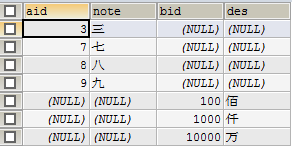
- 获取两表连接交集的补集(最后一个)
SELECT * FROM (
SELECT a.id aid,a.note,b.id bid,b.des FROM shuzi a LEFT JOIN qianshu b ON a.id=b.id
UNION
SELECT a.id aid,a.note,b.id bid,b.des FROM shuzi a RIGHT JOIN qianshu b ON a.id=b.id) v_a
WHERE aid IS NULL OR bid IS NULL;
SQL JOIN
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据。
Join 和 Key
有时为了得到完整的结果,我们需要从两个或更多的表中获取结果。我们就需要执行 join。
数据库中的表可通过键将彼此联系起来。主键(Primary Key)是一个列,在这个列中的每一行的值都是唯一的。在表中,每个主键的值都是唯一的。这样做的目的是在不重复每个表中的所有数据的情况下,把表间的数据交叉捆绑在一起。
请看 "Persons" 表:
| Id_P | LastName | FirstName | Address | City |
|---|---|---|---|---|
| 1 | Adams | John | Oxford Street | London |
| 2 | Bush | George | Fifth Avenue | New York |
| 3 | Carter | Thomas | Changan Street | Beijing |
请注意,"Id_P" 列是 Persons 表中的的主键。这意味着没有两行能够拥有相同的 Id_P。即使两个人的姓名完全相同,Id_P 也可以区分他们。
接下来请看 "Orders" 表:
| Id_O | OrderNo | Id_P |
|---|---|---|
| 1 | 77895 | 3 |
| 2 | 44678 | 3 |
| 3 | 22456 | 1 |
| 4 | 24562 | 1 |
| 5 | 34764 | 65 |
请注意,"Id_O" 列是 Orders 表中的的主键,同时,"Orders" 表中的 "Id_P" 列用于引用 "Persons" 表中的人,而无需使用他们的确切姓名。
请留意,"Id_P" 列把上面的两个表联系了起来。
引用两个表
我们可以通过引用两个表的方式,从两个表中获取数据:
谁订购了产品,并且他们订购了什么产品?
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons, Orders
WHERE Persons.Id_P = Orders.Id_P
结果集:
| LastName | FirstName | OrderNo |
|---|---|---|
| Adams | John | 22456 |
| Adams | John | 24562 |
| Carter | Thomas | 77895 |
| Carter | Thomas | 44678 |
SQL JOIN - 使用 Join
除了上面的方法,我们也可以使用关键词 JOIN 来从两个表中获取数据。
如果我们希望列出所有人的定购,可以使用下面的 SELECT 语句:
SELECT Persons.LastName, Persons.FirstName, Orders.OrderNo
FROM Persons
INNER JOIN Orders
ON Persons.Id_P = Orders.Id_P
ORDER BY Persons.LastName
结果集:
| LastName | FirstName | OrderNo |
|---|---|---|
| Adams | John | 22456 |
| Adams | John | 24562 |
| Carter | Thomas | 77895 |
| Carter | Thomas | 44678 |
不同的 SQL JOIN
除了我们在上面的例子中使用的 INNER JOIN(内连接),我们还可以使用其他几种连接。
下面列出了您可以使用的 JOIN 类型,以及它们之间的差异。
- JOIN: 如果表中有至少一个匹配,则返回行
- LEFT JOIN: 即使右表中没有匹配,也从左表返回所有的行
- RIGHT JOIN: 即使左表中没有匹配,也从右表返回所有的行
- FULL JOIN: 只要其中一个表中存在匹配,就返回行
SQL JOIN 的解析的更多相关文章
- SQL Server 深入解析索引存储(下)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- 大数据技术之_19_Spark学习_03_Spark SQL 应用解析 + Spark SQL 概述、解析 、数据源、实战 + 执行 Spark SQL 查询 + JDBC/ODBC 服务器
第1章 Spark SQL 概述1.1 什么是 Spark SQL1.2 RDD vs DataFrames vs DataSet1.2.1 RDD1.2.2 DataFrame1.2.3 DataS ...
- SQL Server 深入解析索引存储(非聚集索引)
标签:SQL SERVER/MSSQL SERVER/数据库/DBA/索引体系结构/非聚集索引 概述 非聚集索引与聚集索引具有相同的 B 树结构,它们之间的显著差别在于以下两点: 基础表的数据行不按非 ...
- Oracle sql执行计划解析
Oracle sql执行计划解析 https://blog.csdn.net/xybelieve1990/article/details/50562963 Oracle优化器 Oracle的优化器共有 ...
- Spark SQL源码解析(四)Optimization和Physical Planning阶段解析
Spark SQL原理解析前言: Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述 Spark SQL源码解析(二)Antlr4解析Sql并生成树 Spark SQL源码解析(三 ...
- Oracle SQL的硬解析和软解析
我们都知道在Oracle中每条SQL语句在执行之前都需要经过解析,这里面又分为软解析和硬解析.在Oracle中存在两种类型的SQL语句,一类为 DDL语句(数据定义语言),他们是从来不会共享使用的,也 ...
- ORACLE的SQL JOIN方式小结
在ORACLE数据库中,表与表之间的SQL JOIN方式有多种(不仅表与表,还可以表与视图.物化视图等联结),官方的解释如下所示 A join is a query that combines row ...
- SQL JOIN\SQL INNER JOIN 关键字\SQL LEFT JOIN 关键字\SQL RIGHT JOIN 关键字\SQL FULL JOIN 关键字
SQL join 用于根据两个或多个表中的列之间的关系,从这些表中查询数据. Join 和 Key 有时为了得到完整的结果,我们需要从两个或更多的表中获取结果.我们就需要执行 join. 数据库中的表 ...
- 转:画图解释 SQL join 语句
画图解释 SQL join 语句 我认为 Ligaya Turmelle 的关于SQL联合(join)语句的帖子对于新手开发者来说是份很好的材料.SQL 联合语句好像是基于集合的,用韦恩图来解释咋一看 ...
随机推荐
- 使用卷影拷贝提取ntds.dit
一.简介 通常情况下,即使拥有管理员权限,也无法读取域控制器中的C:\Windows\NTDS\ntds.dit文件.使用windows本地卷影拷贝服务,就可以获得该文件的副本. 在活动目录中,所有的 ...
- 痞子衡嵌入式:Ethos-U55,ARM首款面向Cortex-M的microNPU
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是ARM Ethos-U55. ARM 前几天刚发布了 Cortex-M 家族最新一款内核 - Cortex-M55 以及首款面向 Cor ...
- GTMD并查集!
徐州的A我因为并查集写错T了整场.. int find(int x){ return fa[x]==x?x:fa[x]=find(fa[x]); } GTMD!
- 《Python学习手册 第五版》 -第5章 数值类型
本章是承接第四章整体说明之后,将对”数值类型“展开详细的说明 数值类型这一章主要通过一下几个内容来讲解: 1.数值类型有哪些? 2.表达式运算符:有哪些?有什么规范? 3.数值的显示格式 接下来,从第 ...
- python库之matplotlib学习---图无法显示中文
在代码前面加上 plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签 plt.rcParams['axes.unicode_minus'] ...
- 题解 SDOI2010 【栗栗的书架】
\[ Preface \] 看到这题洛谷标签有 主席树 ,还以为是什么二维主席树的玄学做法(雾 \[ Description \] 给出一个 \(R×C\) 的矩阵. 一共 \(m\) 次询问,每次询 ...
- Spark Streaming运行流程及源码解析(一)
本系列主要描述Spark Streaming的运行流程,然后对每个流程的源码分别进行解析 之前总听同事说Spark源码有多么棒,咱也不知道,就是疯狂点头.今天也来撸一下Spark源码. 对Spark的 ...
- python学习(8)实例:写一个简单商城购物车的代码
要求: 1.写一段商城程购物车序的代码2.用列表把商城的商品清单存储下来,存到列表 shopping_mail3.购物车的列表为shopping_cart4.用户首先输入工资金额,判断输入为数字5.用 ...
- Import This - The Zen of Python
The Zen of Python -- by Tim Peters Beautiful is better than ugly.Explicit is better than implicit.Si ...
- [Python]获取字典所有值
方法一:Key Value 直接获取 databases = {1: 'Student', 2: 'School'} for k,v in databases.items(): print(k,v) ...