数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定
数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定
需求1:对茅台股票分析
茅台股票分析
- 使用tushare包获取某股票的历史行情数据。
- tushare:财经数据接口包
- pip install tushare
- 输出该股票所有收盘比开盘上涨3%以上的日期。
- 输出该股票所有开盘比前日收盘跌幅超过2%的日期。
- 假如我从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,我的收益如何?
- 使用tushare包获取某股票的历史行情数据。
代码实现:
1.使用tushare包获取某股票的历史行情数据
import tushare as ts
import pandas as pd
from pandas import Series,DataFrame # 使用tushare包获取某股票的历史行情数据
df = ts.get_k_data('600519',start='1988-01-01')
# 将获取的数据写入到本地进行持久化存储
df.to_csv('./maotai.csv') # 将本地文本文件中的数据读取加载到DataFrame中
df = pd.read_csv('./maotai.csv')
df.head(10) # 将Unnamed: 0为无用的列删除
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
df.head(5) # 显示前五条,不写5默认也是显示的前5条,inplace是判断是否用新表替换原表 # 将date列转成时间序列类型
df['date'] = pd.to_datetime(df['date']) # 将date列作为元数据的行索引
df.set_index(df['date'],inplace=True) # 删除原date列
df.drop(labels='date',axis=1,inplace=True)
df.head()
2.输出该股票所有收盘比开盘上涨3%以上的日期。
# 伪代码:(收盘-开盘)/开盘 > 0.03
(df['close'] - df['open'])/df['open'] > 0.03 # boolean可以作为df的行索引
df.loc[[True,False,True]]
df.loc[(df['close'] - df['open'])/df['open'] > 0.03] df.loc[(df['close'] - df['open'])/df['open'] > 0.03].index
3.输出该股票所有开盘比前日收盘跌幅超过2%的日期
#伪代码:(开盘-前日收盘)/前日收盘 < -0.02 # 将收盘/close列下移一位,这样可以将open和close作用到一行,方便比较
(df['open'] - df['close'].shift(1))/df['close'].shift(1) < -0.02 # boolean作为df的行索引
df.loc[(df['open'] - df['close'].shift(1))/df['close'].shift(1) < -0.02] df.loc[(df['open'] - df['close'].shift(1))/df['close'].shift(1) < -0.02].index # shift(1):可以让一个Series中的数据整体下移一位
4.假如从2010年1月1日开始,每月第一个交易日买入1手股票,每年最后一个交易日卖出所有股票,到今天为止,收益如何?
分析:
买入:一个完整的年需要买12次股票,一次买入一手(100支),一个完整的年需要买入1200支股票
卖出:一个完整的年卖一次,一次卖出1200只股票
代码实现:
# 将2010-1-1 - 今天对应的交易数据取出
data = df['2010':'2019']
data.head() # 数据的重新取样,将每个月第一个交易日的数据拿到
data_monthly = data.resample('M').first() # 一共花了多少钱
cost_money = (data_monthly['open']*100).sum() # 卖出股票入手多少钱,将每年的最后一个交易日的数据拿到
data_yeasly = data.resample('A').last()[:-1]
recv_money = (data_yeasly['open']*1200).sum() # 19年手里剩余股票的价值也要计算到收益中
last_money = 1200*data['close'][-1] # 最后总收益如下:
last_monry + recv_money - cost_monry
需求2:双均线策略制定
双均线策略分析
- 什么是均线 / 均线一般说的是收盘价
对于每一个交易日,都可以计算出前N天的移动平均值,然后把这些移动平均值连起来,成为一条线,就叫做N日移动平均线。移动平均线常用线有5天、10天、30天、60天、120天和240天的指标。
5天和10天的是短线操作的参照指标,称做日均线指标;
30天和60天的是中期均线指标,称做季均线指标;
120天和240天的是长期均线指标,称做年均线指标。
均线计算方法:MA=(C1+C2+C3+...+Cn)/N C:某日收盘价 N:移动平均周期(天数) - 股票分析技术中的金叉和死叉,可以简单解释为:
分析指标中的两根线,一根为短时间内的指标线,另一根为较长时间的指标线。
如果短时间的指标线方向拐头向上,并且穿过了较长时间的指标线,这种状态叫“金叉”;
如果短时间的指标线方向拐头向下,并且穿过了较长时间的指标线,这种状态叫“死叉”;
一般情况下,出现金叉后,操作趋向买入;死叉则趋向卖出。当然,金叉和死叉只是分析指标之一,要和其他很多指标配合使用,才能增加操作的准确性。
- 什么是均线 / 均线一般说的是收盘价
代码实现
1.使用tushare包获取某股票的历史行情数据
import tushare as ts
import pandas as pd # 调用tushare接口,分析股票历史数据
df = ts.get_k_data('601318',start='1990-01-01') # 数据的预处理
# 将date列转换成时间序列
df['date'] = pd.to_datetime(df['date'])
# 将新的date时间序列,设置成索引,并替换原数据
df.set_index(df['date'],inplace=True)
# 删除掉原来的date列
df.drop(labels='date',axis=1,inplace=True)
# 取2010-2019区间的数据,2010之前的数据有NaN数据,会造成统计结果不准确
df = df['2010':'2019']
2.计算该股票历史数据的5日均线和30日均线
# rolling是第几个5天的值,mean()取均值
df['ma5'] = df['close'].rolling(5).mean()
df['ma30'] = df['close'].rolling(30).mean()
3.可视化历史数据两条均线
# 可视化历史数据两条均线,c代表颜色
import matplotlib.pyplot as plt
df_p = df[:300]
plt.plot(df_p.index,df_p['ma5'],c='red')
plt.plot(df_p.index,df_p['ma30'],c='blue')
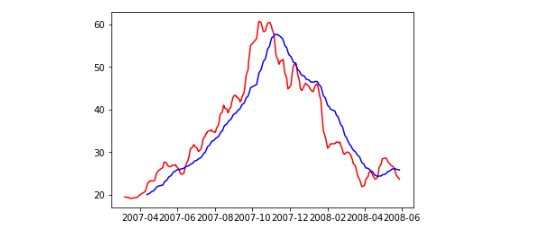
4.分析输出所有金叉日期和死叉日期
# True:短期均线 低于 长期均线
# False:短期均线 高于 长期均线
# True ---> False 的过渡,对应的点是金叉
# False ---> True 的过渡,对应的点是死叉
sr1 = df['ma5'] < df['ma30']
sr2 = df['ma5'] >= df['ma30'] # 捕获死叉所有的日期 按位与:&
death_date = df.loc[sr1 & sr2.shift(1)].index # 捕获所有的金叉日期 按位或:| 取反:~
golden_date = df.loc[~(sr1 | sr2.shift(1))].index
5.如果假如从开始,初始资金为100000元,金叉尽量买入,死叉全部卖出,则到今天为止,炒股收益率如何?
first_money = 100000 # 不变
money = first_money #可变的
hold = 0 # 目前所持有股票的数量(单位:支) from pandas import Series
s1 = Series(1,index=golden_date) # 存储的是为金叉日期,用1表示
s2 = Series(0,index=death_date) # 死叉日期,0表示
s = s1.append(s2)
s = s.sort_index() # 使用开盘价进行股票的买卖
for i in range(0,len(s)): # 2010-07-07
# 买入或卖出股票的单价:p
p = df['open'][s.index[i]]
if s[i] == 1: # 金叉日期:买入股票
buy = money // (p*100) # 买了多少手
hold = buy * 100
money -= buy*100*p
else: # 卖出
money += hold * p
hold = 0 money += hold * df['open'][-1]
result = money - first_money
print(result)
数据分析04 /基于pandas的DateFrame进行股票分析、双均线策略制定的更多相关文章
- 数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗.级联.合并 目录 数据分析03 /基于pandas的数据清洗.级联.合并 1. 处理丢失的数据 2. pandas处理空值操作 3. 数据清洗案例 4. 处 ...
- 基于pandas python的美团某商家的评论销售数据分析(可视化)
基于pandas python的美团某商家的评论销售数据分析 第一篇 数据初步的统计 本文是该可视化系列的第二篇 第三篇 数据中的评论数据用于自然语言处理 导入相关库 from pyecharts i ...
- 用Python的Pandas和Matplotlib绘制股票唐奇安通道,布林带通道和鳄鱼组线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- 用Python的Pandas和Matplotlib绘制股票KDJ指标线
我最近出了一本书,<基于股票大数据分析的Python入门实战 视频教学版>,京东链接:https://item.jd.com/69241653952.html,在其中给出了MACD,KDJ ...
- Python数据分析工具:Pandas之Series
Python数据分析工具:Pandas之Series Pandas概述Pandas是Python的一个数据分析包,该工具为解决数据分析任务而创建.Pandas纳入大量库和标准数据模型,提供高效的操作数 ...
- Pandas中DateFrame修改列名
Pandas中DateFrame修改列名 在做数据挖掘的时候,想改一个DataFrame的column名称,所以就查了一下,总结如下: 数据如下: >>>import pandas ...
- 数据分析:基于Python的自定义文件格式转换系统
*:first-child { margin-top: 0 !important; } body>*:last-child { margin-bottom: 0 !important; } /* ...
- python – 基于pandas中的列中的值从DataFrame中选择行
如何从基于pandas中某些列的值的DataFrame中选择行?在SQL中我将使用: select * from table where colume_name = some_value. 我试图看看 ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
随机推荐
- Cobbler自动化部署系统
1.cobbler简介 cobbler是一个LInux服务器安装的服务,可以通过网络启动(PXE)的方式来快速安装.重装物理服务器和虚拟机,同时还可以管理DHCP,DNS等 cobbler可以 ...
- C# Winform界面不能适配高DPI的解决方法
1. 将 Form 的 AutoScaleMode 属性设置为 DPI: 2. 在Program.cs中修改代码 class Program { [STAThread] static void Mai ...
- DML_Data Modification_INSERT
Data Modification (INSERT.DELETE.UPDATE.MERGE)之INSERT(基础知识,算是20年来第2次学习MSSQL吧,2005年折腾过一段时间的Oracle)INS ...
- python下载及安装步骤
Python安装 1.浏览器打开网址:www.python.org 2.根据电脑系统选择下载 3.确定电脑系统属性,此处我们以win10的64位操作系统为例 4.安装python 3.6.3 双击下载 ...
- python获取本地时间戳
import time print(time.time())#获当前时间的时间戳 print(time.localtime())#获取本地时间 print(time.strftime('%Y-%m-% ...
- 使用LaTeX输入矩阵
当前各种文本编辑器支持的LaTeX数学公式库大多基于KaTeX,或者在Web中用MathJax的比较多,下面给出一种在Web中输入矩阵的例子 $$\left[ \begin{array}{cccc}a ...
- Laravel:No application encryption key has been specified.
其实吧,这个就是你没有生成密钥 你首先去看看,如果是刚刚下载的lavavel应该会有一个.env.example文件在根目录下,然后修改这个文件名,改成.env 然后用命令行去执行php artisa ...
- 谁再悄咪咪的吃掉异常,我上去就是一 JIO
又到周末了,周更选手申请出站~ 这次分享一下上个月碰到的离奇的问题.一个简单的问题,硬是因为异常被悄咪咪吃掉,过关难度直线提升,导致小黑哥排查一个晚上. 这个美好的晚上,本想着开两把 LOL 无限火力 ...
- JavaWeb网上图书商城完整项目--day02-8.提交注册表单功能之dao、service实现
1.发送邮件 发送邮件的时候的参数我们都写在了配置文件中,配置文件放在src目录下,可以使用类加载器进行加载该数据 //向注册的用户发送邮件 //1读取配置文件 Properties properti ...
- spring 整合redis集群中使用@autowire无效问题的解决办法
1.视频参考黑马32期宜立方商城第6课 redis对于的代码 我们先变向一个redis客户端的接口文件 package com.test; public interface JedisClient { ...