Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货
文章为作者原创,未经许可,禁止转载。 -Sun Yat-sen University 冯兴伟
一、 项目简介:
电子商务的发展以及电商平台的多样化,类似于京东和天猫这种拥有过亿用户的在线购物网站,每天要处理的订单数堪称海量,更别提最近的双十一购物节,如此海量的订单数据阿里巴巴和京东是如何准确将用户信息和其订单匹配并配货的呢?答案是数据连接匹配。我的云计算项目idea也是来源于此。我们在做数据分析时常要连接从不同的数据源中获取到的数据,单机模式下的关系型数据库中我们会遇到这问题,同样在分布式系统中也不可避免的会有这种需求。故此,此次项目是用新的API实现在hadoop集群的MapReduce框架中编写程序实现数据的Join操作并模仿双十一订单配货来举例说明。
二、 MapReduce框架简析
MapReduce作为Hadoop的一个计算框架模型,在运行计算任务时,任务被大致分为读取数据分块,Map操作,Shuffle操作,Reduce操作,然后输出结果。
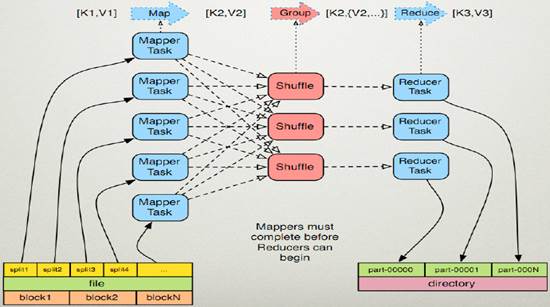
三、 项目预期说明及特色、创新
a. MapReduce输入(user文件和order文件)
存储有大量用户个人信息(用户ID,姓名,电话)的User文件,以下为部分数据示例:
|
U_ID Name Phone 14365 Lembr 287-797-6381 15347 Bawa 454-638-9400 16807 Yazdi 660-341-5047 19368 Wiela 759-382-4590 22591 DAgost 746-786-2796 25946 Liley 772-262-2520 |
存储有大量用户订单数据(用户ID,商品,价格,订单号,下单时间,送货地址)的Order文件,以下为部分数据示例:
|
U_ID Goods Prices Order_ID Time of Order Reserv Address 14365 blanket 98.36 370721695 11-Nov-2016 09:25:19 Garvey 8th Ave 15347 cushion 65.84 482597673 11-Nov-2016 20:20:06 Nogales 1st St 16807 quilt 11.58 408570985 11-Nov-2016 23:41:48 Castleton St 19368 cotton 24.00 342658162 11-Nov-2016 05:30:10 Gale 12rd Ave 22591 bedding 71.72 228726593 11-Nov-2016 13:12:29 Azusa Ave 25946 pillow 24.17 151469234 11-Nov-2016 15:13:45 Artesia Blvd |
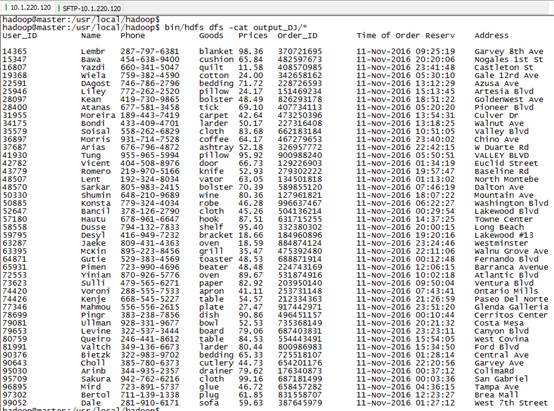
b. MapReduce预期输出:
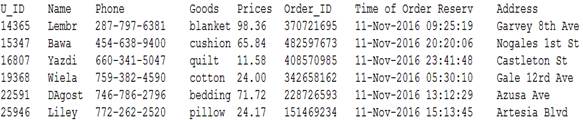
c. 从项目的预期输入我们看到,user和order分别来源于不同的数据源,我们要模仿订单配货的关键就是准确的匹配对应的用户的订单。User文件中只给了我们用户信息,而Order文件中给我们的只有用户在购买商品时登录用的用户ID以及订单的信息。虽然在上面的输入输出数据一一对应也很整齐,但是在实际输入数据文件中是很凌乱的,大量的数据靠肉眼是看不出来的,而我们仔细观察也只发现两个文件中唯一有联系的只有用户ID。这也是我们要做的根据不同文件的仅有的一个共同属性来进行数据连接操作。此项目的特色创新之处就在于用新的API实现了MapReduce框架下的海量数据连接Join操作,以及良好的应用到实际的在线购物订单配货例子中。
四、 程序设计描述
1. 程序的完整代码:
import java.io.IOException;
import java.util.*;
import java.io.DataInput;
import java.io.DataOutput;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Partitioner;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class DJoin
{
private static int first = 0;
public static class Map extends Mapper<LongWritable, Text, Text, Text>
{
private Text key = new Text();
private Text value = new Text();
private String[] keyValue = null; protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String line = value.toString();
if(line.contains("U_ID") == true)
{
return ;
} keyValue = line.split("\t",2);
this.key.set(keyValue[0]);
this.value.set(keyValue[1]);
context.write(this.key, this.value);
}
}
public static class Reduce extends Reducer<Text, Text, Text, Text>
{ private Text value = new Text();
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException
{
if(first == 0)
{
context.write(new Text("User_ID Name Phone Goods Prices Order_ID Time of Order Reserv Address "),null);
first++;
}
String valueStr ="";
String[] save = new String[2];
int i=0;
int j=2;
Iterator its =values.iterator();
while(j>0)
{
save[i++] = its.next().toString();
j--;
}
String one = save[0];
String two = save[1]; char flag = one.charAt(0);
if(flag>='a'&&flag<='z')
{
valueStr += "\t";
valueStr += two;
valueStr += "\t";
valueStr += one;
valueStr += "\t";
}
else
{
valueStr += "\t";
valueStr += one;
valueStr += "\t";
valueStr += two;
valueStr += "\t";
}
this.value.set(valueStr);
context.write(key, this.value);
} } public static void main(String[] args) throws Exception
{
Configuration conf = new Configuration();
args = new GenericOptionsParser(conf, args).getRemainingArgs();
if (args.length != 2) {
System.err.println("Usage: Djoin <input> <output>");
System.exit(2);
}
Job job = new Job(conf, "DJoin");
job.setJarByClass(DJoin.class);
job.setMapperClass(Map.class);
job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
2. 下面开始对主体代码进行解释
a) 实现map函数:
map函数首先进行的是行读取,如果是首行则跳过,之后用split分割行,将map操作输出的key值设为两表都有的用户ID,其他字段存储到value中输出。
|
public static class Map extends Mapper<LongWritable, Text, Text, Text>{ private Text key = new Text(); private Text value = new Text(); private String[] keyValue = null; protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException{ String line = value.toString(); if(line.contains("U_ID") == true) { return ; } keyValue = line.split("\t",2); this.key.set(keyValue[0]); this.value.set(keyValue[1]); context.write(this.key, this.value); } } |
b) 实现reduce函数:
reduce函数的输入也是key/value的形式,且其value是以迭代器形式,可以简单理解为一个key对应一组的value值。first是全局变量,用来输出表头的各项属性名。对map产生的每一组输出,map产生的key值直接输出到reduce的key值,而map产生的value进行迭代判断其数据来源是User表还是Order表之后进行连接Join操作。
|
public static class Reduce extends Reducer<Text, Text, Text, Text>{ private Text value = new Text(); protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { if(first == 0) { context.write(new Text("User_ID Name Phone Goods Prices Order_ID Time of Order Reserv Address "),null); first++; } String valueStr =""; String[] save = new String[2]; int i=0; int j=2; Iterator its =values.iterator(); while(j>0) { save[i++] = its.next().toString(); j--; } String one = save[0]; String two = save[1]; char flag = one.charAt(0); if(flag>='a'&&flag<='z') { valueStr += "\t"; valueStr += two; valueStr += "\t"; valueStr += one; valueStr += "\t"; } else { valueStr += "\t"; valueStr += one; valueStr += "\t"; valueStr += two; valueStr += "\t"; } this.value.set(valueStr); context.write(key, this.value); } } |
c) 实现main函数:
常规的新建job以及configuration的设置。
|
public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); args = new GenericOptionsParser(conf, args).getRemainingArgs(); if (args.length != 2) { System.err.println("Usage: Djoin <input> <output>"); System.exit(2); } Job = new Job(conf, "DJoin"); job.setJarByClass(DJoin.class); job.setMapperClass(Map.class); job.setReducerClass(Reduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } |
五、 程序编译及运行:
1) 检查jps,master的jps正常:
status检查正常:
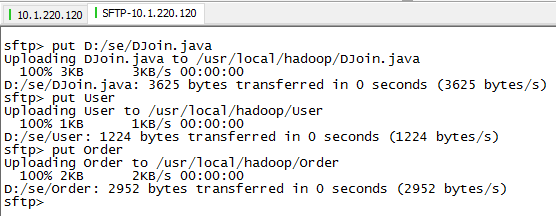
2) 从本机上传文件到品高云平台的虚拟机master上:
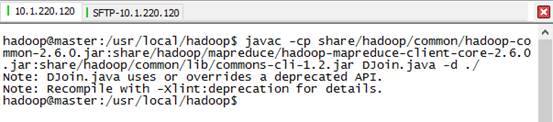
3) 编译DJoin.java
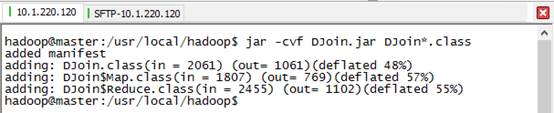
4) 打包成DJoin.jar
5) 在hdfs中创建/input/文件夹目录,放入输入文件:
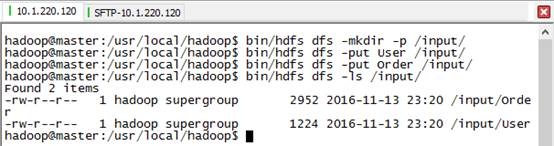
6) 运行DJoin任务:
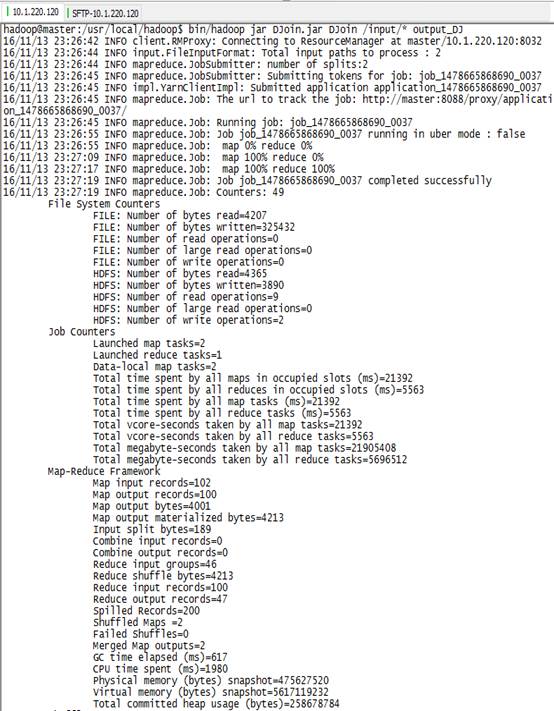
7) 查看程序输出:
Hadoop MapReduce例子-新版API多表连接Join之模仿订单配货的更多相关文章
- hadoop —— MapReduce例子 (数据去重)
参考:http://eric-gcm.iteye.com/blog/1807468 例子1: 概要:数据去重 描述:将file1.txt.file2.txt中的数据合并到一个文件中的同时去掉重复的内容 ...
- hadoop —— MapReduce例子 (求平均值)
参考:http://eric-gcm.iteye.com/blog/1807468 math.txt: 张三 88 李四 99 王五 66 赵六 77 china.txt: 张三 78 李四 89 王 ...
- hadoop —— MapReduce例子 (数据排序)
参考:http://eric-gcm.iteye.com/blog/1807468 file1.txt: 2 32 654 32 15 756 65223 file2.txt: 5956 22 650 ...
- 表连接join on
表A记录如下: aID aNum 1 a20050111 2 a20050112 3 a20050113 4 a20050114 5 a20050115 表B记录如下: bID bNa ...
- 性能调优7:多表连接 - join
在产品环境中,往往存在着大量的表连接情景,不管是inner join.outer join.cross join和full join(逻辑连接符号),在内部都会转化为物理连接(Physical Joi ...
- sql优化 表连接join方式
sql优化核心 是数据库中 解析器+优化器的工作,我觉得主要有以下几个大方面:1>扫表的方法(索引非索引.主键非主键.书签查.索引下推)2>关联表的方法(三种),关键是内存如何利用 ...
- sql表连接 —— join
一.内连接 —— INNER JOIN 内连接是最常见的一种连接,只连接匹配的行. 表1: 表2: 执行查询: select StudentId as 学生编号,StudentName as 姓名,G ...
- sql 表连接 join
inner join 和 join 的 区别 inner join 是内连接 ,查询出两边 都有的数据 join 是交叉 连接, 假设集合A={a, b},集合B={0, 1, 2},则两个集 ...
- SQL——表连接JOIN
JOIN - 用于根据两个或多个表中的列之间的关系,从这些表中查询数据. 语法:SELECT columnName(s) FROM tableName1 JOIN tableName2 -- 查 ...
随机推荐
- php中Closure::bind用法(手册记录)
手册中 Closure::bind — 复制一个闭包,绑定指定的$this对象和类作用域. 具体参数可以看手册,这里记录下这个方法的实际用处. <?php trait MetaTrait { p ...
- iOS工作笔记(十四)
1.scrollview的frame指的是其可视范围,contentSize指的是其滚动范围,分别是在水平方向和竖直方向上的 所以要让scrollview在水平方向不能滚动,那么需要如下设置 _scr ...
- asp.net用url重写URLReWriter实现任意二级域名
本文转自 http://www.cnblogs.com/notus/archive/2007/03/13/673222.html
- 如何将windows server 2008R2打造成桌面系统
>在工作中有没有遇到这样的情况,因某些应用需要使用到服务器版系统,为了方便就将自己的机器安装成服务器版,这样一来客户版系统的易用性和更好的体验就不能用了,有木有--呵呵,下面以windows s ...
- win2008server系统下文件替换权限
因为那里的文件默认只有系统才有修改权限.选中要替换的文件(一次只能选一个),属性->安全->高级->所有者(选更改)->高级->立即查找->选择 Everyone, ...
- Pig Hive对比(zz)
Pig Latin:数据流编程语言 一个Pig Latin程序是相对于输入的一步步操作.其中每一步都是对数据的一个简单的变换. 用Pig Latin编程更像在RDBMS中“查询规划器”(query p ...
- js之函数
1.倒计时定时器 timename=setTimeout("function()",delaytime); clearTimeout(timename); 2.循环定时器 time ...
- Jade之Code
Code jade支持内嵌js的代码到jade代码之中. Unbuffered Code 无缓冲代码以-符号开始,无任何额外输出(文本是什么即是什么). jade: - for (var x = 0; ...
- IT人士感言2(转)
01. 自己的户口档案.养老保险.医疗保险.住房公积金一定要保管好.由于程序员行业每年跳槽一次,我不隐瞒大家,我至少换过5个以上的单位,这期间跳来跳去,甚至是城市都换过3个.还好户口没丢掉,其他都已经 ...
- 黑马程序员_Java基础:多功能小窗口,swing,io,net综合应用
------- android培训.java培训.期待与您交流! ---------- 概念原理的理解,不代表能熟练应用. 如果将多个知识点关联并应用起来,这能加快我们对知识的掌握. 作为一个初学者, ...