twitter storm源码走读之2 -- tuple消息发送场景分析
欢迎转载,转载请注明出处源自徽沪一郎。本文尝试分析tuple发送时的具体细节,本博的另一篇文章《bolt消息传递路径之源码解读》主要从消息接收方面来阐述问题,两篇文章互为补充。
worker进程内消息接收与处理全景图
先上幅图简要勾勒出worker进程接收到tuple消息之后的处理全过程
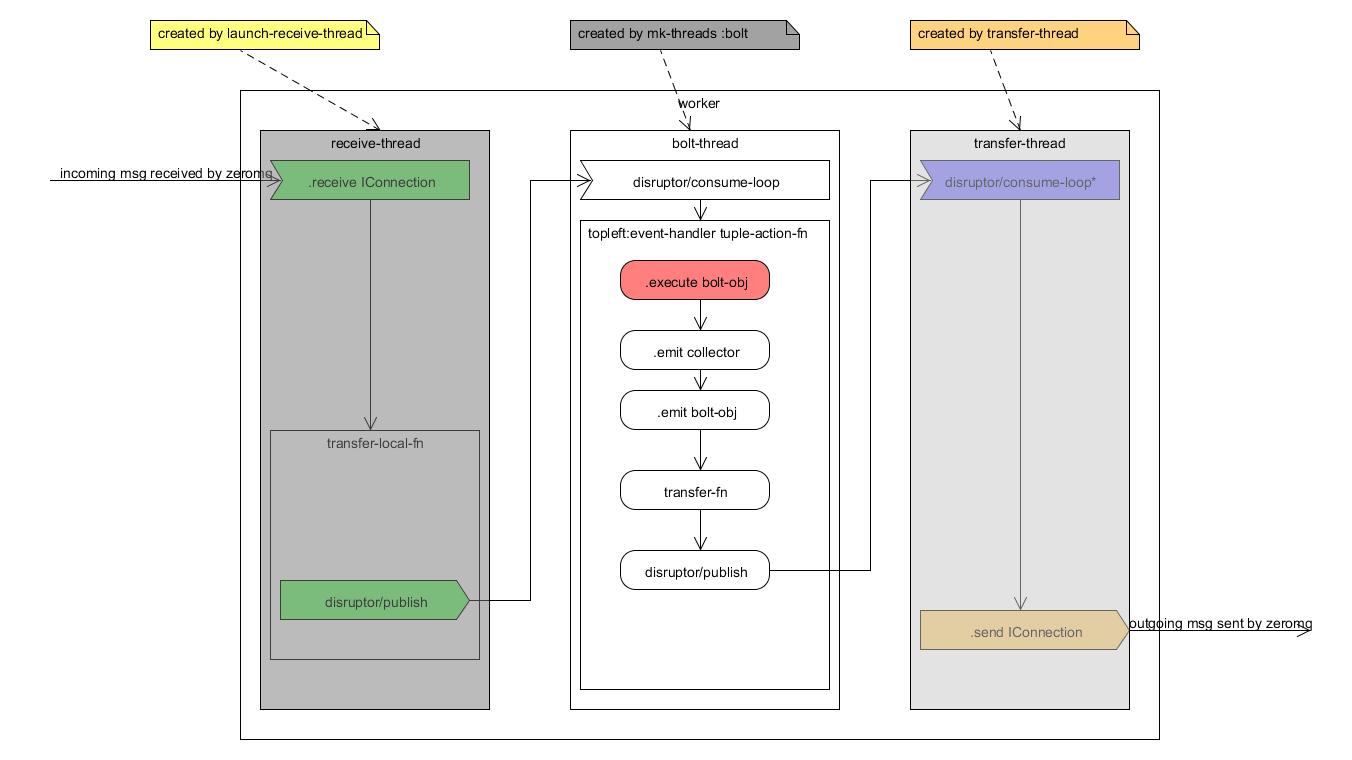
IConnection的建立与使用
话说在mk-threads :bolt函数的实现中有这么一段代码,其主要功能是实现tuple的emit功能
bolt-emit (fn [stream anchors values task]
(let [out-tasks (if task
(tasks-fn task stream values)
(tasks-fn stream values))]
(fast-list-iter [t out-tasks]
(let [anchors-to-ids (HashMap.)]
(fast-list-iter [^TupleImpl a anchors]
(let [root-ids (-> a .getMessageId .getAnchorsToIds .keySet)]
(when (pos? (count root-ids))
(let [edge-id (MessageId/generateId rand)]
(.updateAckVal a edge-id)
(fast-list-iter [root-id root-ids]
(put-xor! anchors-to-ids root-id edge-id))
))))
(transfer-fn t
(TupleImpl. worker-context
values
task-id
stream
(MessageId/makeId anchors-to-ids)))))
(or out-tasks [])))
加亮为蓝色的部分实现的功能是另外发送tuple,那么transfer-fn函数的定义在哪呢?见mk-threads的let部分,能见到下述一行代码
:transfer-fn (mk-executor-transfer-fn batch-transfer->worker)
在继续往下看每个函数实现之前,先确定一下这节代码阅读的目的。storm在线程之间使用disruptor进行通讯,在进程之间进行消息通讯使用的是zeromq或netty, 所以需要从transfer-fn追踪到使用zeromq或netty api的位置。
再看mk-executor-transfer-fn函数实现
(defn mk-executor-transfer-fn [batch-transfer->worker]
(fn this
([task tuple block? ^List overflow-buffer]
(if (and overflow-buffer (not (.isEmpty overflow-buffer)))
(.add overflow-buffer [task tuple])
(try-cause
(disruptor/publish batch-transfer->worker [task tuple] block?)
(catch InsufficientCapacityException e
(if overflow-buffer
(.add overflow-buffer [task tuple])
(throw e))
))))
([task tuple overflow-buffer]
(this task tuple (nil? overflow-buffer) overflow-buffer))
([task tuple]
(this task tuple nil)
)))
disruptor/publish表示将消息从本线程发送出去,至于谁是该消息的接收者,请继续往下看。
worker进程中,有一个receiver-thread是用来专门接收来自外部进程的消息,那么与之相对的是有一个transfer-thread用来将本进程的消息发送给外部进程。所以刚才的disruptor/publish发送出来的消息应该被transfer-thread接收到。
在transfer-thread中,能找到这行下述一行代码
transfer-thread (disruptor/consume-loop* (:transfer-queue worker) transfer-tuples)
对于接收到来自本进程中其它线程发送过来的消息利用transfer-tuples进行处理,transfer-tuples使用mk-transfer-tuples-handler来创建,所以需要看看mk-transfer-tuples-handler能否与zeromq或netty联系上呢?
(defn mk-transfer-tuples-handler [worker]
(let [^DisruptorQueue transfer-queue (:transfer-queue worker)
drainer (ArrayList.)
node+port->socket (:cached-node+port->socket worker)
task->node+port (:cached-task->node+port worker)
endpoint-socket-lock (:endpoint-socket-lock worker)
]
(disruptor/clojure-handler
(fn [packets _ batch-end?]
(.addAll drainer packets)
(when batch-end?
(read-locked endpoint-socket-lock
(let [node+port->socket @node+port->socket
task->node+port @task->node+port]
;; consider doing some automatic batching here (would need to not be serialized at this point to remo
;; try using multipart messages ... first sort the tuples by the target node (without changing the lo
17
(fast-list-iter [[task ser-tuple] drainer]
;; TODO: consider write a batch of tuples here to every target worker
;; group by node+port, do multipart send
(let [node-port (get task->node+port task)]
(when node-port
(.send ^IConnection (get node+port->socket node-port) task ser-tuple))
))))
(.clear drainer))))))
上述代码中出现了与zeromq可能有联系的部分了即加亮为红色的一行。
那凭什么说加亮的IConnection一行与zeromq有关系的,这话得慢慢说起,需要从配置文件开始。
在storm.yaml中有这么一行配置项,即
storm.messaging.transport: "backtype.storm.messaging.zmq"
这个配置项与worker中的mqcontext相对应,所以在worker中以mqcontext为线索,就能够一步步找到IConnection的实现。connections在函数mk-refresh-connections中建立
refresh-connections (mk-refresh-connections worker)
mk-refresh-connection函数中与mq-context相关联的一部分代码如下所示
(swap! (:cached-node+port->socket worker)
#(HashMap. (merge (into {} %1) %2))
(into {}
(dofor [endpoint-str new-connections
:let [[node port] (string->endpoint endpoint-str)]]
[endpoint-str
(.connect
^IContext (:mq-context worker)
storm-id
((:node->host assignment) node)
port)
]
)))
注意加亮部分,利用mq-conext中connect函数来创建IConnection. 当打开zmq.clj时候,就能验证我们的猜测。
(^IConnection connect [this ^String storm-id ^String host ^int port]
(require 'backtype.storm.messaging.zmq)
(-> context
(mq/socket mq/push)
(mq/set-hwm hwm)
(mq/set-linger linger-ms)
(mq/connect (get-connect-zmq-url local? host port))
mk-connection))
代码走到这里,IConnection什么时候建立起来的谜底就揭开了,消息是如何从bolt或spout线程传递到transfer-thread,再由zeromq将tuple发送给下跳的路径打通了。
tuple的分发策略 grouping
从一个bolt中产生的tuple可以有多个bolt接收,到底发送给哪一个bolt呢?这牵扯到分发策略问题,其实在twitter storm中有两个层面的分发策略问题,一个是对于task level的,在讲topology submit的时候已经涉及到。另一个就是现在要讨论的针对tuple level的分发。
再次将视线拉回到bolt-emit中,这次将目光集中在变量t的前前后后。
(let [out-tasks (if task
(tasks-fn task stream values)
(tasks-fn stream values))]
(fast-list-iter [t out-tasks]
(let [anchors-to-ids (HashMap.)]
(fast-list-iter [^TupleImpl a anchors]
(let [root-ids (-> a .getMessageId .getAnchorsToIds .keySet)]
(when (pos? (count root-ids))
(let [edge-id (MessageId/generateId rand)]
(.updateAckVal a edge-id)
(fast-list-iter [root-id root-ids]
(put-xor! anchors-to-ids root-id edge-id))
))))
(transfer-fn t
(TupleImpl. worker-context
values
task-id
stream
(MessageId/makeId anchors-to-ids)))))
上述代码显示t从out-tasks来,而out-tasks是tasks-fn的返回值
tasks-fn (:tasks-fn task-data)
一谈tasks-fn,原来从未涉及的文件task.clj这次被挂上了,task-data与由task/mk-task创建。将中间环节跳过,调用关系如下所列。
- mk-task
- mk-task-data
- mk-tasks-fn
tasks-fn中会使用到grouping,处理代码如下
fn ([^Integer out-task-id ^String stream ^List values]
(when debug?
(log-message "Emitting direct: " out-task-id "; " component-id " " stream " " values))
(let [target-component (.getComponentId worker-context out-task-id)
component->grouping (get stream->component->grouper stream)
grouping (get component->grouping target-component)
out-task-id (if grouping out-task-id)]
(when (and (not-nil? grouping) (not= :direct grouping))
(throw (IllegalArgumentException. "Cannot emitDirect to a task expecting a regular grouping")))
(apply-hooks user-context .emit (EmitInfo. values stream task-id [out-task-id]))
(when (emit-sampler)
(builtin-metrics/emitted-tuple! (:builtin-metrics task-data) executor-stats stream)
(stats/emitted-tuple! executor-stats stream)
(if out-task-id
(stats/transferred-tuples! executor-stats stream 1)
(builtin-metrics/transferred-tuple! (:builtin-metrics task-data) executor-stats stream 1)))
(if out-task-id [out-task-id])
))
而每个topology中的grouping策略又是如何被executor知道的呢,这从另一端executor-data说起。
在mk-executor-data中有下面一行代码
:stream->component->grouper (outbound-components worker-context component-id)
outbound-components的定义如下
(defn outbound-components
"Returns map of stream id to component id to grouper"
[^WorkerTopologyContext worker-context component-id]
(->> (.getTargets worker-context component-id)
clojurify-structure
(map (fn [[stream-id component->grouping]]
[stream-id
(outbound-groupings
worker-context
component-id
stream-id
(.getComponentOutputFields worker-context component-id stream-id)
component->grouping)]))
(into {})
(HashMap.)))
twitter storm源码走读之2 -- tuple消息发送场景分析的更多相关文章
- twitter storm 源码走读之5 -- worker进程内部消息传递处理和数据结构分析
欢迎转载,转载请注明出处,徽沪一郎. 本文从外部消息在worker进程内部的转化,传递及处理过程入手,一步步分析在worker-data中的数据项存在的原因和意义.试图从代码实现的角度来回答,如果是从 ...
- twitter storm源码走读之3--topology提交过程分析
概要 storm cluster可以想像成为一个工厂,nimbus主要负责从外部接收订单和任务分配.除了从外部接单,nimbus还要将这些外部订单转换成为内部工作分配,这个时候nimbus充当了调度室 ...
- twitter storm源码走读之7 -- trident topology可靠性分析
欢迎转载,转载请注明出处,徽沪一郎. 本文详细分析TridentTopology的可靠性实现, TridentTopology通过transactional spout与transactional s ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- twitter storm源码走读之1 -- nimbus启动场景分析
欢迎转载,转载时请注明作者徽沪一郎及出处,谢谢. 本文详细介绍了twitter storm中的nimbus节点的启动场景,分析nimbus是如何一步步实现定义于storm.thrift中的servic ...
- twitter storm源码走读之6 -- Trident Topology执行过程分析
欢迎转载,转载请注明出处,徽沪一郎. TridentTopology是storm提供的高层使用接口,常见的一些SQL中的操作在tridenttopology提供的api中都有类似的影射.关于Tride ...
- twitter storm源码走读之8 -- TridentTopology创建过程详解
欢迎转载,转载请注明出处,徽沪一郎. 从用户层面来看TridentTopology,有两个重要的概念一是Stream,另一个是作用于Stream上的各种Operation.在实现层面来看,无论是str ...
- 【原】storm源码之mac os x编译twitter storm源码
twitter storm是由backtype公司创始人nathanmarz一手研发和开源的流计算(实时计算)框架,堪称实时计算领域的hadoop.nathanmarz也是在mac os x环境下开发 ...
- Apache Spark源码走读之5 -- DStream处理的容错性分析
欢迎转载,转载请注明出处,徽沪一郎,谢谢. 在流数据的处理过程中,为了保证处理结果的可信度(不能多算,也不能漏算),需要做到对所有的输入数据有且仅有一次处理.在Spark Streaming的处理机制 ...
随机推荐
- 解决remove @override annotation(jdk1.5和jdk1.6)
在@override注释在jdk1.5环境下只能用于对继承的类的方法的重写,而不能用于对实现的接口中的方法的实现. 解决方法: 删除 @override
- 失恋28天-缝补礼物(codevs 2503)
2503 失恋28天-缝补礼物 时间限制: 1 s 空间限制: 32000 KB 题目等级 : 黄金 Gold 题解 查看运行结果 题目描述 Description 话说上回他给女孩送 ...
- jQuery常规选择器
//简单选择器$('div').css('color','red'); //元素选择器,返回多个元素$('#box').css('color','red');//id选择器,返回单个元素$('.box ...
- 企业级项目中最常用到的SQL
用SQL语句添加删除修改字段 1.增加字段 alter table docdsp add dspcode char(200) 例如: 表gwamis.d410Sctzmx添加字段f410 ...
- [原]AppPoolService-IIS应用程序池辅助类(C#控制应用程序池操作)
using System.Collections.Generic; using System.DirectoryServices; using System.Linq; using Microsoft ...
- oracle 执行计划详解
简介: 本文全面详细介绍oracle执行计划的相关的概念,访问数据的存取方法,表之间的连接等内容. 并有总结和概述,便于理解与记忆! +++ 目录 --- 一.相关的概念 ...
- Hark的数据结构与算法练习之归并排序
算法说明: 归并排序的思路就是分而治之,将数组中的数字递归折半进行排序. 递归到最底层就只剩下有两个数字进行比较,再从底层往下进行排序合并.最终得出结果. 同样,语言描述可能对于不知道这个算法的人来说 ...
- [转]关于int整形变量占有字节问题
int的长度由处理器(16位,32位,64位)和比哪一期决定. 首先从处理器来讲 :16位处理器中的int 占有16位 即2个字节 32位处理器中int ...
- Oracle TNS配置浅析
1. 什么是TNS? TNS是Oracle Net的一部分,专门用来管理和配置Oracle数据库和客户端连接的一个工具,在大多数情况下客户端和数据库要通讯,必须配置TNS,当然在少数情况下,不用配置T ...
- sql截取查询
select left(songno,3) as songno from song //截取前3位 select distinct right(left(songno,6),3) as Files ...