7.2 Spark Streaming
一、Spark Streaming设计
Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。

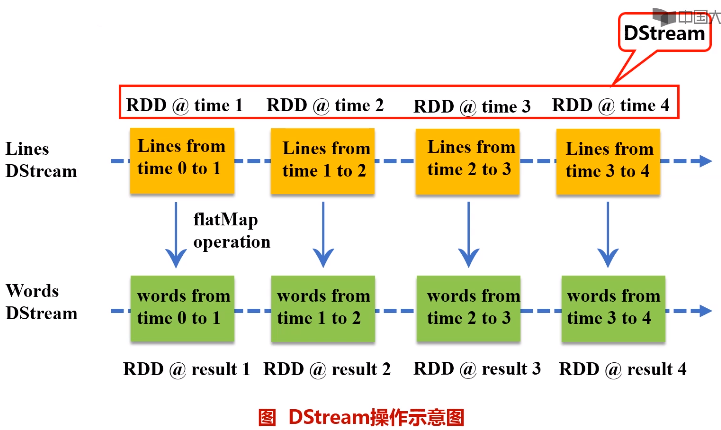
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据。

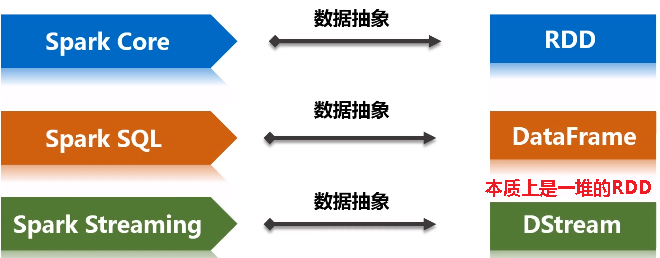
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作。
二、Spark Streaming与Storm的对比
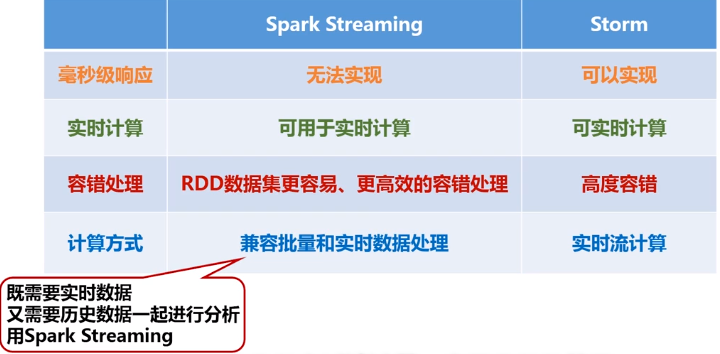
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理。
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合。
三、从“Hadoop+Storm”架构转向Spark架构
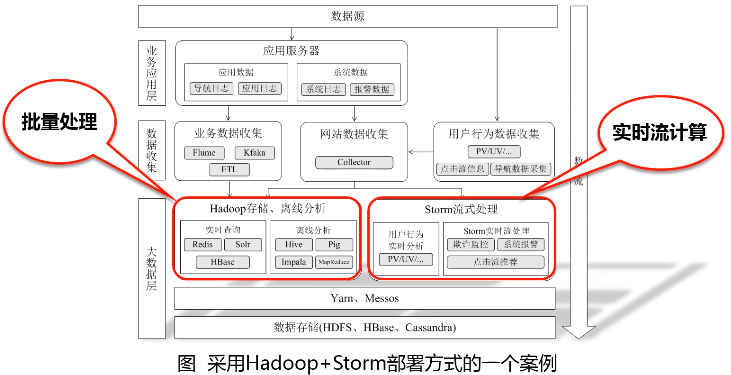
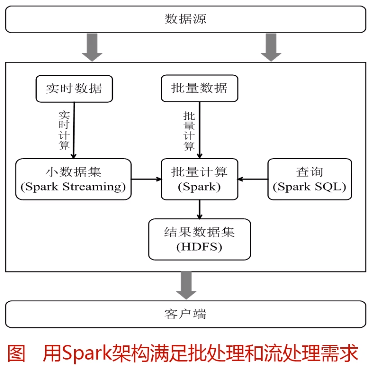

采用Spark架构具有如下优点:
- 实现一键式安装和配置、线程级别的任务监控和告警;
- 降低硬件集群、软件维护、任务监控和应用开发的难度;
- 便于做成统一的硬件、计算平台资源池。
7.2 Spark Streaming的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- Ubuntu下doxygen+graphviz使用概录
关键词:doxygen.Doxyfile.doxywizard.dot.graphviz等等. 使用doxygen从源码注释生成帮助文档或者SDK,输出格式有多种比如htmp.Latex等等. 如果想 ...
- LRU的实现(使用list)
首先是LRU的定义,LRU表示最近最少使用,如果数据最近被访问过,那么将来被访问的几率也更高. 所以逻辑应该是每次都要将新被访问的页放到列表头部,如果超过了list长度限制,就将列表尾部的元素踢出去. ...
- Druid-代码段-4-2
所属文章:池化技术(一)Druid是如何管理数据库连接的? 本代码段对应流程4.1,连接池瘦身: //连接池瘦身 public void shrink(boolean checkTime, boole ...
- python的路径问题
## 文件路径出错问题 """ 如何获取与当前文件相关的地址 """ import os # 当前文件的完整路径 print(__file_ ...
- acwing 110 防晒
https://www.acwing.com/problem/content/description/112/ 有C头奶牛进行日光浴,第i头奶牛需要minSPF[i]到maxSPF[i]单位强度之间的 ...
- WPF/C# 快捷键 自动生成方法
原文:WPF/C# 快捷键 自动生成方法 这一篇文章会很短~ 在写依赖属性的会后 propdb 会自动生成依赖属性所有的内容 但是如果我写属性变化通知的时候 希望有一个快捷键能自动生成方法 怎 ...
- IDEA debug工具使用
参考:https://www.cnblogs.com/jajian/p/9410844.html
- Eclipse Memory Analyzer(MAT),内存泄漏插件,安装使用一条龙
网上文档很多,但最初都有问题.整理一份,作为备份.使用过程:开发代码写完后,对可能出现内存溢出的代码,添加配置文件,生成.hprof文件,用memory Analyzer分析排查问题,且泄漏内存大小可 ...
- nacos+springboot的多环境使用方法
这里通过namespace的方法来实现,其他的没成功. 添加依赖 <dependency> <groupId>com.alibaba.boot</groupId> ...
- Python ASCII码与字符相互转换
ASCII ((American Standard Code for Information Interchange): 美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和 ...