Machine Learning in Action -- Logistic regression
这个系列,重点关注如何实现,至于算法基础,参考Andrew的公开课
相较于线性回归,logistic回归更适合用于分类
因为他使用Sigmoid函数,因为分类的取值是0,1
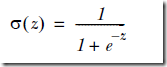
对于分类,最完美和自然的函数,当然是Heaviside step function,即0-1阶跃函数,但是这个函数中数学上有时候比较难处理
所以用Sigmoid函数来近似模拟阶跃函数,
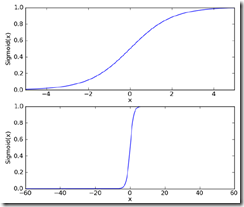
可以看到Sigmoid在增大坐标尺度后,已经比较接近于阶跃函数
其中,
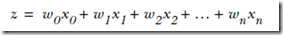
而logistic回归就是要根据训练集找到,最优的w向量
下面就通过源码来看看如何用梯度下降来解logistic问题,
def loadDataSet():
dataMat = []; labelMat = [] #数组
fr = open('testSet.txt')
for line in fr.readlines():
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])]) #加入一个数据点,其中‘1.0’代表截距
labelMat.append(int(lineArr[2])) #每个数据点的lable,用于训练
return dataMat,labelMat def sigmoid(inX):
return 1.0/(1+exp(-inX)) def gradAscent(dataMatIn, classLabels):
dataMatrix = mat(dataMatIn) #首先将array转换为matrix
labelMat = mat(classLabels).transpose() #将lables转秩,因为一个lable对应于dataMatrix中的一行,即一个数据点
m,n = shape(dataMatrix)
alpha = 0.001 #学习率
maxCycles = 500 #迭代次数
weights = ones((n,1)) #初始化weights向量
for k in range(maxCycles):
h = sigmoid(dataMatrix*weights) #这里是矩阵计算,最终h是个列向量,表示每个数据点的预估值
error = (labelMat - h) #和真实值比较,算出error列向量
weights = weights + alpha * dataMatrix.transpose()* error #这个公式是通过梯度下降推导出来的
return weights #获得最终的weights参数
这里需要注意,numpy支持矩阵计算,所以
h = sigmoid(dataMatrix*weights), 其实是完成n×m矩阵和n×1矩阵乘,然后执行n次sigmoid,得到h列向量
至于那个公式,是由于由梯度下降求出的weight迭代公式如下,

得到weights后,进行predict很容易,直接把数据点和weights代入sigmoid函数算出h,以0.5为界近似成0或1
这种原始的梯度下降算法的问题,就是计算量比较大,对于每个weight的迭代都需要遍历数据集一遍,所以如果weight和数据集比较大,很低效
stochastic gradient ascent
对于随机梯度下降,每次只用一个数据点来迭代weights
def stocGradAscent0(dataMatrix, classLabels):
m,n = shape(dataMatrix)
alpha = 0.01
weights = ones(n)
for i in range(m):
h = sigmoid(sum(dataMatrix[i]*weights)) #只取一个数据点
error = classLabels[i] - h
weights = weights + alpha * error * dataMatrix[i]
return weights
但这个简单的随机算法有些问题,
首先只迭代训练集一遍,很可能没有达到收敛,所以准确率不够
其次,每次是依次选取数据点,所以weights会产生周期性的波动
最后,收敛速度不够
def stocGradAscent1(dataMatrix, classLabels, numIter=150):
m,n = shape(dataMatrix)
weights = ones(n)
for j in range(numIter): #增加迭代次数
for i in range(m):
alpha = 4/(1.0+j+i)+0.01 #动态改变学习率
randIndex = int(random.uniform(0,len(dataIndex))) #随机选取数据点
h = sigmoid(sum(dataMatrix[randIndex]*weights))
error = classLabels[randIndex] - h
weights = weights + alpha * error * dataMatrix[randIndex]
del(dataIndex[randIndex])
return weights
对于动态改变学习率,
可以看到,学习率会随着迭代次数变大,不断变小,但不会为0,因为有常数项,可以缓解数据波动,并保持多次迭代后仍然对数据有一定的影响
并且当i>>j时,学习略随着迭代次数增加,也不是严格下降的
而随机选取数据点,用于解决周期性波动问题
Machine Learning in Action -- Logistic regression的更多相关文章
- [Machine Learning]学习笔记-Logistic Regression
[Machine Learning]学习笔记-Logistic Regression 模型-二分类任务 Logistic regression,亦称logtic regression,翻译为" ...
- Andrew Ng Machine Learning 专题【Logistic Regression & Regularization】
此文是斯坦福大学,机器学习界 superstar - Andrew Ng 所开设的 Coursera 课程:Machine Learning 的课程笔记. 力求简洁,仅代表本人观点,不足之处希望大家探 ...
- CheeseZH: Stanford University: Machine Learning Ex3: Multiclass Logistic Regression and Neural Network Prediction
Handwritten digits recognition (0-9) Multi-class Logistic Regression 1. Vectorizing Logistic Regress ...
- 机器学习---朴素贝叶斯与逻辑回归的区别(Machine Learning Naive Bayes Logistic Regression Difference)
朴素贝叶斯与逻辑回归的区别: 朴素贝叶斯 逻辑回归 生成模型(Generative model) 判别模型(Discriminative model) 对特征x和目标y的联合分布P(x,y)建模,使用 ...
- machine learning(10) -- classification:logistic regression cost function 和 使用 gradient descent to minimize cost function
logistic regression cost function(single example) 图像分布 logistic regression cost function(m examples) ...
- Machine Learning No.3: Logistic Regression
1. Decision boundary when hθ(x) > 0, g(z) = 1; when hθ(x) < 0, g(z) = 0. so the hyppthesis is: ...
- [Machine Learning] 逻辑回归 (Logistic Regression) -分类问题-逻辑回归-正则化
在之前的问题讨论中,研究的都是连续值,即y的输出是一个连续的值.但是在分类问题中,要预测的值是离散的值,就是预测的结果是否属于某一个类.例如:判断一封电子邮件是否是垃圾邮件:判断一次金融交易是否是欺诈 ...
- 机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归
机器学习实战(Machine Learning in Action)学习笔记————05.Logistic回归 关键字:Logistic回归.python.源码解析.测试作者:米仓山下时间:2018- ...
- 《Machine Learning in Action》—— Taoye给你讲讲Logistic回归是咋回事
在手撕机器学习系列文章的上一篇,我们详细讲解了线性回归的问题,并且最后通过梯度下降算法拟合了一条直线,从而使得这条直线尽可能的切合数据样本集,已到达模型损失值最小的目的. 在本篇文章中,我们主要是手撕 ...
随机推荐
- poj 1159 dp回文串
题意:添加最少的字符使之成为回文串 #include<cstdio> #include<iostream> #include<algorithm> #include ...
- java环境变量配置(转)
java环境变量配置 windows xp下配置JDK环境变量: 1.安装JDK,安装过程中可以自定义安装目录等信息,例如我们选择安装目录为D:\java\jdk1.5.0_08: 2.安装完成后,右 ...
- CDH中,如果管理CM中没有的属性
在CM配置管理中的"hive-site.xml 的 Hive 客户端高级配置代码段(安全阀)""仅适用于高级使用,逐个将字符串插入 hive-site.xml 的客户端配 ...
- Scala中的match(模式匹配)
文章来自:http://www.cnblogs.com/hark0623/p/4196261.html 转载请注明 代码如下: /** * 模式匹配 */ case class Class1(pa ...
- 16.2.13 asp.net 学习随笔
using System.Data.SqlClient;//连接数据库必须的 using System.Configuration; CommandType所在的命名空间 system.data; P ...
- Linphone iOS客户端编译时打开G729支持
Assuming you were able to compile the SDK and the linphone XCode project, here is what you need to d ...
- MP3/视频播放
简单的视频.MP3播放 <html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equ ...
- Revit二次开发示例:DisableCommand
Revit API 不支持调用Revit内部命令,但可以用RevitCommandId重写它们(包含任意选项卡,菜单和右键命令).使用RevitCommandId.LookupCommandId()可 ...
- 2015ACM/ICPC亚洲区长春站 B hdu 5528 Count a * b
Count a * b Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Tot ...
- BZOJ2675 : Bomb
首先通过不断翻转坐标系,假设三个点以横坐标为第一关键字,纵坐标为第二关键字排序后A在B前面,B在C前面. 那么只需要处理以下两种情况: 1.B的纵坐标在AC之间,这时三个点的距离和为$2((x_C+y ...