Person Re-identification 系列论文笔记(五):SVD-net
SVDNet for Pedestrian Retrieval
Sun Y, Zheng L, Deng W, et al. SVDNet for Pedestrian Retrieval[J]. 2017.
a spotlight at ICCV 2017
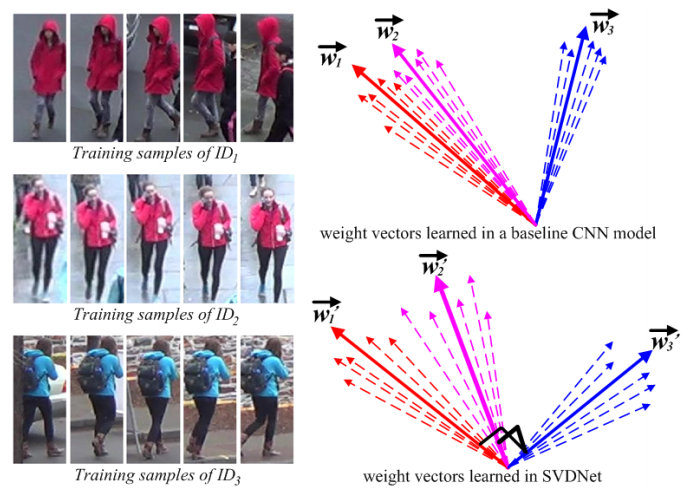
这篇的出发点是全连接层的权值相关性分析,作者认为全连接层的作用可以看做一组向量投影。当权值直接相关性较高时(可以理解为权值冗余),特征差异小,直接导致检索中距离差异小,无法获取差异化的特征。
作者提出用SVD对降维层进行操作,提高权值矩阵的正交性,从而提高检索性能。但整个算法流程中,需要人工操作的地方很多,导致整个流程非常不自然。性能不错,但实际操作起来需要过多的人工干预,倒不如将正交性做成一种正则,添加到训练中。
有兴趣的可以看看这篇论文《All You Need is Beyond a Good Init: Exploring Better Solution for Training Extremely Deep Convolutional Neural Networks with Orthonormality and Modulation》。
contributions
提出对全连接层进行SVD,让权值向量正交化从而减少冗余,提高检索性。
SVD简介
A是m*n的矩阵且rank(A)是k,A的SVD如下:
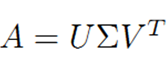
其中,U是m*m的正交阵,U的列向量称为A的左奇异向量,V是n*n的正交阵,V的列向量称为A的右奇异向量, 是m*n的对角阵,对角线上的值称为A的奇异值。
SVD物理意义
借用《数学之美》中的解释,
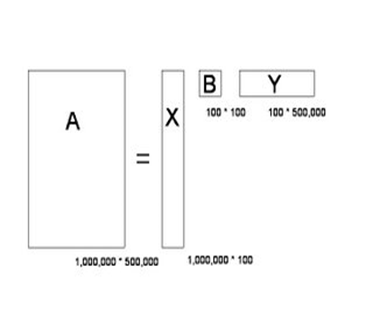
奇异值分解是把一个大矩阵,分解成三个小矩阵相乘。比如把上面的例子中的矩阵分解成一个一百万乘以一百的矩阵X,
一个一百乘以一百的矩阵B,和一个一百乘以五十万的矩阵Y。这三个矩阵的元素总数加起来也不过1.5亿,
仅仅是原来的三千分之一。相应的存储量和计算量都会小三个数量级以上。
三个矩阵物理含义:X中的每一行表示意思相关的一类词,其中的每个非零元素表示这类词中每个词的重要性(或者说相关性),数值越大越相关。
Y中的每一列表示同一主题一类文章,其中每个元素表示这类文章中每篇文章的相关性。中间的矩阵则表示类词和文章类之间的相关性。
因此,我们只要对关联矩阵A进行一次奇异值分解,w 我们就可以同时完成了近义词分类和文章的分类。(同时得到每类文章和每类词的相关性)。
SVD-net pipeline
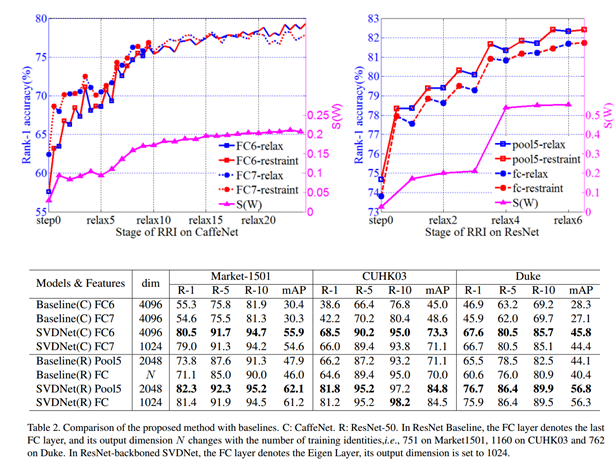
将倒数第二个FC层(如果是最后一个FC会出现不收敛,有可能是最后一层FC是由样本分布决定)进行SVD,且bias设置为0(bias会破坏正交性),测试特征用输入前的特征会更好一点(经过测试得到的结论)。

RRI训练步骤:

相关性指标S(W)

experiments
Person Re-identification 系列论文笔记(五):SVD-net的更多相关文章
- Person Re-identification 系列论文笔记(一):Scalable Person Re-identification: A Benchmark
打算整理一个关于Person Re-identification的系列论文笔记,主要记录近年CNN快速发展中的部分有亮点和借鉴意义的论文. 论文笔记流程采用contributions->algo ...
- Person Re-identification 系列论文笔记(二):A Discriminatively Learned CNN Embedding for Person Re-identification
A Discriminatively Learned CNN Embedding for Person Re-identification Zheng Z, Zheng L, Yang Y. A Di ...
- Person Re-identification 系列论文笔记(三):Improving Person Re-identification by Attribute and Identity Learning
Improving Person Re-identification by Attribute and Identity Learning Lin Y, Zheng L, Zheng Z, et al ...
- Person Re-identification 系列论文笔记(八):SPReID
Human Semantic Parsing for Person Re-identification Kalayeh M M, Basaran E, Gokmen M, et al. Human S ...
- Person Re-identification 系列论文笔记(六):AlignedReID
AlignedReID Zhang X, Luo H, Fan X, et al. AlignedReID: Surpassing Human-Level Performance in Person ...
- Person Re-identification 系列论文笔记(七):PCB+RPP
Beyond Part Models: Person Retrieval with Refined Part Pooling Sun Y, Zheng L, Yang Y, et al. Beyond ...
- Person Re-identification 系列论文笔记(四):Re-ID done right: towards good practices for person re-identification
Re-ID done right: towards good practices for person re-identification Almazan J, Gajic B, Murray N, ...
- 论文笔记系列-Neural Network Search :A Survey
论文笔记系列-Neural Network Search :A Survey 论文 笔记 NAS automl survey review reinforcement learning Bayesia ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
随机推荐
- CString转const char
CString转换成const char 需要考虑一个因素: 你使用是否为unicode 不使用unicode: CString Cstr("aaaaaaa"); co ...
- Django项目:CRM(客户关系管理系统)--34--26PerfectCRM实现King_admin自定义排序
ordering = ['-qq'] #自定义排序,默认'-id' #base_admin.py # ————————24PerfectCRM实现King_admin自定义操作数据———————— f ...
- Linux字体美化实战(Fontconfig配置)(转)
原文地址:http://www.jinbuguo.com/gui/linux_fontconfig.html 本文的主题是Linux环境下的字体美化,但是首先得要有字体,然后才能谈美化.所以第一件事就 ...
- SOFARPC学习(一)
接触SOFARPC,是从一个好朋友(女程序媛)的推荐开始,目的是从头到尾了解这个框架,包括使用方法和源码解析. 当学习一个新东西的事物,我总喜欢先总体把握,在深入细节,这样就可以有种高屋建瓴的感觉,否 ...
- jeecms之全文检索
需要在后台生成检索,如下: . 这样,在首页进行搜索的时候才会显示如下: 注意,一定要先生成索引,才能进行全文检索.
- css 始终让图片占满自适应盒子(图片不失真)
要去上班了,时间比较紧,先把代码粘出来,原理慢慢讲 我来了,今天是农历七月八日,昨天是七夕,不知道为什么,突然通知放假半天(嘎嘎),好吧,没什么!!!走到半路的我看到通知,立马撤了.正好回来把这个原理 ...
- jnhs中国的省市县区邮编坐标mysql数据表
https://blog.csdn.net/sln2432713617/article/details/79412896 -- 1.之前项目中需要全国的省市区数据,在网上找了很多,发现数据要么不全,要 ...
- HTML:如何将网页分为上下两个部分
1.使用table: <table> <tr> <td height="80%"><jsp:include page=" ...
- Twitter web information
http://developer.51cto.com/art/201307/404612.htm 150M active users 300K Qps (read, only 6000 write/s ...
- 前后端分离后API交互如何保证数据安全性
前后端分离后API交互如何保证数据安全性? 一.前言 前后端分离的开发方式,我们以接口为标准来进行推动,定义好接口,各自开发自己的功能,最后进行联调整合.无论是开发原生的APP还是webapp还是PC ...