Hbase Region合并
业务场景:
Kafka+SparkStreaming+Hbase
由于数据大量的迁移,再加上业务的改动,新增了很多表,导致rerigon总数接近4万(36个节点)
组件版本:
Kafka:2.1.1
Spark:2.2.0-cdh5.12.0
Hbase:1.2.0-cdh5.12.0
问题发现:
CDH界面较多关于web服务器相应时间过长,和队列刷新速度较慢。
streaming界面,每隔一段时间就会需要较长的处理时间

解决过程:
【1】
首先把一些业务不需要的表disable掉,region下线,最后还剩2.5万个线上region,随后CDH页面无异常信息了,并且streaming处理时间都比较正常了(四类业务表现都相同)
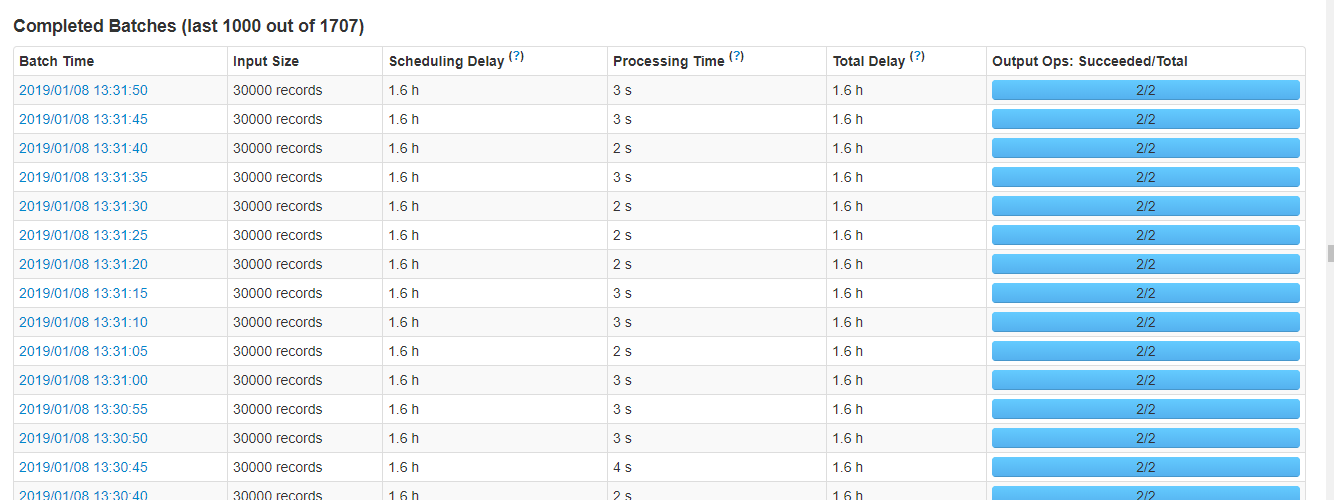
【2】
由于业务上每月都会有新表,所以以上的操作不能满足,经过研究,可以在保证表的请求量不高的情况下,把当前表的region合并,从而减少region数。而且Hbase集群目前已经停掉了region自动分裂,所以不会有在合并完之后再分裂的情况。
禁用分裂机制:

集群配置:

理论上讲,现在regionserver分配了64G内存,0.8的写入高水位线,也就是64*0.8=51.2G用作写,每个memstore占用128M,这么算的话理论上也就每个server400多个region的时候,不会造成过早的flush,总共下来400*36个,现在已经是超负荷运行了,所以还需要将Region进行合并。
合并代码:
public class Hbase_Merge {
public static void main(String[] args) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.property.clientPort", "2181");
conf.set("hbase.zookeeper.quorum", "zk1,zk2,zk3");
HBaseAdmin admin = new HBaseAdmin(conf);
List<HRegionInfo> regions = admin.getTableRegions(TableName.valueOf("TableName"));
Collections.sort(regions, new Comparator<HRegionInfo>() {
@Override
public int compare(HRegionInfo o1, HRegionInfo o2) {
return Bytes.compareTo(o1.getStartKey(),o2.getStartKey());
}
});
HRegionInfo regionInfo =null;
for (HRegionInfo r : regions){
int index =regions.indexOf(r);
if(index %2 == 0){
regionInfo = r;
}else{
System.out.println("start to merge two regions,NUM:"+index+" and "+(index+1) );
admin.mergeRegions(regionInfo.getEncodedNameAsBytes(),r.getEncodedNameAsBytes(),false);
System.out.println("merge two regions finished");
}
}
System.out.println("merge all regions finished");
}
}
结果:
最终Region数大量减少,Streaming任务也恢复正常。
后记:
IO高峰为合并region导致的,入Hbase的程序都将受到影响,Streaming批处理时间增长,中间还伴随着Region-In-Transition(此处影响不大)
建议:避开业务高峰期对Region合并


这些都是之前存到有道上了,搬到这里费了好大的劲,还得不断学习,哈哈
Hbase Region合并的更多相关文章
- HBase Region合并分析
1.概述 HBase中表的基本单位是Region,日常在调用HBase API操作一个表时,交互的数据也会以Region的形式进行呈现.一个表可以有若干个Region,今天笔者就来和大家分享一下Reg ...
- hbase优化之region合并和压缩
HBASE操作:(一般先合并region然后再压缩) 一 .Region合并: merge_region 'regionname1','regionname2' ,'true' --true代表 ...
- 【原创】大叔问题定位分享(13)HBase Region频繁下线
问题现象:hive执行sql报错 select count(*) from test_hive_table; 报错 Error: java.io.IOException: org.apache.had ...
- 【转】HBASE Region in Transition issue on Master UI
[From]https://community.hortonworks.com/content/supportkb/244808/hbase-region-in-transition-issue-on ...
- Hbase Region Server整体架构
Region Server的整体架构 本文主要介绍Region的整体架构,后续再慢慢介绍region的各部分具体实现和源码 RegionServer逻辑架构图 RegionServer职责 1. ...
- HBase Region重点剖析
Region的概念 Region是HBase数据管理的基本单位.数据的move,数据的balance,数据的split,都是按照region来进行操作的. region中存储这用户的真实数据,而为了管 ...
- Hbase region 某个regionserver挂掉后的处理
aaarticlea/png;base64,iVBORw0KGgoAAAANSUhEUgAAAwoAAACdCAMAAAAjbX91AAAABGdBTUEAALGPC/xhBQAAAAFzUkdCAK
- hbase region 分配方式
参与 Region 分配的重要对象 在 Region 分配过程中,起着重要作用有如下一些对象. HMaster— 是 HBase 中的 Master server ,仅有一个. HRegionServ ...
- HBase Region级别二级索引
我们会经常谈及二级索引,这是对全表数据进行另外一种方式的组织存储,是针对table级别的.如果要为HBase上的表实现一个强一致性的二级索引,那么就无法逃避分布式事务,而这一直是用户最期待的功能. 而 ...
随机推荐
- k8s之yaml文件书写格式
k8s之yaml文件书写格式 1 # yaml格式的pod定义文件完整内容: 2 apiVersion: v1 #必选,版本号,例如v1 3 kind: Pod #必选,Pod 4 metadata: ...
- 服务器标配 SSH 协议,你了解多少?
年初,新冠肺炎疫情的出现,全国数千万名员工在家远程办公,使用个人设备通过家庭网络访问公司资料.因此,IT 安全团队面临了众多新挑战:如何实施更加安全的身份验证方案,以确保只有授权人员和设备才能访问公司 ...
- IDEA创建maven项目很慢的问题解决方式
问题现象:刚转IDEA开发,发现创建maven项目,非常慢. 解决方式: 构建maven项目添加参数,要不然非常慢,会卡住-DarchetypeCatalog=internal 自动导入包,codin ...
- js上 初识JavaScript
1.JavaScript简介 **JavaScript ** 是什么?(重点) Js是一种专门为网页交互设计的客户端(浏览器端)的脚本语言: Js与html和css有相似之处,都在浏览器端解析: Js ...
- #2020征文-手机#深鸿会深大小组:HarmonyOS手机游戏—数字华容道
目录: 前言 概述 正文 创建项目 实现初始界面布局 实现数字的随机打乱 实现滑动或点击调换数字 实现游戏成功界面 结语 源码包 前言 12月16号HarmonyOS2.0手机开发者Beta版已经发布 ...
- Python稳基修炼之异常处理
错误与异常 1.区分错误与异常 两种错误(都必须改正): 语法错误(代码不规范,格式不对或缺少符号).逻辑错误(逻辑不通) 异常: 程序运行时发生错误的信号 2.异常处理与注意事项 异常处理: 程序员 ...
- HCIP --- BGP实验
实验拓扑: 要求: R1.R2是EBGP关系,R2.R4是IBGP关系,R4.R5是EBGP邻居关系 R1与R5的环回可以通信 1.配置IP地址 2.BGP承载与IGP之上,所以给AS 2 启用IGP ...
- 【磁盘/文件系统】第三篇:标准磁盘分区流程针对parted(一般硬盘容量大于2T(但是小于2T也可以进行分区);分区数最大是支持100多个分区)
说明: 在 Linux 上可以采用 parted 来对磁盘进行分区 1.通过 fdisk -l 可以查看磁盘是否存在, 由于使用的是大磁盘(大于2T),fdisk 不能用来作为分区工具了,而应该使用 ...
- 浅谈 WebRTC 的 Audio 在进入 Encoder 之前的处理流程
在 WebRTC 中,Audio 数据在被送入编码器之前,有 2 大部分需要特别关注,一是数据采集,二是 Audio Processing. 作者:方来,技术专家,从事 voip 应用开发. 数据采集 ...
- 解决CentOS 8 Docker容器无法上网的问题
发布于:2020-11-28 Docker 2条评论 3,051 views 如需VPS代购.PHP开发.服务器运维等服务,请联系博主QQ:337003006 CentOS 8已经发行好长一段 ...