Eureka单机高可用伪集群配置
Eureka Server高可用集群
理论上来讲,因为服务消费者本地缓存了服务提供者的地址,即使Eureka Server宕机,也不会影响服务之间的调用,但是一旦新服务上线,已经缓存在本地的服务提供者不可用了,服务消费者也无法知道,所以保证Eureka Server的高可用还是很有必要的。
在分布式系统中,任何的地方存在单点,整个体系就不是高可用的,Eureka 也一样,Eureka Server不是以单点存在的,而是以集群的方式对外提供服务。
模拟在一台机器上搭建Eureka集群,配置peer1、peer2、peer3三个节点组成Eureka的集群。
1、配置域名解析
Hosts文件打开方法:打开windows命令窗口,输入“drivers”,选择“etc”文件夹,选择“hosts”文件添加peer配置。
2、新建 Eureka 服务端集群项目
a、pom.xml
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion>
<parent>
<groupId>com.mimaxueyuan</groupId>
<artifactId>mima-cloud-parent</artifactId>
<version>0.0.-SNAPSHOT</version>
</parent>
<artifactId>mima-cloud-eureka-ha</artifactId>
<packaging>jar</packaging> <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- <dependency> -->
<!-- <groupId>org.springframework.boot</groupId> -->
<!-- <artifactId>spring-boot-starter-security</artifactId> -->
<!-- </dependency> -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka-server</artifactId>
</dependency>
</dependencies>
</project>
b、application.yml
spring:
application:
name: mima-cloud-eureka-ha
profiles:
active: peer1
---
server:
port: 8762
spring:
profiles: peer1
eureka:
instance:
hostname: peer1
prefer-ip-address: true
instance-id: ${spring.application.name}:${server.port}
client:
serviceUrl:
defaultZone: http://peer2:8763/eureka/,http://peer3:8764/eureka/
---
server:
port: 8763
spring:
profiles: peer2
eureka:
instance:
hostname: peer2
prefer-ip-address: true
instance-id: ${spring.application.name}:${server.port}
client:
serviceUrl:
defaultZone: http://peer1:8762/eureka/,http://peer3:8764/eureka/
---
server:
port: 8764
spring:
profiles: peer3
eureka:
instance:
hostname: peer3
prefer-ip-address: true
instance-id: ${spring.application.name}:${server.port}
client:
serviceUrl:
defaultZone: http://peer1:8762/eureka/,http://peer2:8763/eureka
配置文件是通过三个Eureka Server互相注册,这里有四段配置,第一段配置为公共配置,配置了应用名称,第二段为名peer1的配置,第三段为peer2的配置,第三段为peer3的配置。在项目启动可以通过
--spring.profiles.active={配置名称} 来启动不同的配置。
c、Eureka服务端启动类
package com.mimaxueyuan.cloud.eureka; import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.cloud.netflix.eureka.server.EnableEurekaServer; //eureka高可用
@SpringBootApplication
@EnableEurekaServer
public class EurekaHAApplication { public static void main(String[] args) {
new SpringApplicationBuilder(EurekaHAApplication.class).web(true).run(args);
} }
3、eureka客户端修改eureka服务端的地址
eureka:
instance:
prefer-ip-address: true
instance-id: ${spring.application.name}:${spring.cloud.client.ipAddress}:${server.port}
client:
serviceUrl:
defaultZone: http://peer1:8762/eureka/,http://peer2:8763/eureka/,http://peer3:8764/eureka/
#defaultZone: http://127.0.0.1:8762/eureka/,http://127.0.0.1:8763/eureka/,http://127.0.0.1:8764/eureka/
4、启动eurekaClient客户端
5、启动eurekaServer服务端
因使用eureka集群,启动的时候需要指定配置文件:
启动peer1节点命令:
java -jar D:\jar\eurekaServer\eurekaServerHigh.jar--spring.profiles.active=peer1
启动peer2节点命令:
java -jar D:\jar\eurekaServer\eurekaServerHigh.jar--spring.profiles.active=peer2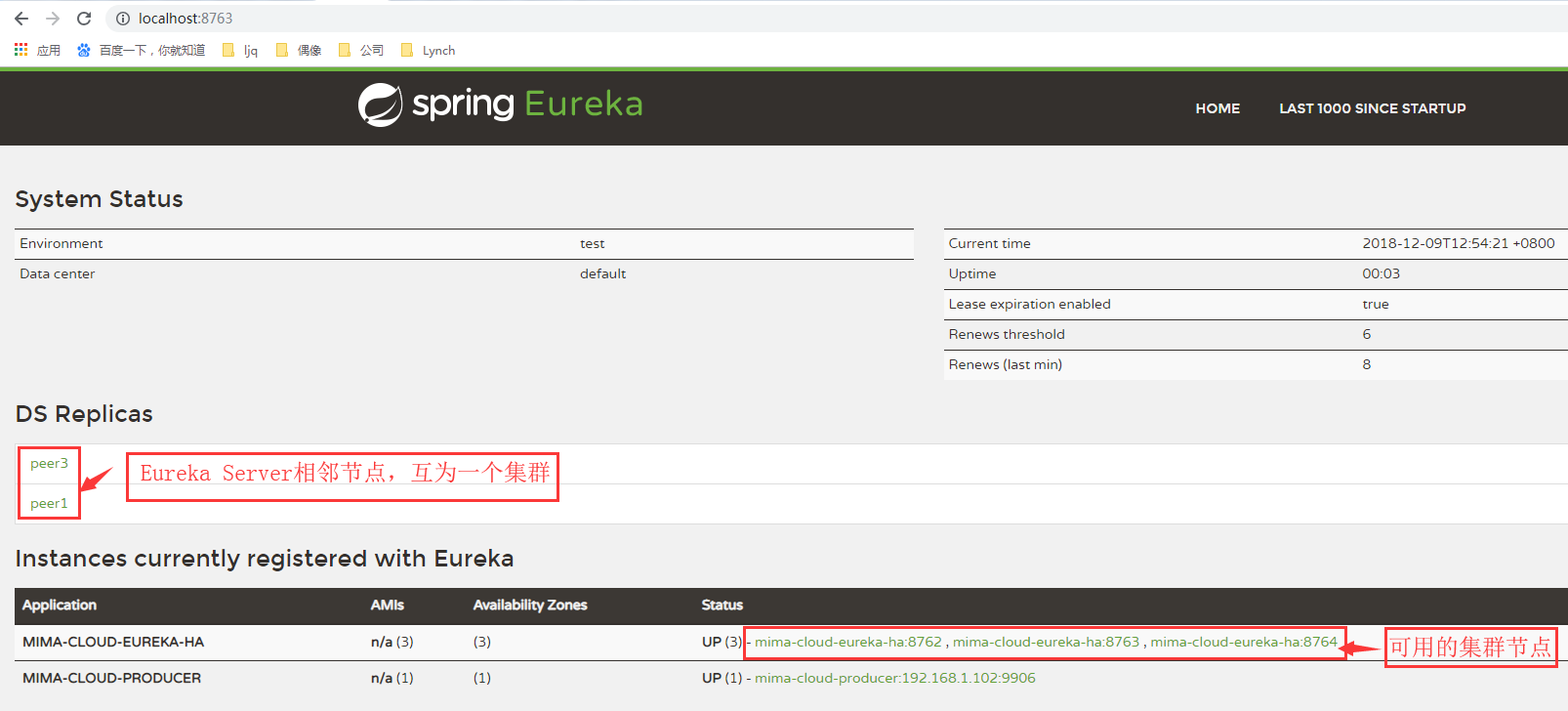
启动peer3节点命令:
java -jar D:\jar\eurekaServer\eurekaServerHigh.jar--spring.profiles.active=peer3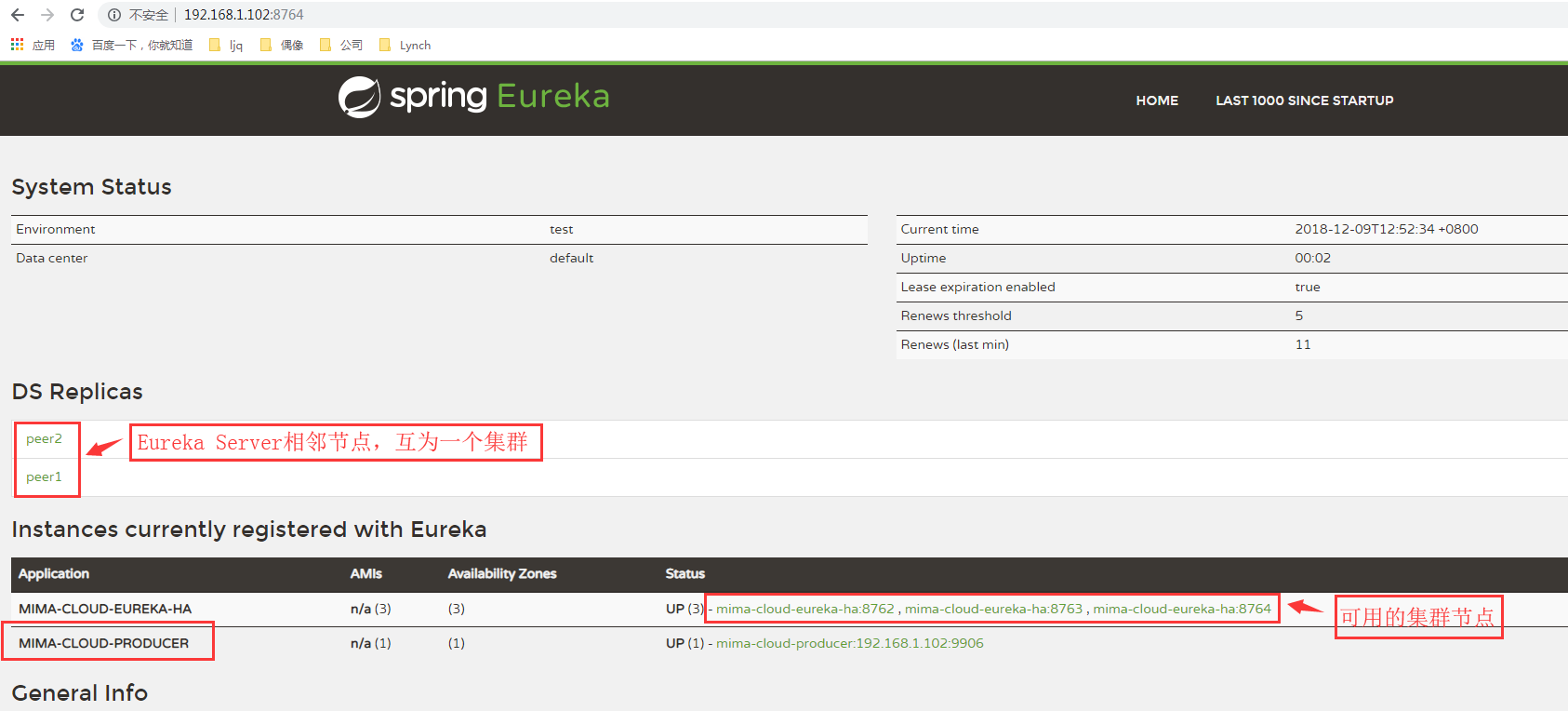
从上面可以看到,eurekaClient客户端MIMA-CLOUD-PRODUCER已注册到Eureka集群中。
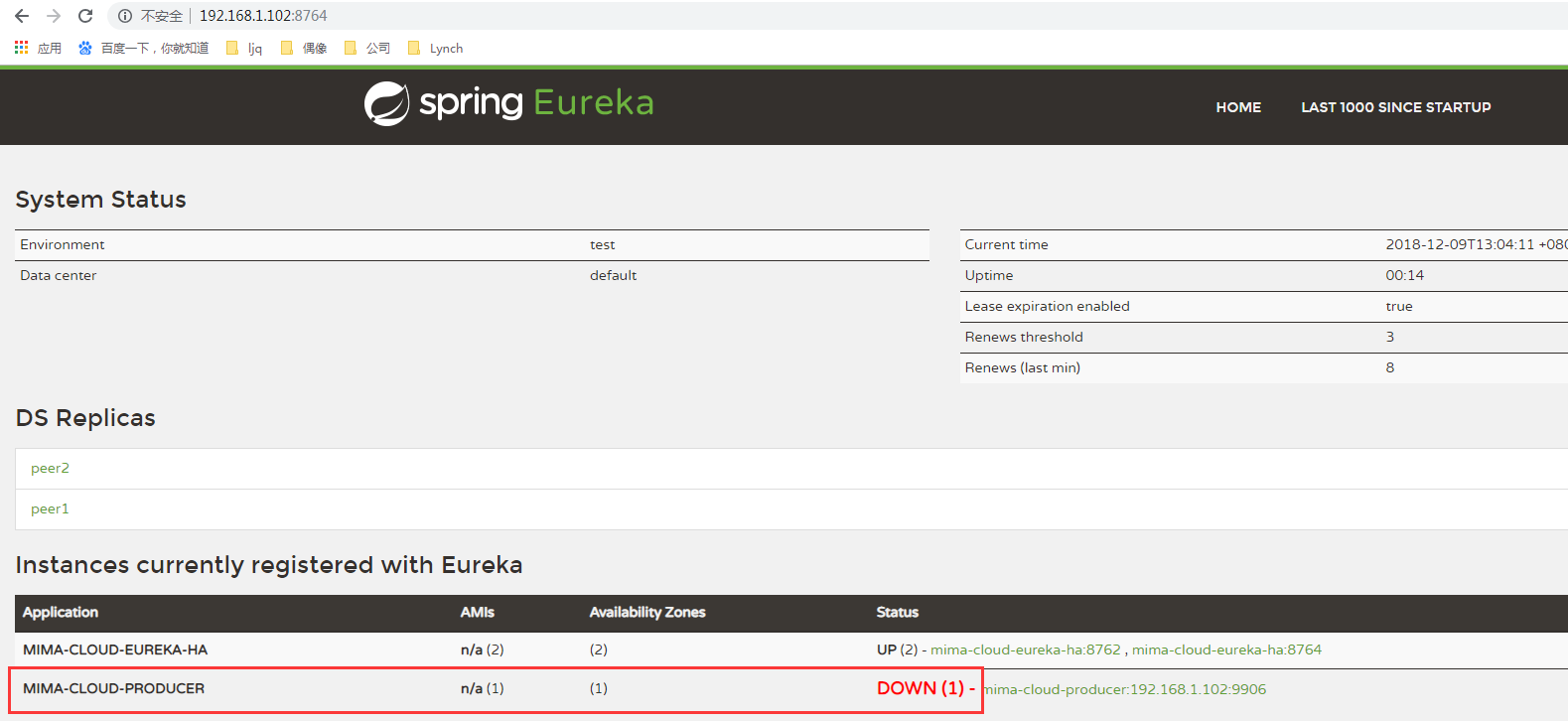
现把MIMA-CLOUD-PRODUCER服务关闭,刷新注册中心节点
非Java服务注册到Eureak Server
作为服务注册中心,应该是语言无关的,使用其他语言的服务也可以通过调用Eureka Server的Rest API 注册服务,这里不详细展开。
Eureka单机高可用伪集群配置的更多相关文章
- Redis高可用之集群配置(六)
0.Redis目录结构 1)Redis介绍及部署在CentOS7上(一) 2)Redis指令与数据结构(二) 3)Redis客户端连接以及持久化数据(三) 4)Redis高可用之主从复制实践(四) 5 ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- 搭建高可用mongodb集群(一)——配置mongodb
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. NOSQL有这些优势: 大数据量,可以通过 ...
- 构建高可用ZooKeeper集群
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
- 构建高可用ZooKeeper集群(转载)
ZooKeeper 是 Apache 的一个顶级项目,为分布式应用提供高效.高可用的分布式协调服务,提供了诸如数据发布/订阅.负载均衡.命名服务.分布式协调/通知和分布式锁等分布式基础服务.由于 Zo ...
- Dubbo+zookeeper构建高可用分布式集群(二)-集群部署
在Dubbo+zookeeper构建高可用分布式集群(一)-单机部署中我们讲了如何单机部署.但没有将如何配置微服务.下面分别介绍单机与集群微服务如何配置注册中心. Zookeeper单机配置:方式一. ...
- java:redis(redis安装配置,redis的伪集群配置)
1.redis安装配置: .安装gcc : yum install gcc-c++ .使用FTP工具FileZilla上传redis安装包到linux根目录下(当前步骤可以替换为:在root目录下执行 ...
- Redis之高可用、集群、云平台搭建
原文:Redis之高可用.集群.云平台搭建 文章大纲 一.基础知识学习二.Redis常见的几种架构及优缺点总结三.Redis之Redis Sentinel(哨兵)实战四.Redis之Redis Clu ...
- 搭建高可用mongodb集群(四)—— 分片(经典)
转自:http://www.lanceyan.com/tech/arch/mongodb_shard1.html 按照上一节中<搭建高可用mongodb集群(三)-- 深入副本集>搭建后还 ...
随机推荐
- MySQL开发——【字符集、校对集】
字符集 查看MySQL中的字符集 基本语法: show character set; 查看MySQL中的默认字符集 基本语法: show variables like ‘character_set%’ ...
- O365 Manager Plus帮助台委派介绍
O365 Manager Plus帮助台委派介绍 虽然Office 365允许您在全球任何地方工作,但它提供的管理功能十分不足.当一个组织分布在多个国家/地区时,一个管理员很难单独管理所有用户和邮箱. ...
- jQuery的事件,动画效果等
一.事件 click(function(){}) 点击事件 hover(function(){}) 悬浮事件,这是jQuery封装的,js没有不能绑定事件 focus(function(){}) ...
- Windows平台下载Android源码(整理)
Google官方下载源码使用的系统Ubuntu系统,不过现在我们需要在Windows系统中下载Android源码文件. 网站的地址是:https://android.googlesource.com/ ...
- Altera 在线资源使用
Altera 在线资源使用 Altera 在线资源使用 1 1.Altera中文版 2 2.建立myaltera账户 获取官网信息与支持 2 3系统化的设计资源 2 3.1.设计实例 2 3.2.参考 ...
- 关于使用Visual编译静态库动态库及其使用的问题
本文主要讲述了如何使用Visual Studio 2013 编译静态库和动态库,并使用. 一.静态库 1. 编写静态库 若要创建将引用并使用刚创建的静态库的应用程序,请从“文件”菜单中选择“新建”, ...
- windows 批处理语言学习
程序员应该根植于心的一个理念是:重复的工作交给代码.windows上的批处理脚本就是这种理念的体现. 批处理bat能做的事很多,自动配置vs工程中的代码依赖环境,调用其它程序处理数据.自动编译代码等等 ...
- cf 20C Dijkstra?
带队列 dijkstra #include <iostream> #include <cstdio> #include <queue> #include < ...
- DDD简明入门之道 - 开篇
DDD简明入门之道 - 开篇 犹豫了很久才写下此文,一怕自己对DDD的理解和实践方式有偏差,二怕误人子弟被贻笑大方,所以纰漏之处还望各位谅解.不啰嗦,马上进入正题,如果你觉得此文不错就点个赞吧. 概述 ...
- WPF实现特殊统计图
效果图: ActiveFunItem.xaml代码: <UserControl x:Class="SunCreate.Vipf.Client.UI.ActiveFunItem" ...