7.2 Spark Streaming
一、Spark Streaming设计
Spark Streaming可整合多种输入数据源,如Kafka、Flume、HDFS,甚至是普通的TCP套接字。经处理后的数据可存储至文件系统、数据库,或显示在仪表盘里。

Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经Spark引擎以类似批处理的方式处理每个时间片数据。

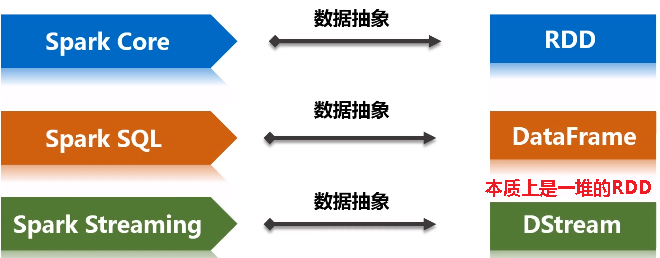
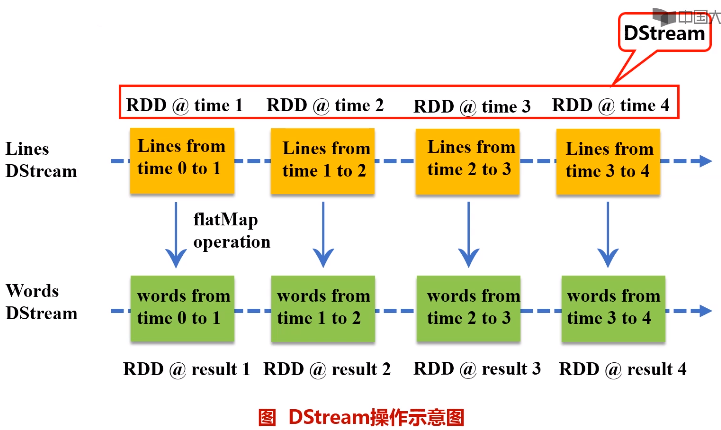
Spark Streaming最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1秒)分成一段一段,每一段数据转换为Spark中的RDD,这些分段就是Dstream,并且对DStream的操作都最终转变为对相应的RDD的操作。
二、Spark Streaming与Storm的对比
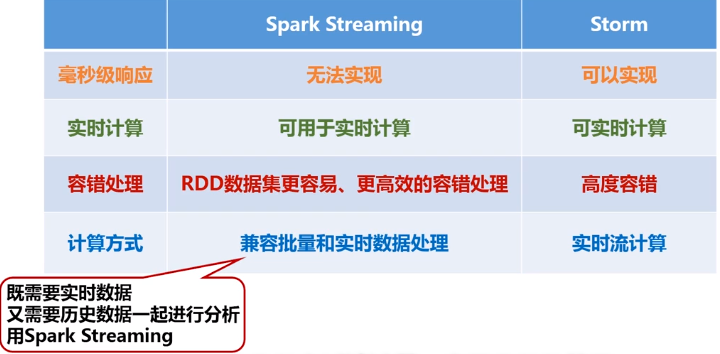
- Spark Streaming和Storm最大的区别在于,Spark Streaming无法实现毫秒级的流计算,而Storm可以实现毫秒级响应。
- Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎(100ms+)可以用于实时计算,另一方面,相比于Storm,RDD数据集更容易做高效的容错处理。
- Spark Streaming采用的小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法,因此,方便了一些需要历史数据和实时数据联合分析的特定应用场合。
三、从“Hadoop+Storm”架构转向Spark架构
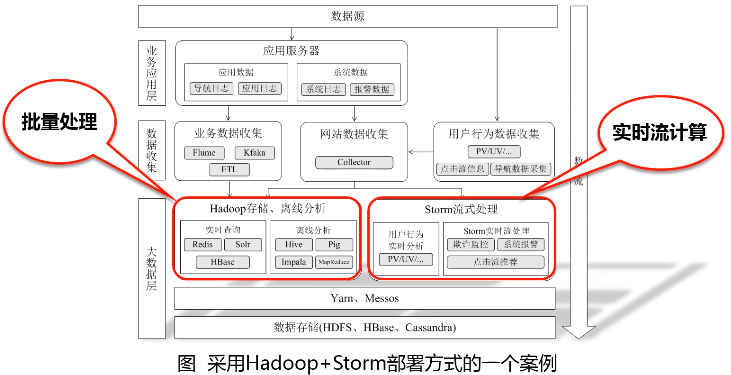
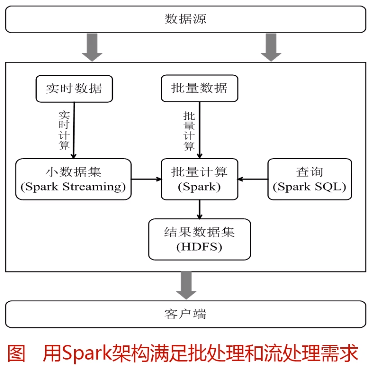

采用Spark架构具有如下优点:
- 实现一键式安装和配置、线程级别的任务监控和告警;
- 降低硬件集群、软件维护、任务监控和应用开发的难度;
- 便于做成统一的硬件、计算平台资源池。
7.2 Spark Streaming的更多相关文章
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark Streaming+Kafka
Spark Streaming+Kafka 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端, ...
- Storm介绍及与Spark Streaming对比
Storm介绍 Storm是由Twitter开源的分布式.高容错的实时处理系统,它的出现令持续不断的流计算变得容易,弥补了Hadoop批处理所不能满足的实时要求.Storm常用于在实时分析.在线机器学 ...
- flume+kafka+spark streaming整合
1.安装好flume2.安装好kafka3.安装好spark4.流程说明: 日志文件->flume->kafka->spark streaming flume输入:文件 flume输 ...
- spark streaming kafka example
// scalastyle:off println package org.apache.spark.examples.streaming import kafka.serializer.String ...
- Spark Streaming中动态Batch Size实现初探
本期内容 : BatchDuration与 Process Time 动态Batch Size Spark Streaming中有很多算子,是否每一个算子都是预期中的类似线性规律的时间消耗呢? 例如: ...
- Spark Streaming源码解读之No Receivers彻底思考
本期内容 : Direct Acess Kafka Spark Streaming接收数据现在支持的两种方式: 01. Receiver的方式来接收数据,及输入数据的控制 02. No Receive ...
- Spark Streaming架构设计和运行机制总结
本期内容 : Spark Streaming中的架构设计和运行机制 Spark Streaming深度思考 Spark Streaming的本质就是在RDD基础之上加上Time ,由Time不断的运行 ...
- Spark Streaming中空RDD处理及流处理程序优雅的停止
本期内容 : Spark Streaming中的空RDD处理 Spark Streaming程序的停止 由于Spark Streaming的每个BatchDuration都会不断的产生RDD,空RDD ...
- Spark Streaming源码解读之State管理之UpdataStateByKey和MapWithState解密
本期内容 : UpdateStateByKey解密 MapWithState解密 Spark Streaming是实现State状态管理因素: 01. Spark Streaming是按照整个Bach ...
随机推荐
- 对比keep-alive路由缓存设置的2种方式
方式有两种 .路由元信息(2.1.0版本之前) .属性方式(2.1.0版本之后新增) Vue2.1.0之前: 想实现类似的操作,你可以: 配置一下路由元信息 创建两个keep-alive标签 使用v- ...
- JMeter基础知识系列二
1.从web服务或其他远程服务的角度来看,Jmeter很像是一款浏览器,但实际他并不是浏览器,Jmeter支持浏览器的部分操作.如:Jmeter不支持hmtl页面中包含的JavaScript脚本.处理 ...
- 洛谷 P5640 【CSGRound2】逐梦者的初心
洛谷 P5640 [CSGRound2]逐梦者的初心 洛谷传送门 题目背景 注意:本题时限修改至250ms,并且数据进行大幅度加强.本题强制开启O2优化,并且不再重测,请大家自己重新提交. 由于Y校的 ...
- HDUNumber Sequence(KMP)
传送门 题目大意:b在a第一次出现的位置 题解:KMP 代码: #include<iostream> #include<cstdio> #include<cstring& ...
- Codeforces Round #602 (Div. 2, based on Technocup 2020 Elimination Round 3) F2. Wrong Answer on test 233 (Hard Version) dp 数学
F2. Wrong Answer on test 233 (Hard Version) Your program fails again. This time it gets "Wrong ...
- Codeforces Round #594 (Div. 1)
Preface 这场CF真是细节多的爆炸,B,C,F都是大细节题,每道题都写了好久的说 CSP前的打的最后一场比赛了吧,瞬间凉意满满 希望CSP可以狗住冬令营啊(再狗不住真没了) A. Ivan th ...
- Batchnorm原理详解
Batchnorm原理详解 前言:Batchnorm是深度网络中经常用到的加速神经网络训练,加速收敛速度及稳定性的算法,可以说是目前深度网络必不可少的一部分. 本文旨在用通俗易懂的语言,对深度学习的常 ...
- celery生产者-消费者
Celery是一个简单,灵活,可靠的分布式系统,用于处理大量消息,同时为操作提供维护此类系统所需的工具. 它是一个任务队列,专注于实时处理,同时还支持任务调度. celery解决了什么问题: 示例一: ...
- Java中的集合-您必须知道的13件事
Java Collections Framework是Java编程语言的核心部分之一.集合几乎用于任何编程语言中.大多数编程语言都支持各种类型的集合,例如List, Set, Queue, Stack ...
- java线程join方法使用方法简介
本博客简介介绍一下java线程的join方法,join方法是实现线程同步,可以将原本并行执行的多线程方法变成串行执行的 如图所示代码,是并行执行的 public class ThreadTest { ...