(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果
环境:
火狐浏览器
pycharm2017.3.3
python3.5
1.url不仅可以是一个字符串,例如:http://www.baidu.com。url也可以是一个Request对象,这就需要我们先定义一个Request对象,然后将这个Request对象作为URLopen的参数使用,方法如下:
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
html = response.read()
html = html.decode("utf-8")
print(html)
这段代码同样可以得到网页信息
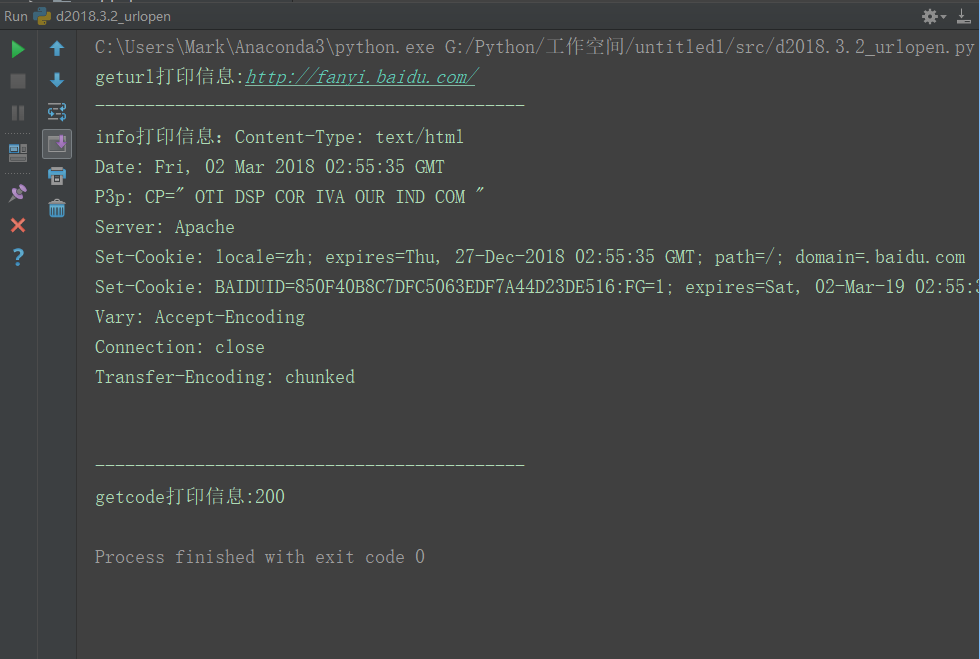
urlopen()返回的对象,可以使用read()进行读取,同样也可以使用geturl(),info()方法,getcode()方法。
geturl()返回的是一个url的字符串;
info()返回的是一些meta标记的元信息,包括一些服务器的信息;
getcode()返回的是HTTP的状态码,如果返回200表示请求成功;
根据这些,编写如下代码
from urllib import request
req = request.Request("http://fanyi.baidu.com/")
response = request.urlopen(req)
print("geturl打印信息:%s" % (response.geturl()))
print("-------------------------------------------")
print("info打印信息:%s" % (response.info()))
print("-------------------------------------------")
print("getcode打印信息:%s" % (response.getcode()))
运行结果
2.urlopen的data参数
我们可以使用data参数,向服务器发送数据
从客户端向服务器提交数据使用post
如果没有设置urlopen()函数的data参数,HTTP请求采用get方式也就是从服务器获取数据,如果我们设置data参数,HTTP请求采用post方式,就可以向服务器传送数据
3.发送data实例
向有道翻译发送data,得到翻译结果
(1)打开有道翻译界面,如下图所示
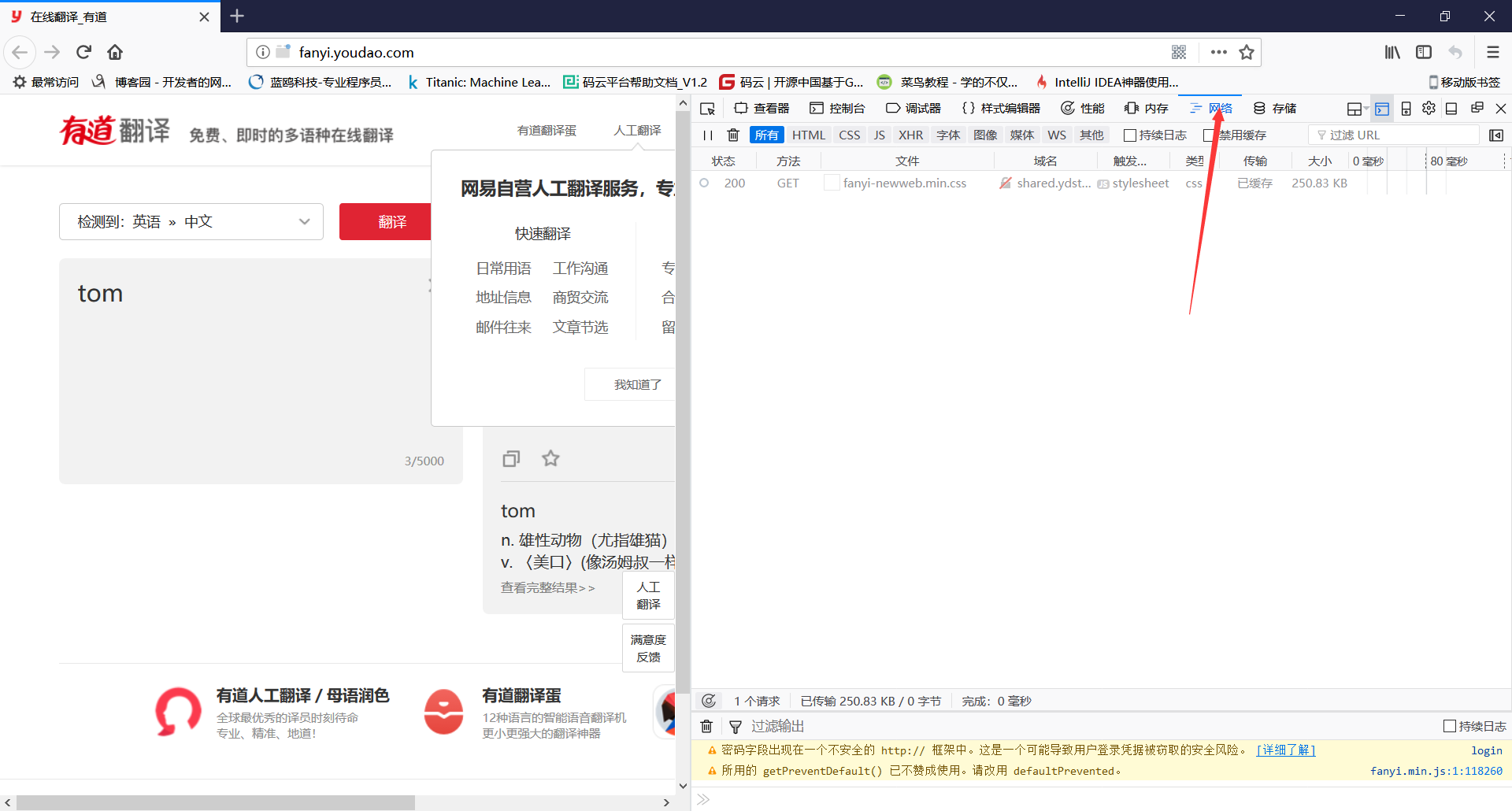
(2)右键查看元素,选择网络
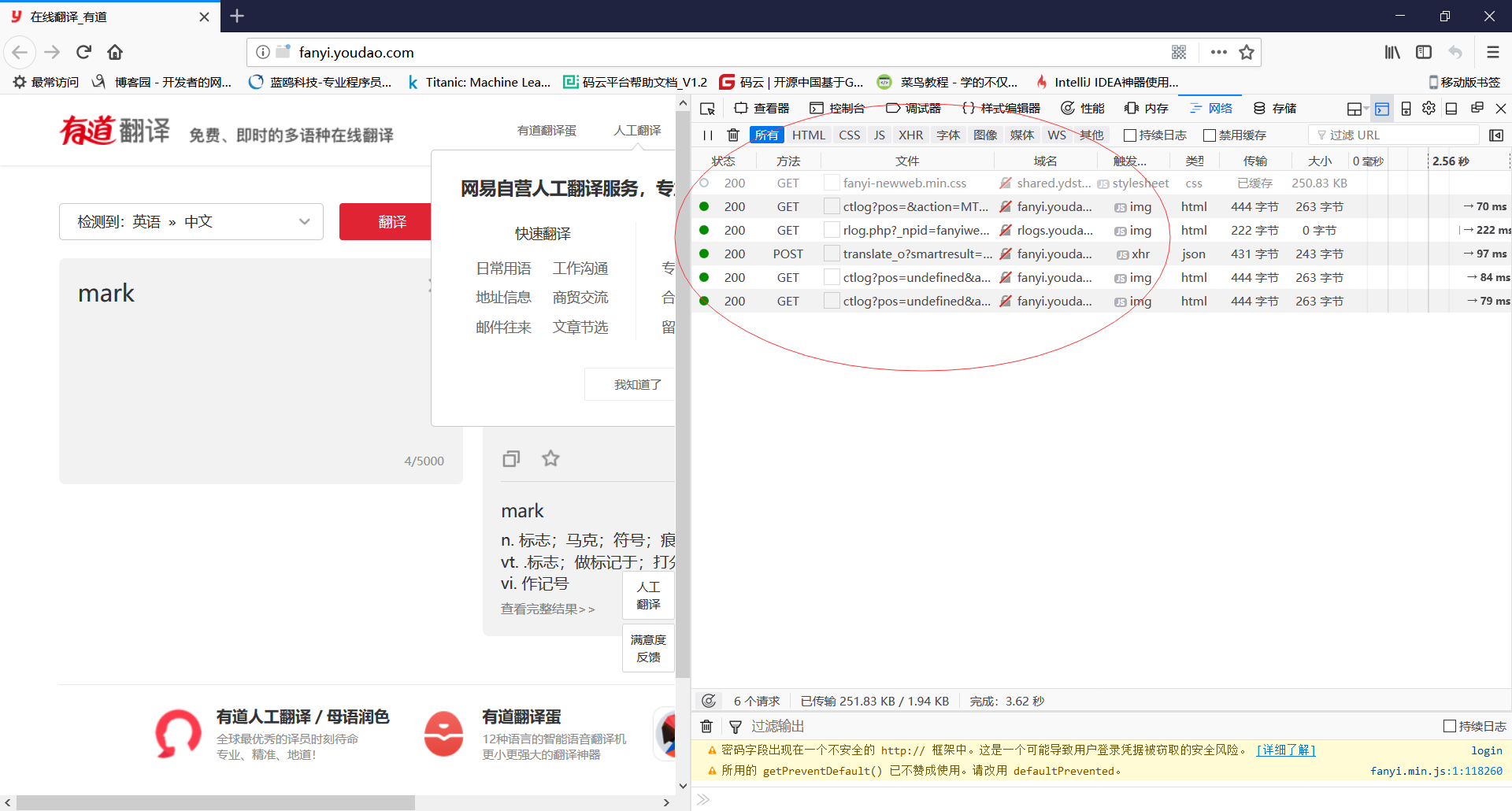
(3)在翻译中输入单词mark,点击翻译,可以看到列表出现了新东西,双击方式为post的这行
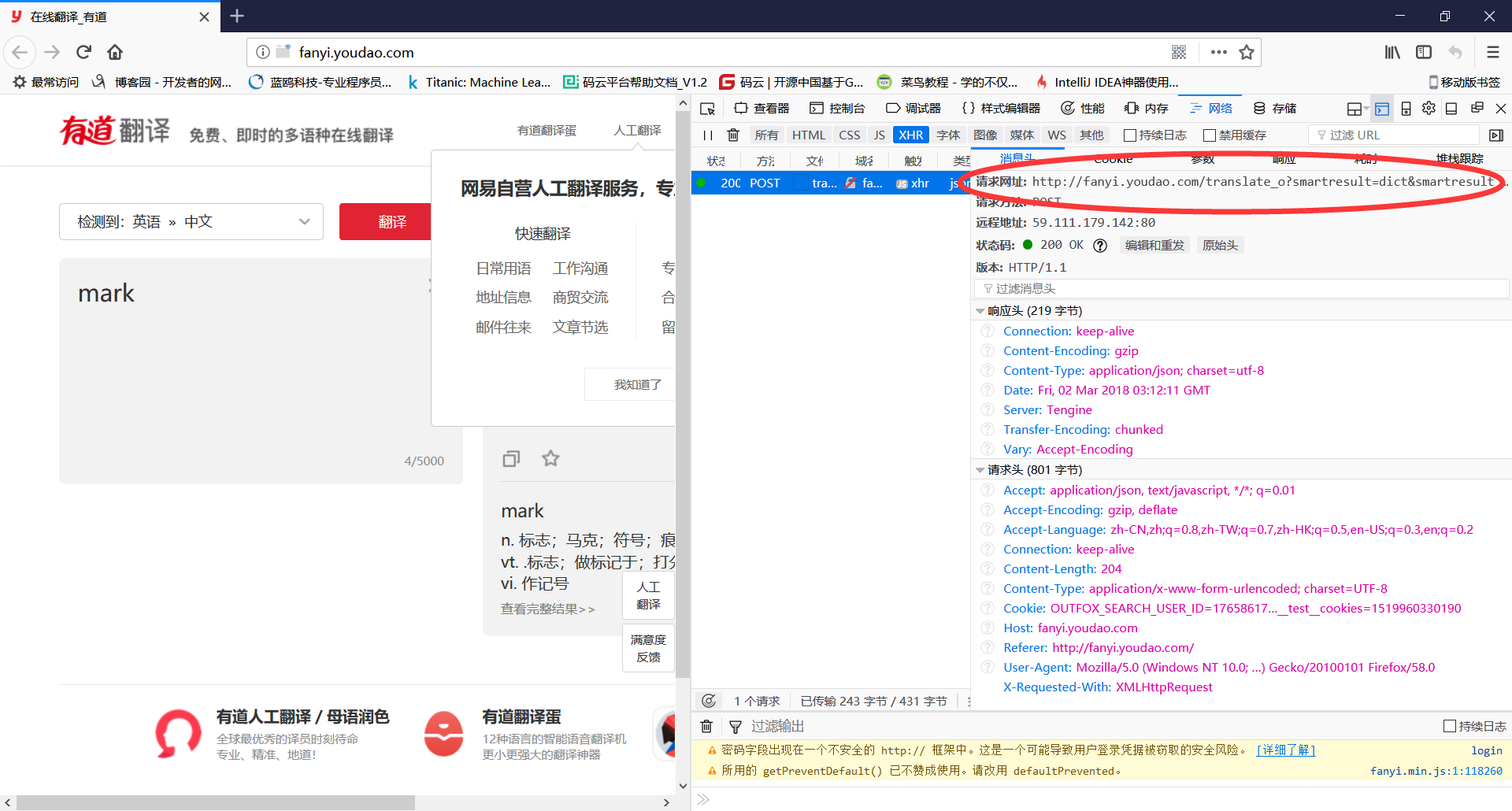
(4)查看消息头中的请求网址,记录下来,一会要用
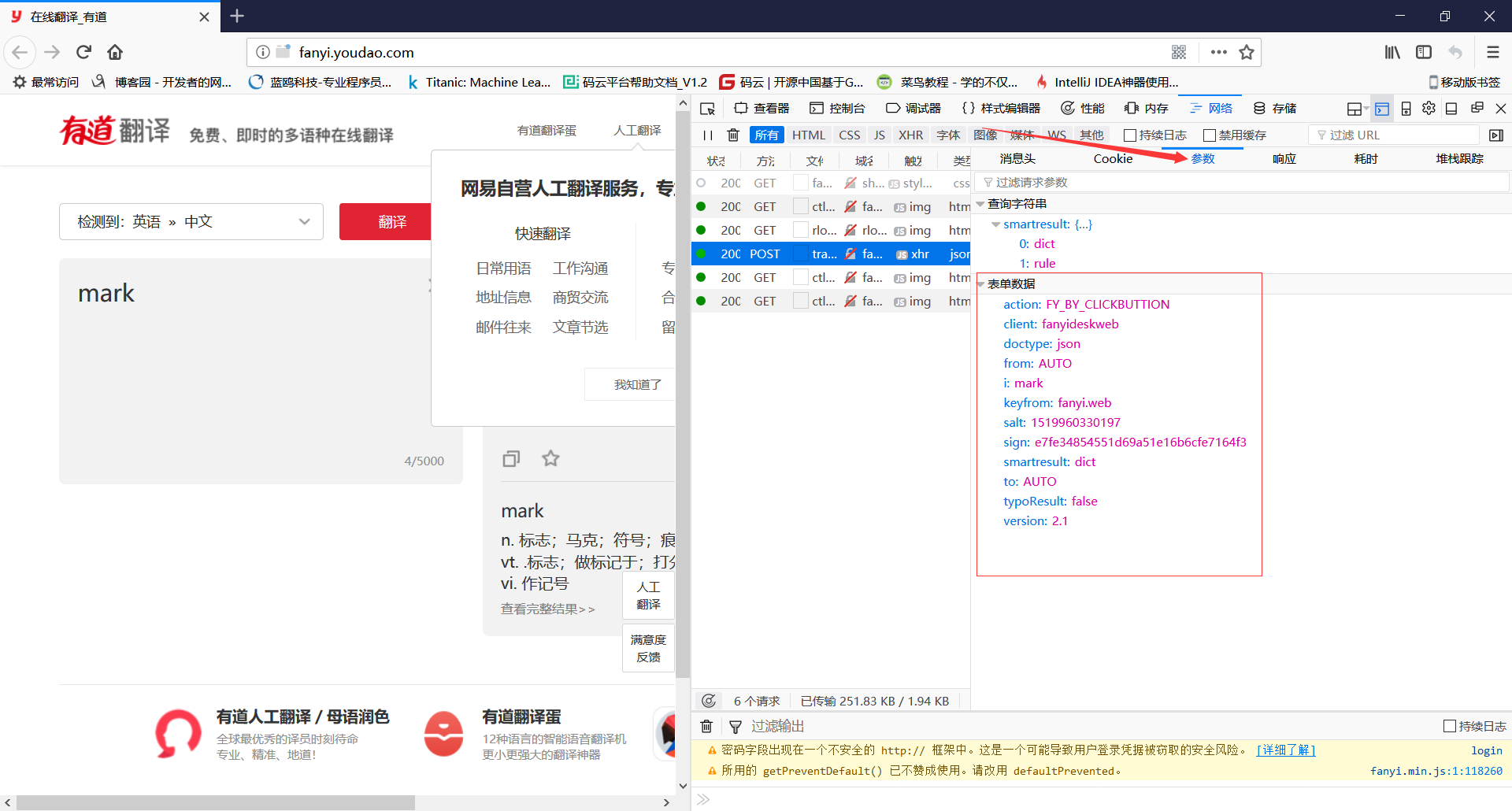
(5)点击参数,得到表单数据,记录下来,一会要用
(6)得到以上数据后,写代码如下
这。。。里有点问题了,好像不能通过抓包爬了,还得使用它的api,研究了一会没整明白,写了这么多,不舍得删了,先撂这,以后再弄,我去找一个抓包可以爬的,再写一篇新的
(未完成...)Python3网络爬虫(2):利用urllib.urlopen向有道翻译发送数据并获得翻译结果的更多相关文章
- Python3网络爬虫(三):urllib.error异常
运行平台:Windows Python版本:Python3.x IDE:Sublime text3 转载请注明作者和出处:http://blog.csdn.net/c406495762/article ...
- 利用urllib.urlopen向有道翻译发送数据获得翻译结果
from urllib import request,parseimport requests, sys,ssl,json ssl._create_default_https_context = ss ...
- Python3爬虫(2)_利用urllib.urlopen发送数据获得反馈信息
一.urlopen的url参数 Agent url不仅可以是一个字符串,例如:https://baike.baidu.com/.url也可以是一个Request对象,这就需要我们先定义一个Reques ...
- 转:【Python3网络爬虫开发实战】 requests基本用法
1. 准备工作 在开始之前,请确保已经正确安装好了requests库.如果没有安装,可以参考1.2.1节安装. 2. 实例引入 urllib库中的urlopen()方法实际上是以GET方式请求网页,而 ...
- Python3网络爬虫开发实战PDF高清完整版免费下载|百度云盘
百度云盘:Python3网络爬虫开发实战高清完整版免费下载 提取码:d03u 内容简介 本书介绍了如何利用Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib.req ...
- Python3 网络爬虫(请求库的安装)
Python3 网络爬虫(请求库的安装) 爬虫可以简单分为几步:抓取页面,分析页面和存储数据 在页面爬取的过程中我们需要模拟浏览器向服务器发送请求,所以需要用到一些python库来实现HTTP的请求操 ...
- 崔庆才Python3网络爬虫开发实战电子版书籍分享
资料下载地址: 链接:https://pan.baidu.com/s/1WV-_XHZvYIedsC1GJ1hOtw 提取码:4o94 <崔庆才Python3网络爬虫开发实战>高清中文版P ...
- 《Python3 网络爬虫开发实战》开发环境配置过程中踩过的坑
<Python3 网络爬虫开发实战>学习资料:https://www.cnblogs.com/waiwai14/p/11698175.html 如何从墙内下载Android Studio: ...
- 《Python3 网络爬虫开发实战》学习资料
<Python3 网络爬虫开发实战> 学习资料 百度网盘:https://pan.baidu.com/s/1PisddjC9e60TXlCFMgVjrQ
随机推荐
- .NET小笔记-NPOI读取excel内容到DataTable
下载比较新的NPOI组件支持excel2007以上的,把.dll添加引用 引入命名空间 using NPOI.HSSF.UserModel;using NPOI.SS.UserModel;using ...
- Quartz.net 定时任务之储存与持久化和集群(源码)
一.界面 1.这篇博客不上教程.直接看结果(包括把quartz任务转换成Windows服务) (1).主界面 (2).添加任务(默认执行) (3).编辑(默认开启) (4).关闭和开启 2.代码说明 ...
- mysql 多主
原理:多个msyql/mariadb之间可以实时同步,任意节点的操作可以立即同步到其他节点,底层采用galera插件同步,类似rsync,上层mysql相对于galera是透明的,可以实现多节点同时读 ...
- Docker容器学习梳理 - 容器间网络通信设置(Pipework和Open vSwitch)
自从Docker容器出现以来,容器的网络通信就一直是被关注的焦点,也是生产环境的迫切需求.容器的网络通信又可以分为两大方面:单主机容器上的相互通信,和跨主机的容器相互通信.下面将分别针对这两方面,对容 ...
- 访谈:BugPhobia’s Brief Communication
0x01 :采访的学长简介 If you weeped for the missing sunset, you would miss all the shining stars 梁野,北京航空航天大学 ...
- Linux内核第四节 20135332武西垚
实验目的: 使用库函数API和C代码中嵌入汇编代码两种方式使用同一个系统调用 实验过程: 查看系统调用列表 get pid 函数 #include <stdio.h> #include & ...
- ACL访问控制
/etc/squid/squid.conf 定义语法: acl aclname acltype string acl aclname acltype "file" s ...
- PAT L1-027 出租
https://pintia.cn/problem-sets/994805046380707840/problems/994805107638517760 下面是新浪微博上曾经很火的一张图: 一时间网 ...
- MYSQL INDEX BTREE HASH
https://dev.mysql.com/doc/refman/5.6/en/index-btree-hash.html 译文:http://itindex.net/detail/54241-tre ...
- STL数据结构
priority_queue "C++ reference"上如此解释priority queue:"This context is similar to a heap, ...