使用iconv进行编码gb2312转utf8 转码失败的坑
iconv 编码gb2312转utf8 转码失败的坑
使用背景
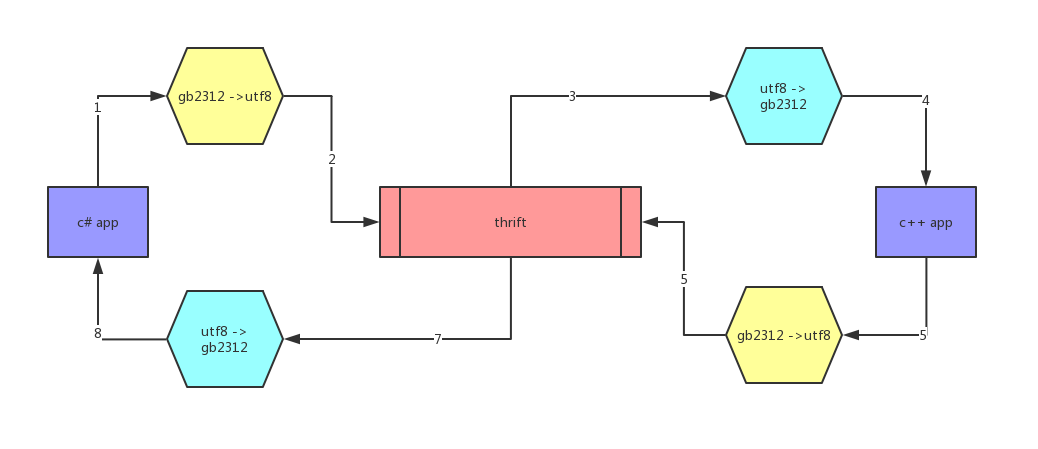
项目中使用thrift进行C#程序调用c++接口,其中的协议是通过json进行传输的,由于默认thrift使用utf8进行传输,而C#和c++程序都默认使用多字节的编码方式,所以在传输前就需要对编码进行utf8的转换,而在接收处理的时候再转换成gb2312。
问题
bug发生在一个文件路径上面,包含文件路径就会导致c++端无法解析,但是纯中文和英文及不同字符都没有问题,所以一开始未怀疑是编码问题,经过调试最终确定问题在iconv转码上,在转码的时候转换失败,导致返回结果为空。
分析
文件名为"1癵鰢⑷}·ˇ々.mp4",其中包含有特殊汉字和字符,猜测为字符集无法表示导致转码失败。
解决
网上查询确实存在该问题,建议将编码gb2312换成 gb18030 以支持更多字符。
原来的转码函数
std::string ConvertCode::gbk2utf8(const std::string& strGbk)
{
return code_convert("gb2312", "utf-8", strGbk);
}
转变以后测试正常
std::string ConvertCode::gbk2utf8(const std::string& strGbk)
{
return code_convert("gb18030", "utf-8", strGbk);
}
附iconv转变函数
std::string ConvertCode::code_convert(char *source_charset, char *to_charset, const std::string& sourceStr)
{
iconv_t cd = iconv_open(to_charset, source_charset);//获取转换句柄,void*类型
if (cd == 0)
return "";
size_t inlen = sourceStr.size();
if (inlen == 0)
return "";
size_t outlen = inlen*2+1;
const char* inbuf = (char*)sourceStr.c_str();
char* outbuf = (char*)malloc(outlen);
memset(outbuf, 0, outlen);
char *poutbuf = outbuf; //多加这个转换是为了避免iconv这个函数出现char(*)[255]类型的实参与char**类型的形参不兼容
if (iconv(cd, &inbuf, &inlen, &poutbuf, &outlen) == -1)
return "";
std::string strTemp(outbuf);//此时的strTemp为转换编码之后的字符串
iconv_close(cd);
return strTemp;
}使用iconv进行编码gb2312转utf8 转码失败的坑的更多相关文章
- UTF8转换为GB编码gb2312转换为utf-8
这个方法是用windows的字符集转换的,跟sybase 的unicode码表可能在某些符号上有差别,对于大部分字符来说,尤其是 汉字,应该不会有问题的,如果要求比较高的话,可以买sybase的 un ...
- C#获取文本文件的编码,自动区分GB2312和UTF8
C# 获取文本文件的编码,自动区分GB2312和UTF8 以下是获取文件编码的一个类 using System; using System.IO; using System.Text; /// < ...
- 网络编码 GB2312、GBK与UTF-8的区别
GB2312.GBK与UTF-8的区别 这是一个异常经典的问题,有无数的新手站长每天都在百度这个问题,而我,作为一个“伪老手”站长,在明白这个这个问题的基础上,有必要详细的解答一下. 首先,我们要 ...
- 字符编码(ASCII、ANSI、GB2312、UTF-8等)系统梳理
引言 在显示器上看见的文字.图片等信息在电脑里面其实并不是我们看见的样子,即使你知道所有信息都存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片.假设,你用显微镜把盘片放大,会看见盘片表面凹凸不 ...
- 字符编码(ASCII、ANSI、GB2312、UTF-8等)系统梳理(转载)
引言 在显示器上看见的文字.图片等信息在电脑里面其实并不是我们看见的样子,即使你知道所有信息都存储在硬盘里,把它拆开也看不见里面有任何东西,只有些盘片.假设,你用显微镜把盘片放大,会看见盘片表面凹凸不 ...
- 采集的时候,列表的编码是gb2312,内容页的编码却是UTF-8,这种网站怎么采集?
采集的时候,列表的编码是gb2312,内容页的编码却是UTF-8,这种网站怎么采集? 采集的时候,列表的编码是UTF-8,内容页的编码却是gb2312,这种网站怎么采集? 这种情况怎么解决呢? 哈哈哈 ...
- 各种编码UNICODE、UTF-8、ANSI、ASCII、GB2312、GBK详解
来自:http://blog.csdn.net/lvxiangan/article/details/8151670 ------------------------------------------ ...
- 编码介绍(ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE)
转载:http://blog.jobbole.com/30526/(前面内容)和http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf ...
- 编码的来源于格式简介ANSI、GBK、GB2312、UTF-8、GB18030和 UNICODE
编码一直是让新手头疼的问题,特别是 GBK.GB2312.UTF-8 这三个比较常见的网页编码的区别,更是让许多新手晕头转向,怎么解释也解释不清楚.但是编码又是那么重要,特别在网页这一块.如果你打出来 ...
随机推荐
- oracle-查询-时间条件查询
select * from 表名 where date =to_date('时间','yyyy-dd-mm');
- VIBE(前景检测)
1.VIBE思想: 为每个像素点存储了一个样本集,样本集中采样值就是该像素点过去的像素值和其邻居点的像素值,然后将每一个新的像素值和样本集进行比较来判断是否属于背景点. 2.VIBE模型初始化 通用的 ...
- /etc/sysconfig/iptables 默认配置详解
[参考链接]:一把三尺剑的百度知道回答 1. iptables文件 2. 规则语句详解 :INPUT ACCEPT [0:0] # 该规则表示INPUT表默认策略是ACCEPT :FORWARD AC ...
- Liferay7 BPM门户开发之10: 通用流程实现从Servlet到Portlet(Part1)
开发目的: 实现通用流程自动化处理(即实现不需要hardcode代码的bpm统一处理后台,仅需要写少量前端html form代码和拖拽设计BPM定义) 既可独立运行或可依托于Liferay或依托其它门 ...
- vue中axios的安装和使用
有很多时候你在构建应用时需要访问一个 API 并展示其数据.做这件事的方法有好几种,而使用基于 promise 的 HTTP 客户端 axios 则是其中非常流行的一种. 安装包:如果没有安装cnpm ...
- ffmpeg 处理视频项目中用到的一些命令
多媒体视频处理工具FFmpeg有非常强大的功能包括视频采集功能.视频格式转换.视频抓图.给视频加水印等. 目前仅接触到了一些初级命令,今天进行了简单整理. 分辨率 //智能1:1缩放 -i : -vf ...
- 剑指offer【02】- 替换空格(Java)
题目:替换空格 考点:字符串 题目描述: 请实现一个函数,将一个字符串中的每个空格替换成“%20”.例如,当字符串为We Are Happy.则经过替换之后的字符串为We%20Are%20Happy. ...
- web自动化测试---测试中其他一些常用操作
一些其他常用操作如下: 1.最大化浏览器窗口 driver.maximize_window() 2.后退 driver.back() 3.前进 driver.forward() 4.刷新操作 driv ...
- Intellij-插件安装-JRebel热部署插件安装
环境介绍: Win7.JDK1.8.maven+jetty插件.SpringMVC.Intellij IDEA 2018.1.2 安装插件: 在线安装: Settings --> Plugins ...
- Google Optimization Tools实现加工车间任务规划【Python版】
上一篇介绍了<使用.NET Core与Google Optimization Tools实现加工车间任务规划>,这次将Google官方文档python实现的版本的完整源码献出来,以满足喜爱 ...