HBase —— 集群环境搭建
一、集群规划
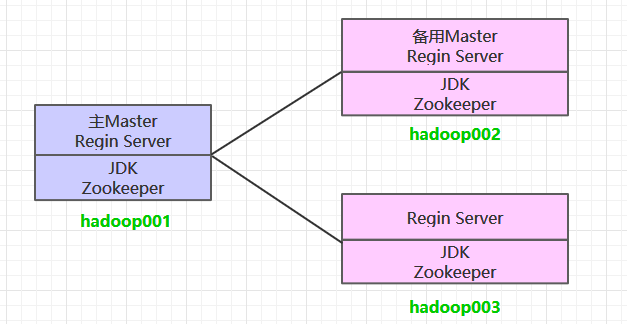
这里搭建一个3节点的HBase集群,其中三台主机上均为Regin Server。同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002上部署备用的Master服务。Master服务由Zookeeper集群进行协调管理,如果主Master不可用,则备用Master会成为新的主Master。
二、前置条件
HBase的运行需要依赖Hadoop和JDK(HBase 2.0+对应JDK 1.8+) 。同时为了保证高可用,这里我们不采用HBase内置的Zookeeper服务,而采用外置的Zookeeper集群。相关搭建步骤可以参阅:
三、集群搭建
3.1 下载并解压
下载并解压,这里我下载的是CDH版本HBase,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zxvf hbase-1.2.0-cdh5.15.2.tar.gz
3.2 配置环境变量
# vim /etc/profile
添加环境变量:
export HBASE_HOME=usr/app/hbase-1.2.0-cdh5.15.2
export PATH=$HBASE_HOME/bin:$PATH
使得配置的环境变量立即生效:
# source /etc/profile
3.3 集群配置
进入${HBASE_HOME}/conf目录下,修改配置:
1. hbase-env.sh
# 配置JDK安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201
# 不使用内置的zookeeper服务
export HBASE_MANAGES_ZK=false
2. hbase-site.xml
<configuration>
<property>
<!-- 指定hbase以分布式集群的方式运行 -->
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<!-- 指定hbase在HDFS上的存储位置 -->
<name>hbase.rootdir</name>
<value>hdfs://hadoop001:8020/hbase</value>
</property>
<property>
<!-- 指定zookeeper的地址-->
<name>hbase.zookeeper.quorum</name>
<value>hadoop001:2181,hadoop002:2181,hadoop003:2181</value>
</property>
</configuration>
3. regionservers
hadoop001
hadoop002
hadoop003
4. backup-masters
hadoop002
backup-masters这个文件是不存在的,需要新建,主要用来指明备用的master节点,可以是多个,这里我们以1个为例。
3.4 HDFS客户端配置
这里有一个可选的配置:如果您在Hadoop集群上进行了HDFS客户端配置的更改,比如将副本系数dfs.replication设置成5,则必须使用以下方法之一来使HBase知道,否则HBase将依旧使用默认的副本系数3来创建文件:
- Add a pointer to your
HADOOP_CONF_DIRto theHBASE_CLASSPATHenvironment variable in hbase-env.sh.- Add a copy of hdfs-site.xml (or hadoop-site.xml) or, better, symlinks, under ${HBASE_HOME}/conf, or
- if only a small set of HDFS client configurations, add them to hbase-site.xml.
以上是官方文档的说明,这里解释一下:
第一种 :将Hadoop配置文件的位置信息添加到hbase-env.sh的HBASE_CLASSPATH 属性,示例如下:
export HBASE_CLASSPATH=usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop
第二种 :将Hadoop的hdfs-site.xml或hadoop-site.xml 拷贝到 ${HBASE_HOME}/conf目录下,或者通过符号链接的方式。如果采用这种方式的话,建议将两者都拷贝或建立符号链接,示例如下:
# 拷贝
cp core-site.xml hdfs-site.xml /usr/app/hbase-1.2.0-cdh5.15.2/conf/
# 使用符号链接
ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/core-site.xml
ln -s /usr/app/hadoop-2.6.0-cdh5.15.2/etc/hadoop/hdfs-site.xml
注:
hadoop-site.xml这个配置文件现在叫做core-site.xml
第三种 :如果你只有少量更改,那么直接配置到hbase-site.xml中即可。
3.5 安装包分发
将HBase的安装包分发到其他服务器,分发后建议在这两台服务器上也配置一下HBase的环境变量。
scp -r /usr/app/hbase-1.2.0-cdh5.15.2/ hadoop002:usr/app/
scp -r /usr/app/hbase-1.2.0-cdh5.15.2/ hadoop003:usr/app/
四、启动集群
4.1 启动ZooKeeper集群
分别到三台服务器上启动ZooKeeper服务:
zkServer.sh start
4.2 启动Hadoop集群
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
4.3 启动HBase集群
进入hadoop001的${HBASE_HOME}/bin,使用以下命令启动HBase集群。执行此命令后,会在hadoop001上启动Master服务,在hadoop002上启动备用Master服务,在regionservers文件中配置的所有节点启动region server服务。
start-hbase.sh
4.5 查看服务
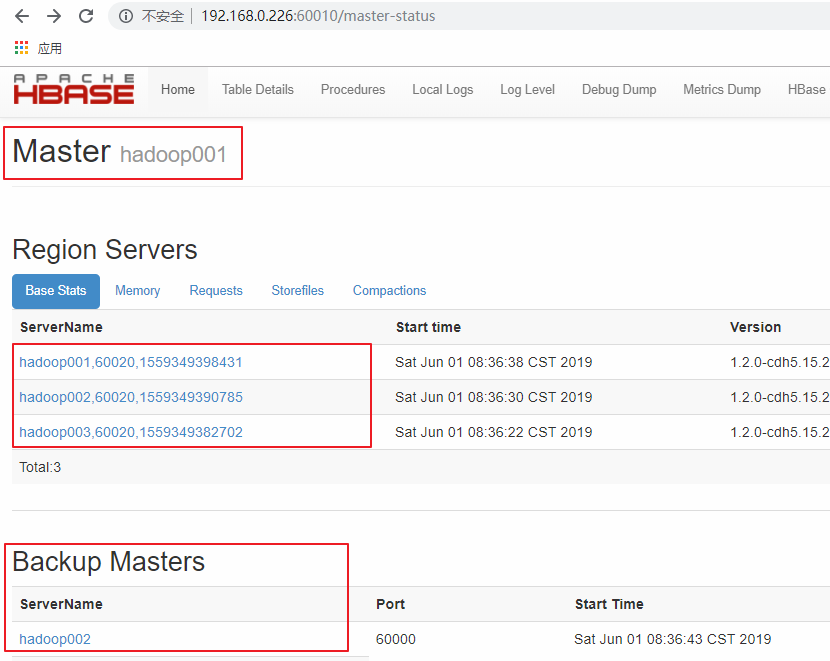
访问HBase的Web-UI界面,这里我安装的HBase版本为1.2,访问端口为60010,如果你安装的是2.0以上的版本,则访问端口号为16010。可以看到Master在hadoop001上,三个Regin Servers分别在hadoop001,hadoop002,和hadoop003上,并且还有一个Backup Matser 服务在 hadoop002上。
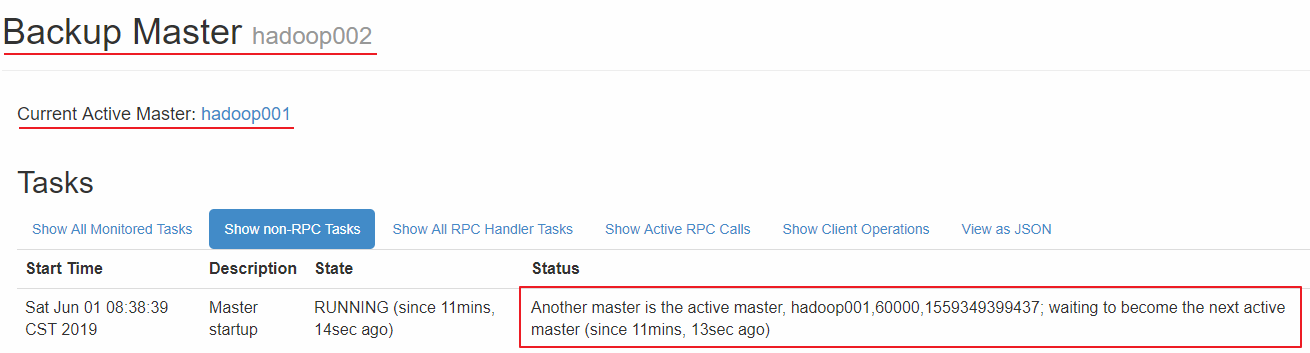
hadoop002 上的 HBase出于备用状态:
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
HBase —— 集群环境搭建的更多相关文章
- HBase集群环境搭建v2.0
本文档环境基于ubuntu16.04版本,如果最终不使用SuperMap iServer 10i ,可以不配置geomesa-hbase_2.11-2.2.0-bin.tar.gz 相比1.0版本,升 ...
- HBase集群环境搭建v1.0
本文档环境基于ubuntu14.04版本,如果最终不使用SuperMap iServer 9D ,可以不配置geomesa-hbase_2.11-2.0.1-bin.tar.gz (转发请注明出处:h ...
- 数据仓库组件:HBase集群环境搭建和应用案例
本文源码:GitHub || GitEE 一.Hbase简介 1.基础描述 Hadoop原生的特点是解决大规模数据的离线批量处理场景,HDFS具备强大存储能力,但是并没有提供很强的数据查询机制.HBa ...
- hadoop(八) - hbase集群环境搭建
1. 上传hbase安装包hbase-0.96.2-hadoop2-bin.tar.gz 2. 解压 tar -zxvf hbase-0.96.2-hadoop2-bin.tar.gz -C /clo ...
- Hbase集群环境搭建
Hbase数据库依赖 Hadoop和zookeeper,所以,安装Hbase之前,需要先把zookeeper集群搭建好.(当然,Hbase有内建的zookeeper,不过不建议使用).Hbase配置上 ...
- Hadoop,HBase集群环境搭建的问题集锦(四)
21.Schema.xml和solrconfig.xml配置文件里參数说明: 參考资料:http://www.hipony.com/post-610.html 22.执行时报错: 23., /comm ...
- Hadoop,HBase集群环境搭建的问题集锦(二)
10.艾玛, Datanode也启动不了了? 找到log: Caused by: java.net.UnknownHostException: Invalid host name: local hos ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Spark 集群环境搭建
思路: ①先在主机s0上安装Scala和Spark,然后复制到其它两台主机s1.s2 ②分别配置三台主机环境变量,并使用source命令使之立即生效 主机映射信息如下: 192.168.32.100 ...
随机推荐
- 创Python规划2
于Milang的IDE多年的编辑后,,然后按F5关于实施.这将是在下面Output输出形式"Hello, World!"弦,例如下面的附图: watermark/2/text/aH ...
- Opencv中K均值算法(K-Means)及其在图像分割中的应用
K均值(K-Means)算法是一种无监督的聚类学习算法,他尝试找到样本数据的自然类别,分类是K由用户自己定义,K均值在不需要任何其他先验知识的情况下,依据算法的迭代规则,把样本划分为K类.K均值是最常 ...
- python实现简易采集爬虫
#!/usr/bin/python #-*-coding:utf-8-*- # 简易采集爬虫 # 1.采集Yahoo!Answers,parseData函数修改一下,可以采集任何网站 # 2.需要sq ...
- IOS status bar
从iOS7开始,该系统提供2样的管理风格状态栏 由UIViewController管理(每UIViewController我们可以有各自不同的状态栏) 由UIApplication管理(由其统一管理的 ...
- BigTable介绍PPT
- Something write in FSE 2014
Now, I find a problem, I have become my personal CSDN into a personal electronic diary. Actually, th ...
- LeapMotion Demo3
原文:LeapMotion Demo3 从Github及其他论坛下载一些LeapMotion的例子,部分例子由于SDK的更新有一些小Bug, 已修复,感兴趣的可以下载: http:// ...
- jquery map()的用法--遍历数组
<!DOCTYPE html><html><head><meta http-equiv="Content-Type" content=&q ...
- Poco vs Boost(Poco也有不少优点,特别是网络功能更强)
POCO的优点: 1) 比boost更好的线程库,特别是一个活动的方法的实现,并且还可设置线程的优先级. 2) 比 boost:asio更全面的网络库.但是boost:asio也是一个非常好的网络库. ...
- 数据绑定(十一)多路绑定MultiBinding
原文:数据绑定(十一)多路绑定MultiBinding 有时候UI要显示的信息又不止一个数据来源决定,就需要使用MultiBinding,MultiBinding具有一个名为Bindings的属性,其 ...