(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境:
火狐浏览器
pycharm2017.3.3
python3.5
1.url不仅可以是一个字符串,例如:http://www.baidu.com。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为URLopen的参数使用,方法如下:
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
这段代码同样可以得到网页信息
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl(),info()方法,getcode()方法。
geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功;
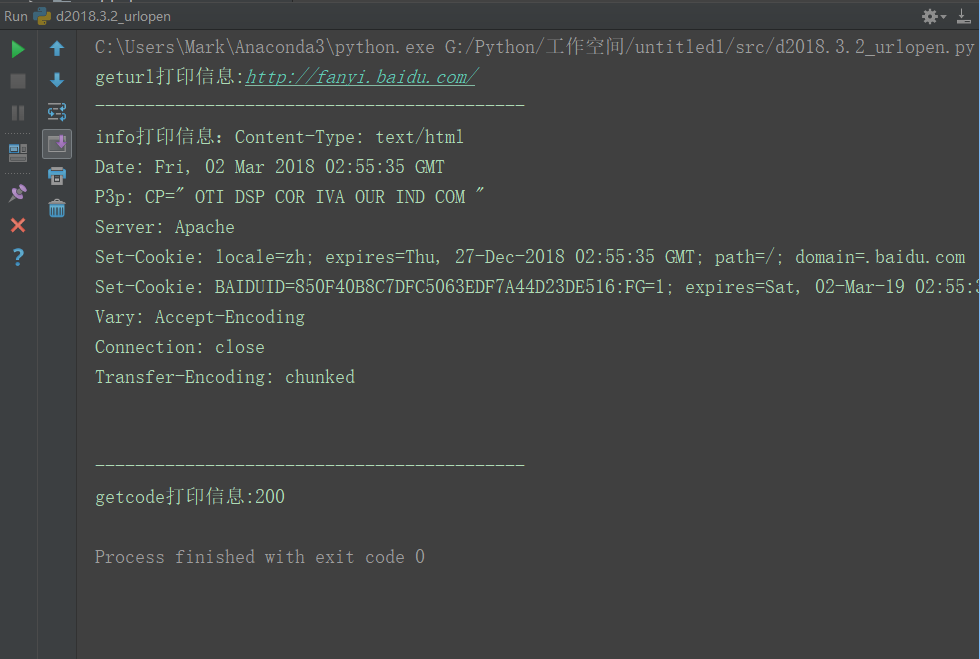
根据这些,编写如下代码
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
print("geturl打印信息:%s" % (response.geturl()))
print("-------------------------------------------")
print("info打印信息:%s" % (response.info()))
print("-------------------------------------------")
print("getcode打印信息:%s" % (response.getcode()))
运行结果
2.urlopen的data参数
我们可以使用data参数,向服务器发送数据
从客户端向服务器提交数据使用post
如果没有设置urlopen()函数的data参数,HTTP请求采用get方式也就是从服务器获取数据,如果我们设置data参数,HTTP请求采用post方式,就可以向服务器传送数据
3.发送data实例
向有道翻译发送data,得到翻译结果
(1)打开有道翻译界面,如下图所示
(2)右键查看元素,选择网络
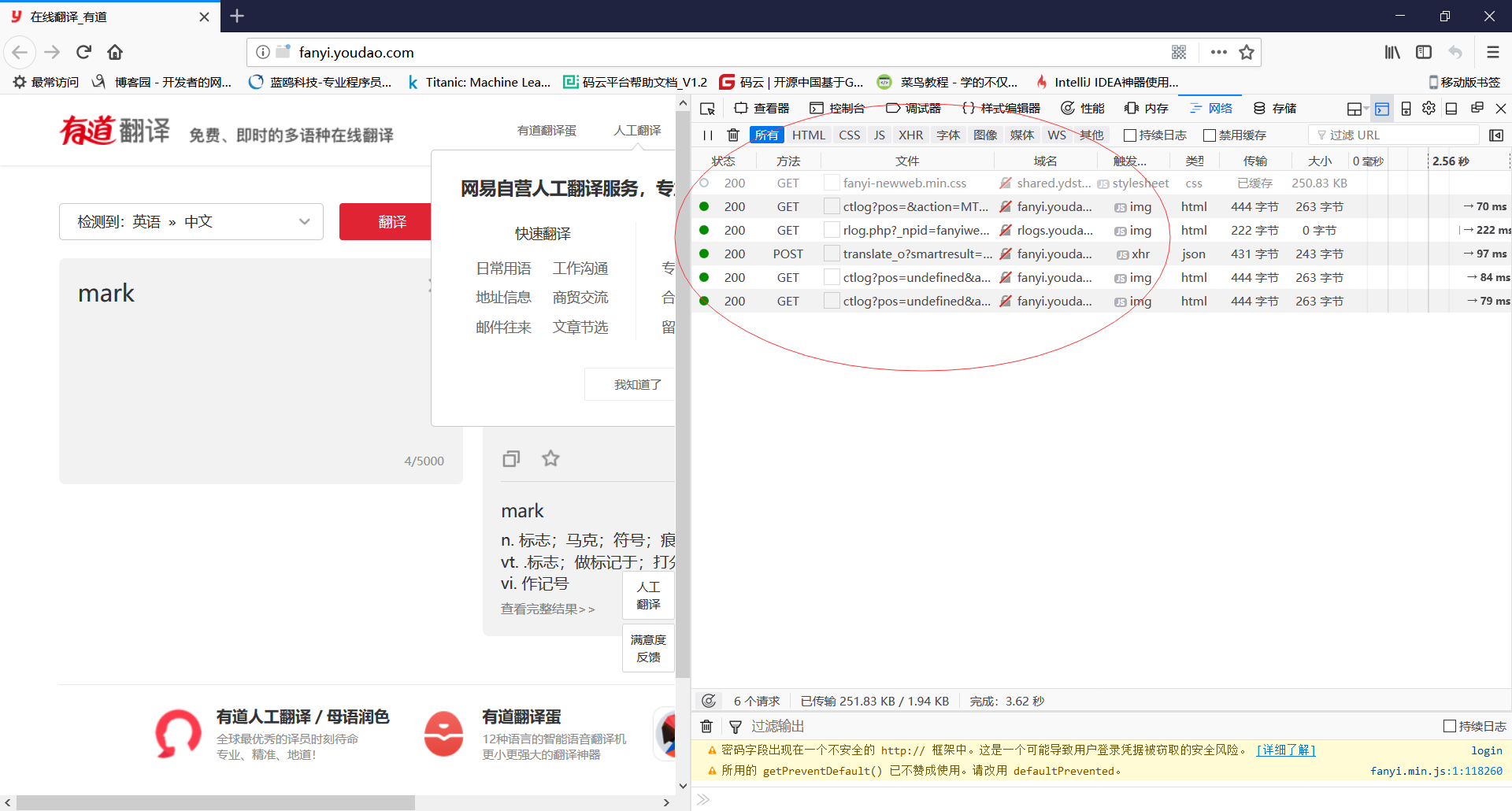
(3)在翻译中输入单词mark,点击翻译,可以看到列表出现了新东西,双击方式为post的这行
(4)查看消息头中的请求网址,记录下来,一会要用
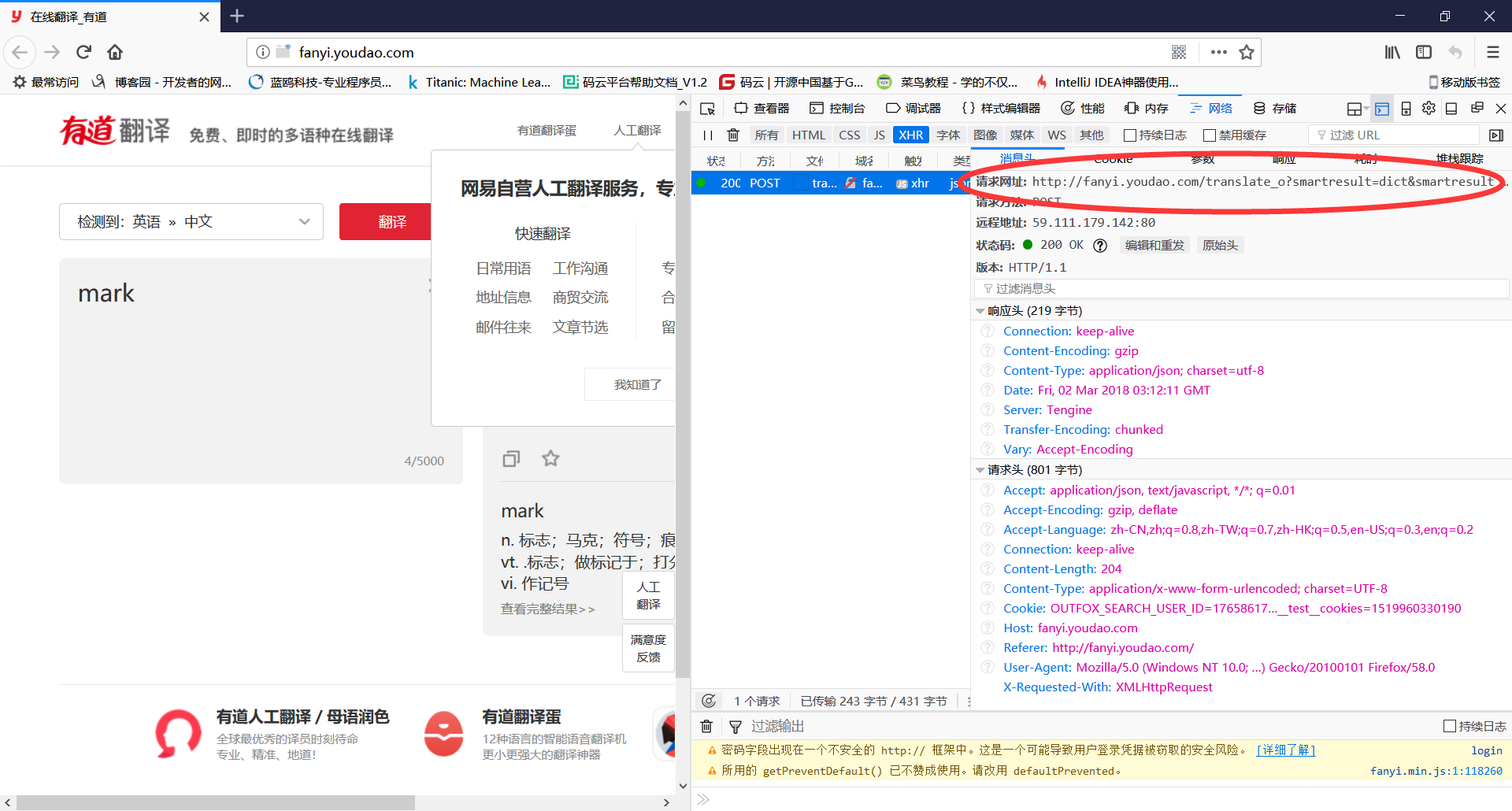
(5)点击参数,得到表单数据,记录下来,一会要用
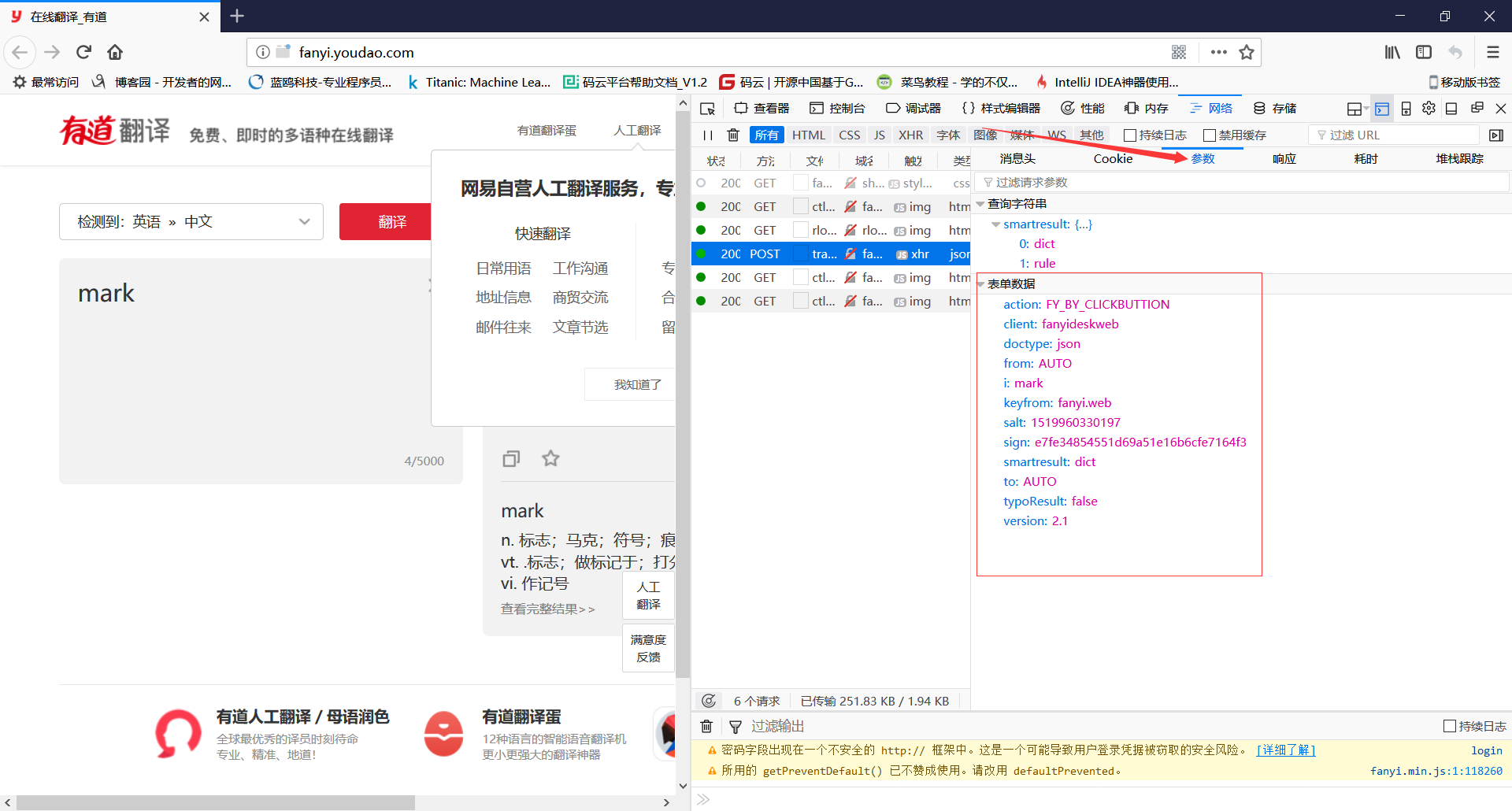
(6)得到以上数据后,写代码如下
这。。。里有点问题了,好像不能通过抓包爬了,还得使用它的api,研究了一会没整明白,写了这么多,不舍得删了,先撂这,以后再弄,我去找一个抓包可以爬的,再写一篇新的
(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果的更多相关文章
- Python3网络爬虫(三):urllib.error异常
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 转载请注明作者和出处:http://blog.csdn.net/c406495762/article ...
- 利用urllib.urlopen向有道翻译发送数据获得翻译结果
from urllib import request,parseimport requests, sys,ssl,json ssl._create_default_https_context = ss ...
- Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:https://baike.baidu.com/.url也可以是一个Request对象,这就需要我们先定义一个Reques ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
随机推荐
- mvn打包到私服的命令
1.mvn clean package install -Dmaven.test.skip=true deploy 2.docker清楚Nexus私服上包的命令: a) docker exec -it ...
- 判断response.data是否为空
需要对response.data进行判断,是否有数据返回.如果是空的,将要处理一些事情,反之,又要处理另外一些事情. 在jQuery程序中,有一个方法:$.isEmptyObject().此方法在an ...
- MySql 数据库移植记录
在使用长文本时,SqlServer 在以下情况下工作正常 [Property("CContent", ColumnType = "StringClob", Le ...
- Scala学习(五)---Scala中的类
Scala中的类 摘要: 在本篇中,你将会学习如何用Scala实现类.如果你了解Java或C++中的类,你不会觉得这有多难,并且你会很享受Scala更加精简的表示法带来的便利.本篇的要点包括: 1. ...
- 2.RapidIO串行物理层的包与控制符号
转自https://www.cnblogs.com/liujinggang/p/9932150.html 一.RapidIO串行物理层背景介绍 上篇博文提到RapidIO的物理层支持串行物理层与并行物 ...
- python 文本特征提取 CountVectorizer, TfidfVectorizer
1. TF-IDF概述 TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与文本挖掘的常用加权技术.TF-IDF是一种统计方法,用以评 ...
- MPI-Hydra Process Managerment Framework
1. 概述2. 执行过程和控制流 官方文档地址:https://wiki.mpich.org/mpich/index.php/Hydra_Process_Management_Framework 1. ...
- EF5.0区别于EF4.0的crud区别
public T AddEntity(T entity) { //EF4.0的写法 添加实体 //db.CreateObjectSet<T>().AddObject(entity); // ...
- BGFX 渲染引擎中着色器代码的调试方法
在实时渲染的图形开发中,着色器代码(Shader)越来越复杂,于是单纯的靠经验和不断试错的开发和调试方法早已不能满足实际需求.使用调试工具进行调试,成为开发中重要的方法.Bgfx 是一款跨平台.抽象封 ...
- 个人对vuex的表象理解(笔记)
一个东西,首先要知道为什么用它,为什么要vuex,官方解释为了解决繁杂事件订阅和广播,那么事件的$dispatch,$on,怎么就复杂了?许多人是不是感觉后者还挺简单的,对的 如果简单小型项目,那么不 ...