The mean shift clustering algorithm
The mean shift clustering algorithm
MEAN SHIFT CLUSTERING
Mean shift clustering is a general non-parametric cluster finding procedure — introduced by Fukunaga and Hostetler [1], and popular within the computer vision field.
Nicely, and in contrast to the more-well-known K-means clustering algorithm, the output of mean shift does not depend on any explicit assumptions on the shape of the point distribution, the number of clusters, or any form of random initialization.
We describe the mean shift algorithm in some detail in the technical background sectionat the end of this post. However, its essence is readily explained in a few
words: Essentially, mean shift treats the clustering problem by supposing that all points given represent samples from some underlying probability density function, with regions of high sample density corresponding to the local maxima of this distribution.
To find these local maxima, the algorithm works by allowing the points to attract each other, via what might be considered a short-ranged “gravitational” force. Allowing the points to gravitate towards areas of higher density, one can show that they will eventually
coalesce at a series of points, close to the local maxima of the distribution. Those data points that converge to the same local maxima are considered to be members of the same cluster.
In the next couple of sections, we illustrate application of the algorithm to a couple of problems. We make use of the python package SkLearn, which contains a mean shift
implementation. Following this, we provide a quick discussion and an appendix on technical details.
Follow @efavdb
Follow us on twitter for new submission alerts!
MEAN SHIFT CLUSTERING IN ACTION
In today’s post we will have two examples. First, we will show how to use mean shift clustering to identify clusters of data in a 2D data set. Second, we will use the algorithm to segment a picture based on the colors in the image. To do this we need a handful
of libraries from sklearn, numpy, matplotlib, and the Python Imaging Library (PIL) to handle reading in a jpeg image.
|
1
2
3
4
5
6
|
importnumpy as npfromsklearn.cluster importMeanShift, estimate_bandwidthfromsklearn.datasets.samples_generator importmake_blobsimportmatplotlib.pyplot as pltfromitertools importcyclefromPIL importImage |
FINDING CLUSTERS IN A 2D DATA SET
This first example is based off of the sklearn tutorial for mean shift clustering: We generate data points centered at 4 locations,
making use of sklearn’s make_blobs library. To apply the clustering algorithm to the points generated, we must first set the attractive interaction length between examples, also know as the algorithm’s bandwidth. Sklearn’s implementation contains a built-in
function that allows it to automatically estimate a reasonable value for this, based upon the typical distance between examples. We make use of that below, carry out the clustering, and then plot the results.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
#%% Generate sample datacenters= 1,1], [-.75,-1], [1,-1], [-3,2]]X, _= =10000, centers=centers,=0.6)#%% Compute clustering with MeanShift# The bandwidth can be automatically estimatedbandwidth= =.1, n_samples=500)ms= =bandwidth, bin_seeding=True)ms.fit(X)labels= cluster_centers= n_clusters_= max()+1#%% Plot resultplt.figure(1)plt.clf()colors= 'bgrcmykbgrcmykbgrcmykbgrcmyk')fork, col inzip(range(n_clusters_), colors): my_members= ==k cluster_center= plt.plot(X[my_members,0], X[my_members,1], col+ ) plt.plot(cluster_center[0], cluster_center[1], 'o', markerfacecolor=col, markeredgecolor='k',=14)plt.title('Estimated number of clusters: %d'% plt.show() |
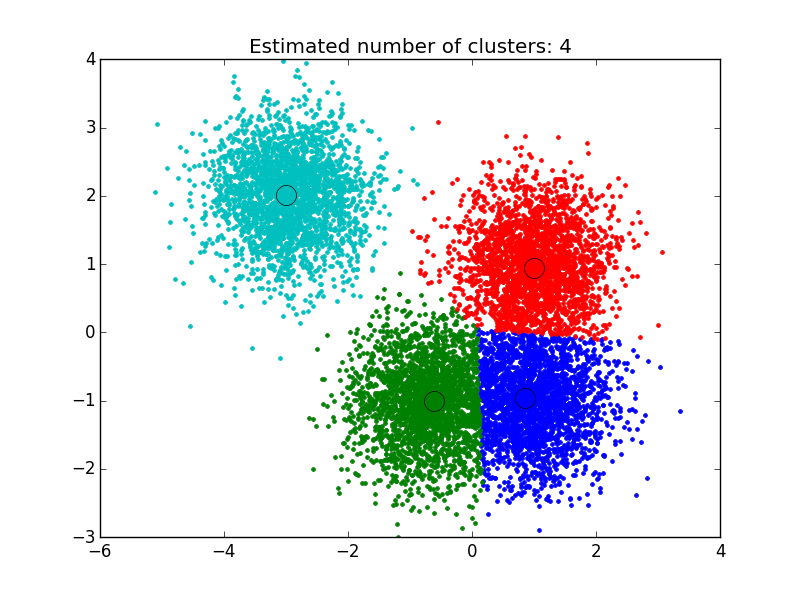
As you can see below, the algorithm has found clusters centered on each of the blobs we generated.
SEGMENTING A COLOR PHOTO
In the first example, we were using mean shift clustering to look for spatial clusters. In our second example, we will instead explore 3D color space, RGB, by considering pixel values taken from an image of a toy car. The procedure is similar — here, we cluster
points in 3d, but instead of having data(x,y) we have data(r,g,b) taken from the image’s RGB pixel values. Clustering these color values in this 3d space returns a series of clusters, where the pixels in those clusters are similar in RGB space. Recoloring
pixels according to their cluster, we obtain a segmentation of the original image.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#%% Part 2: Color image segmentation using mean shiftimage= open('toy.jpg')image= #Need to convert image into feature array based#on rgb intensitiesflat_image=np.reshape(image, [-1,3])#Estimate bandwidthbandwidth2= quantile=.2,=500)ms= =True)ms.fit(flat_image)labels=ms.labels_# Plot image vs segmented imageplt.figure(2)plt.subplot(2,1,1)plt.imshow(image)plt.axis('off')plt.subplot(2,1,2)plt.imshow(np.reshape(labels, [851,1280]))plt.axis('off') |
The bottom image below illustrates that one can effectively use this approach to identify the key shapes within an image, all without doing any image processing to get rid of glare or background — pretty great!

DISCUSSION
Although mean shift is a reasonably versatile algorithm, it has primarily been applied to problems in computer vision, where it has been used for image segmentation, clustering, and video tracking. Application to big data problems can be challenging due to
the fact the algorithm can become relatively slow in this limit. However, research is presently underway to speed up its convergence, which should enable its application to larger data sets.
Mean shift pros:
- No assumptions on the shape or number of data clusters.
- The procedure only has one parameter, the bandwidth.
- Output doesn’t depend on initializations.
Mean shift cons:
- Output does depend on bandwidth: too small and convergence is slow, too large and some clusters may be missed.
- Computationally expensive for large feature spaces.
- Often slower than K-Means clustering
Technical details follow.
TECHNICAL BACKGROUND
KERNEL DENSITY ESTIMATION
A general formulation of the mean shift algorithm can be developed through consideration of density kernels. These effectively work by smearing out each point example in space over some small window. Summing up the mass from each of these smeared units gives
an estimate for the probability density at every point in space (by smearing, we are able to obtain estimates at locations that do not sit exactly atop any example). This approach is often referred to as kernel
density estimation — a method for density estimation that often converges more quickly than binning, or histogramming, and one that also nicely returns a continuous estimate for the density function.
To illustrate, suppose we are given a data set {ui} of
points in d-dimensional space, sampled from some larger population, and that we have chosen a kernel K having
bandwidth parameter h.
Together, these data and kernel function return the following kernel density estimator for the full population’s density function
The kernel (smearing) function here is required to satisfy the following two conditions:
- ∫K(u)du=1
- K(u)=K(|u|) for
all values of u
The first requirement is needed to ensure that our estimate is normalized, and the second is associated with the symmetry of our space. Two popular kernel functions that satisfy these conditions are given by
- Flat/Uniform K(u)=12{10−1≤|u|≤1else
- Gaussian = K(u)=1(2π)d/2e−12|u|2
Below we plot an example in 1-d using the gaussian kernel to estimate the density of some population along the x-axis. You can see that each sample point adds a small Gaussian to our estimate, centered about it: The equations above may look a bit intimidating,
but the graphic here should clarify that the concept is pretty straightforward.

Example of a kernel density estimation using a gaussian kernel for each data point: Adding up small Gaussians about each example returns our net estimate for the total density, the black curve.
MEAN SHIFT ALGORITHM
Recall that the basic goal of the mean shift algorithm is to move particles in the direction of local increasing density. To obtain an estimate for this direction, a gradient is applied to the kernel density estimate discussed above. Assuming an angularly symmetric
kernel function, K(u)=K(|u|),
one can show that this gradient takes the form
where
and g(|u|)=−K′(|u|) is
the derivative of the selected kernel profile. The vector m(u)here,
called the mean shift vector, points in the direction of increasing density — the direction we must move our example. With this estimate, then, the mean shift algorithm protocol becomes
- Compute the mean shift vector m(ui),
evaluated at the location of each training example ui - Move each example from ui→ui+m(ui)
- Repeat until convergence — ie, until the particles have reached equilibrium.
As a final step, one determines which examples have ended up at the same points, marking them as members of the same cluster.
For a proof of convergence and further mathematical details, see Comaniciu & Meer (2002) [2].
1. Fukunaga and Hostetler, “The Estimation of the Gradient of a Density Function, with Applications in Pattern Recognition”, IEEE Transactions on Information Theory vol 21 , pp 32-40 ,1975
2. Dorin Comaniciu and Peter Meer, Mean Shift : A Robust approach towards feature space analysis, IEEE Transactions on Pattern Analysis and Machine Intelligence vol 24 No 5 May 2002.
The mean shift clustering algorithm的更多相关文章
- Machine Learning—The k-means clustering algorithm
印象笔记同步分享:Machine Learning-The k-means clustering algorithm
- AP聚类算法(Affinity propagation Clustering Algorithm )
AP聚类算法是基于数据点间的"信息传递"的一种聚类算法.与k-均值算法或k中心点算法不同,AP算法不需要在运行算法之前确定聚类的个数.AP算法寻找的"examplars& ...
- Clustering by density peaks and distance
这次介绍的是Alex和Alessandro于2014年发表在的Science上的一篇关于聚类的文章[13],该文章的基本思想很简单,但是其聚类效果却兼具了谱聚类(Spectral Clustering ...
- 挑子学习笔记:两步聚类算法(TwoStep Cluster Algorithm)——改进的BIRCH算法
转载请标明出处:http://www.cnblogs.com/tiaozistudy/p/twostep_cluster_algorithm.html 两步聚类算法是在SPSS Modeler中使用的 ...
- Study notes for Clustering and K-means
1. Clustering Analysis Clustering is the process of grouping a set of (unlabeled) data objects into ...
- DBSCAN(Density-based spatial clustering of applications with noise)
Density-based spatial clustering of applications with noise (DBSCAN) is a data clustering algorithm ...
- HDU 5489 Difference of Clustering 图论
Difference of Clustering Problem Description Given two clustering algorithms, the old and the new, y ...
- mean shift聚类算法的MATLAB程序
mean shift聚类算法的MATLAB程序 凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/ 1. mean shift 简介 mean shift, 写的 ...
- 基于K-means Clustering聚类算法对电商商户进行级别划分(含Octave仿真)
在从事电商做频道运营时,每到关键时间节点,大促前,季度末等等,我们要做的一件事情就是品牌池打分,更新所有店铺的等级.例如,所以的商户分入SKA,KA,普通店铺,新店铺这4个级别,对于不同级别的商户,会 ...
随机推荐
- Linux 网络编程九(select应用--大并发处理)
//网络编程服务端 /* * 备注:因为客户端代码.辅助方法代码和epoll相同,所以select只展示服务器端代码 */ #include <stdio.h> #include < ...
- ffplay 参数说明分享
ffplay 使用参数说明分享 E:\SRCFORTEST\software\ffmpeg-20131021\ffmpeg-20131021-git-712eff4-win32-static\ bin ...
- oracle中if/else功能的实现的3种写法
1.标准sql规范 一.单个IF 1. if a=... then ......... end if; 2. if a=... then ...... else .... end if; 二.多个IF ...
- Dottrace跟踪代码执行时间
当自己程序遇到性能问题,比如请求反应缓慢,怎么分析是哪里出了问题呢?dottrace可以帮助.net程序跟踪出代码里每个方法的执行时间,这样让我们更清晰的看出是哪里执行时间过长,然后再分析应该怎样解决 ...
- An Introduction to Interactive Programming in Python (Part 1) -- Week 2_3 练习
Mini-project description - Rock-paper-scissors-lizard-Spock Rock-paper-scissors is a hand game that ...
- Operators一句话介绍(RxJava版)
Cold Observables 在第一个subscriber订阅后才执行事件发送的Observables,默认普通Observables都是这个类型 Cold Observables对于每个订阅的s ...
- 安装.NET CORE
需要安装两个包 https://github.com/dotnet/cli 1. .NET Core Installer 2. .NET Core SDK Installer
- .tostring()格式化大全
C 货币 2.5.ToString("C") ¥2.50 D 十进制数 25.ToString("D5") 00025 E 科学型 25000.ToString ...
- Git.Framework 框架随手记--存储过程简化
在很多的ORM中对存储过程操作都是一个棘手的地方,因为存储过程是一段预编译的代码,其中可以包含很多处理过程.在Git.Framework中也同样存在这样的问题,目前没有能力解决这个问题.但是对于存储过 ...
- [USACO2003][poj2112]Optimal Milking(floyd+二分+二分图多重匹配)
http://poj.org/problem?id=2112 题意: 有K个挤奶器,C头奶牛,每个挤奶器最多能给M头奶牛挤奶. 每个挤奶器和奶牛之间都有一定距离. 求使C头奶牛头奶牛需要走的路程的最大 ...