集成学习算法——adaboost
adaboost是boosting类集成学习方法中的一种算法,全称是adaptive boost,表示其是一种具有自适应性的算法,这个自适应性体现在何处,下面来详细说明。
1.adaboost算法原理
在boosting算法框架中,新的弱学习器是基于已有的弱学习器的输出结果生成的,已有的弱学习器产生的损失(用损失函数来评估)是固定的,而新的弱学习器的作用就是使得当前模型(包含它自身)损失尽可能减小,达到局部最优。
adboost算法关注的是样本的输出(这里有点废话了,每个模型关注的都是样本的输出结果),它通过赋予、调整每个样本的权重值,来调整样本在构建新弱学习器起到的作用,样本权重越大,则起到的作用越大。以二分类问题为例,若某个样本类别在当前预测错误,那么新的弱学习器将尽量保证它们的类别预测正确,下图
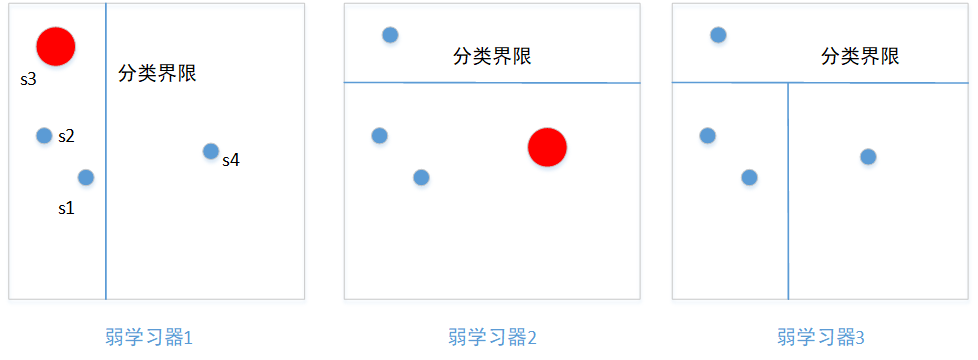
在弱学习器1中,样本s3被错误分类,那么在构造弱学习器2时,样本s3会被赋予较大的权重,样本s1、s2、s4被赋予较小的权重,也即是说弱学习器2将着力于将样本s3类别预测正确。 在弱学习器2中,样本s4的类别又被预测错误,同样的,样本s4权重提升。
样本的最终输出结果是每个弱学习器输出结果的线性加权组合。在adboost算法中,除了对样本赋予权重并自适应调整,还会给每个弱学习器赋予权重,这样adboost的最终输出可以表达为如下形式

其中 表示弱学习器上样本的权重,
表示弱学习器的输出,
表示各弱学习器的权重,
。这里自然会有疑问,adboost算法中是如何赋予、调整样本的权重的?每个弱学习器的权重是如何给出的?下面我们来逐渐揭开adboost算法的神秘面纱。
2.目标函数
损失函数定义了模型的损失,而损失最小化则是模型构建过程的目标。一般的损失函数包含代价损失与正则化(惩罚模型复杂度)两项,但是adboost算法中损失函数只包含代价损失项,即只考虑模型误差。adaboost算法的损失函数比表示如下:
(1)
其中 为样本个数,
为弱学习器的个数,
为样本特征,
为样本标签,
为弱学习器
的权重,建模的过程就是要最小化损失函数
(2)
使用adaboost算法构建分类二分类(-1,1)模型时,使用的是指数损失函数,形式如下
(3)
注意,这里的类别设为-1,1仅仅是为了简化计算,类别用什么表示并不影响结果。将公式(3)代入公式(2)中,得到目标损失为
(4)
在公式(4)中,表示前m-1个弱学习器组合得输出结果。在构建第m个弱学习器时,
是已经确定的,那可以设
,而
的值是不依赖于
与
的,这样公式(4)数可以进一步改写为
(5)
由于二分类的标签使用了(-1,1),因此根据样本预测类别与真实类别是否相同,公式(5)还可以简化为如下形式
(6)
由于目标函数中两项都含有、
,不利于优化计算,因此公式(6)还可以进一步转化为
(7)
其中取值为:当
成立时,值为1;当
不成立时,值为0。
到这里为止,二分类模型的目标函数已经给出。我们再来关注一下,当前m-1个弱学习器的预测结果与真实类别一致时,
会比较小,反之则会比较大,这与第1节中讲到的样本权重更新方式相似,事实上
就是样本
在构建第
个弱学习器时的权重。
3.弱学习器的构建
从公式(7)可以看到,对任意的,求解令目标函数最小的
就等价于求解令
最小的,也就是要最小化带权重的误差,即
(8)
这个怎么理解?首先,我们用一批样本训练出一个弱学习器出来,那么这个弱学习器对这批样本的预测误差自然是最小的,毕竟是在训练集上的预测,总不会说随便搞个弱学习器出来预测误差会更小;其次,我们会在某一个特征上分裂样本,选择哪个特征以及哪个分裂点能得到最小的分类误差(带权重的误差)?选定误差最小的结果作为。我们通常会预先选定基模型,例如CART(一般深度为2,一次只使用一个特征),在带权重样本上训练基模型就得到
。
4.弱学习器的权重
的计算
首先,定义一下弱学习器的误差率
回到公式(6)所示的目标函数中,由于已经得到,此时目标函数中只有
这一个参数,我们可以求解目标函数对
的导数,并令其为0,得到局部最优解
(9)
等式两边同乘,得
(10)
求得
(11)
由公式(11)可以看到,越大,
越小,表明误差越大得弱学习器其权重越小,反之越大。
5.样本权重的更新
构建弱学习器的样本的权重更新方式如下
其中,,之所以除以
,是为了确保所有的
构成一个分布。
至此,我们已经解决了第1节中提出的疑问,如何更新样本权重、如何计算弱学习器的权重。
6.使用adaboost算法建模的流程
了解以上内容后,在分类任务中,使用adboost算法建模的流程大致如下:
- 初始化样本权值
- for m in M:
(a)使用带权重的样本训练出弱学习器
(b)计算在带权重样本上的误差率
(c)计算弱学习器的权重
(d)更新样本权重,得到
- 输出最终模型,得到
,sign函数表示着在二分类时,每个弱学习器的输出集为
,最后弱学习器间加权计算后若结果大于0,则最终预测为1,否则为-1。
7.多分类问题
adaboost算法刚提出时,只用于处理二分类问题,不过后来又有了出现了许多基于adboost算法而改进的算法,可以处理多分类问题,例如adaboost.m1算法、adaboost.m2算法等,处理多分类问题时就需要改变样本权重更新的方式了,这个后面再单独写文章介绍。
8.弱学习器的学习率问题
在第2节中提到,adaboost算法并未考虑正则化,但在实际使用adaboost算法建模时,一般则需要考虑,采取的方式是每个弱学习器乘以一个学习率 ,防止弱学习器对数据集中的信息学习的过快,与之相应的,加了学习率
的限制后,就需要考虑弱学习器的个数了,这需要进行调参以达到比较平衡的组合。
9.Real adaboost算法
前面讲到的adaboost算法每个弱学习器的输出只能为,也被称为Discrete adaboost算法,它无法输出类别概率,这限制了它的应用,Real adaboost算法是Discrete adaboost算法的一种改进,其使得弱学习器的输出为
。和Real adaboost算法一样,仍然采用指数损失函数,每次构建一个弱学习器都是为了最小化指数损失
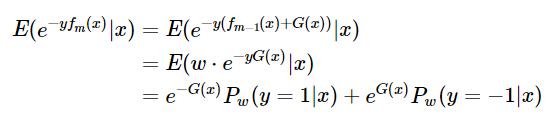
对求导,得到
其中,表示在权重为
时样本被预测为 “+1” 类的概率。可以观察到,
实际上是一个数值序列,每一个样本都对应一个概率值,而在实际建模时,我们一般都是将样本在某一特征上的取值划分为若干个不相交的区间,这样得到的
就是一个分段函数了。利用Real adaboost算法建模的流程如下:
- 初始化样本权重
,其中
为样本个数
- Do For
(1)基于带的训练集
训练弱学习器:
a. 在某一特征上对 进行划分,
,当
时,
b. 统计中 +1 类、-1 类的样本权重和
,
c.定义,对
,其中
为平滑因子,一般选择为0.01即可。(这里插一句,不考虑1/2系数的话,
实际上就是在
上计算的 WOE值(信息权重值,在信用评分卡模型中常用到),为了防止某个
上存在
为0的情况,所以要加上一个平滑因子)
d.调整步骤a中特征选择、特征上样本划分方式,使最小化,将满足条件的
作为本轮训练最终输出的弱学习器
(2)调整样本权重
3.得到强分类器,其中b为阈值,用于决定+1、-1分类
集成学习算法——adaboost的更多相关文章
- 集成学习值Adaboost算法原理和代码小结(转载)
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类: 第一个是个体学习器之间存在强依赖关系: 另一类是个体学习器之间不存在强依赖关系. 前者的代表算法就是提升(bo ...
- 谈谈模型融合之一 —— 集成学习与 AdaBoost
前言 前面的文章中介绍了决策树以及其它一些算法,但是,会发现,有时候使用使用这些算法并不能达到特别好的效果.于是乎就有了集成学习(Ensemble Learning),通过构建多个学习器一起结合来完成 ...
- 集成学习之Adaboost算法原理小结
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系.前者的代表算法就是是boostin ...
- 集成学习之Adaboost算法原理
在boosting系列算法中,Adaboost是最著名的算法之一.Adaboost既可以用作分类,也可以用作回归. 1. boosting算法基本原理 集成学习原理中,boosting系列算法的思想:
- 集成学习算法汇总----Boosting和Bagging(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 集成学习之AdaBoost
AdaBoost 当做出重要决定时,大家可能会考虑吸取多个专家而不只是一个人的意见,机器学习也是如此,这就是集成学习的基本思想.使用集成方法时有多种形式:可以是不同算法的集成,也可以是同一算法在不同设 ...
- 集成学习算法总结----Boosting和Bagging
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- 集成学习算法总结----Boosting和Bagging(转)
1.集成学习概述 1.1 集成学习概述 集成学习在机器学习算法中具有较高的准去率,不足之处就是模型的训练过程可能比较复杂,效率不是很高.目前接触较多的集成学习主要有2种:基于Boosting的和基于B ...
- Ensemble_learning 集成学习算法 stacking 算法
原文:https://herbertmj.wikispaces.com/stacking%E7%AE%97%E6%B3%95 stacked 产生方法是一种截然不同的组合多个模型的方法,它讲的是组合学 ...
随机推荐
- 手把手教你用 Spring Boot搭建一个在线文件预览系统!支持ppt、doc等多种类型文件预览
昨晚搭建环境都花了好一会时间,主要在浪费在了安装 openoffice 这个依赖环境上(Mac 需要手动安装). 然后,又一步一步功能演示,记录,调试项目,并且简单研究了一下核心代码之后才把这篇文章写 ...
- MeteoInfoLab脚本示例:TRMM 2A12 HDF数据
TRMM 2A12 HDF数据是卫星观测的SWATH数据(轨道数据),比格点数据处理起来要麻烦一些.数据的经纬度保存在geolocation变量中,需要先将经纬度数据读出来(均为2维数组),然后读取云 ...
- SpringBoot整合Elasticsearch游标查询(scroll)
游标查询(scroll)简介 scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价. 游标查询会取某个时间点的快照数据. 查询初始化之后 ...
- spring boot:用dynamic-datasource-spring-boot-starter配置多数据源访问seata(seata 1.3.0 / spring boot 2.3.3)
一,dynamic-datasource-spring-boot-starter的优势? 1,dynamic-datasource-spring-boot-starter 是一个基于springboo ...
- request-html 使用
from requests_html import HTMLSessionsession = HTMLSession()resp = session.get('http://www.spbeen.co ...
- CentOS 6编译安装Redis
[root@localhost ~]# vim /etc/sysconfig/iptables # 添加如下:-A INPUT -m state –state NEW -m tcp -p tcp –d ...
- js读取xml,javascript读取XML
IE下示例代码: var xmlDoc = "<root><AlleyWay><Code>1103</Code><Name>胡同2 ...
- CPU:Central Processing Unit
CPU执行计算任务时都需要遵从一定的规范,程序在被执行前都需要先翻译为CPU可以理解的语言.这种规范或语言就是指令集(ISA,Instruction Set Architecture). CPU 架构 ...
- 通过命令行上传ipa到appstore
搞持续集成自动化打包上传到appstore遇到这个问题,记录一下. 其实主要就一条到命令: xcrun altool --upload-app -f xxxx.ipa -u "yanqizh ...
- Linux入门到放弃之八《任务计划管理》
任务计划管理 1.每周一下午5:50将/data目录下的所有目录和文件归档并压缩为:backup.tar.gz 放在/home/backup目录下. 先新建/data目录,并在目录中随意生成几个文件 ...