myBatis源码解析-缓存篇(2)
上一章分析了mybatis的源码的日志模块,像我们经常说的mybatis一级缓存,二级缓存,缓存究竟在底层是怎样实现的。此次开始分析缓存模块
1. 源码位置,mybatis源码包位于org.apache.ibatis.cache下,如图
2. 先从org.apache.ibatis.cache下的cache接口开始
// 缓存接口
public interface Cache {
// 获取缓存ID
String getId();
// 放入缓存
void putObject(Object key, Object value);
// 获取缓存
Object getObject(Object key);
// 移除某一缓存
Object removeObject(Object key);
// 清除缓存
void clear();
// 获取缓存大小
int getSize();
// 获取锁
ReadWriteLock getReadWriteLock();
}
mybatis提供了自定义的缓存接口,功能通俗易懂,没什么好解释的。有接口,必然有实现,看一下缓存接口的基本实现类PerpetualCache,所在路径为org.apache.ibatis.cache.impl下。
public class PerpetualCache implements Cache {
// 缓存的ID
private String id;
// 使用HashMap充当缓存(老套路,缓存底层实现基本都是map)
private Map<Object, Object> cache = new HashMap<Object, Object>();
// 唯一构造方法(即缓存必须有ID)
public PerpetualCache(String id) {
this.id = id;
}
// 获取缓存的唯一ID
public String getId() {
return id;
}
// 获取缓存的大小,实际就是hashmap的大小
public int getSize() {
return cache.size();
}
// 放入缓存,实际就是放入hashmap
public void putObject(Object key, Object value) {
cache.put(key, value);
}
// 从缓存获取,实际就是从hashmap中获取
public Object getObject(Object key) {
return cache.get(key);
}
// 从缓存移除
public Object removeObject(Object key) {
return cache.remove(key);
}
// hashmap清除数据方法
public void clear() {
cache.clear();
}
// 暂时没有其实现
public ReadWriteLock getReadWriteLock() {
return null;
}
// 缓存是否相同
public boolean equals(Object o) {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
if (this == o) return true; // 缓存本身,肯定相同
if (!(o instanceof Cache)) return false; // 没有实现cache类,直接返回false
Cache otherCache = (Cache) o; // 强制转换为cache
return getId().equals(otherCache.getId()); // 直接比较ID是否相等
}
// 获取hashCode
public int hashCode() {
if (getId() == null) throw new CacheException("Cache instances require an ID.");
return getId().hashCode();
}
}
如上分析,mybatis的基本缓存实现类其实就是内部维护了一个HashMap,通过对HashMap操作来实现基本的功能。但需要注意的是,判断两个缓存是否相等,是比较的缓存ID是否相等。看Cache otherCache = (Cache) o;也就是说缓存接口可能有多种实现,也确实如此。PerpetualCache只提供了缓存的基本实现功能,但一看HashMap就是不安全的类,多线程下肯定会出问题。又比如说我想这个缓存有固定大小,缓存过期策越为先进先出或者LRU功能等。myabtis肯定想到这点,查看org.apache.ibatis.cache.decorators包。看名字就知道用到了装饰者模式。查看包下的类,如SynchronizedCache为缓存保障了线程安全,LruCache定义了缓存的过期策略为淘汰最近最少访问的数据,LoggIngCache提供了日志打印功能。用户想让自己的缓存具备什么功能,就使用这些装饰者类进行装饰。
3. 分析缓存装饰类SynchronizedCache
// 在操作前加锁,保证线程安全
@Override
public synchronized int getSize() {
return delegate.getSize();
} @Override
public synchronized void putObject(Object key, Object object) {
delegate.putObject(key, object);
} @Override
public synchronized Object getObject(Object key) {
return delegate.getObject(key);
} @Override
public synchronized Object removeObject(Object key) {
return delegate.removeObject(key);
} @Override
public synchronized void clear() {
delegate.clear();
}
很简单。就是在方法前使用synchronized加锁,保证线程安全。
4. 分析缓存装饰类LruCache
介绍LruCache前,先介绍下Lru的实现,Lru是很常用的淘汰策略,意为最近最少使用的对象。查看LruCache,发现内部使用了LinkedHashMap,熟悉LinkedHashMap的伙伴应该知道了。我们一般手写LRU功能就是通过复写LinkedHashMap的方法来实现,LruCache也一样。先大致了解下LinkedHashMap。
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
LinkedHashMap继承HashMap类,实际上就是对HashMap的一个封装。
// 内部维护了一个自定义的Entry,集成HashMap中的node类
static class Entry<K,V> extends HashMap.Node<K,V> {
// linkedHashmap用来连接节点的字段,根据这两个字段可查找按顺序插入的节点
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
查看LinkedHashMap构造方法,具体访问顺序见下文分析
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
// 调用HashMap的构造方法
super(initialCapacity, loadFactor);
// 访问顺序维护,默认false不开启
this.accessOrder = accessOrder;
}
引入两张图来理解下HashMap和LinkedHashMap

以上时HashMap的结构,采用拉链法解决冲突。LinkedHashMap在HashMap基础上增加了一个双向链表来表示节点插入顺序。
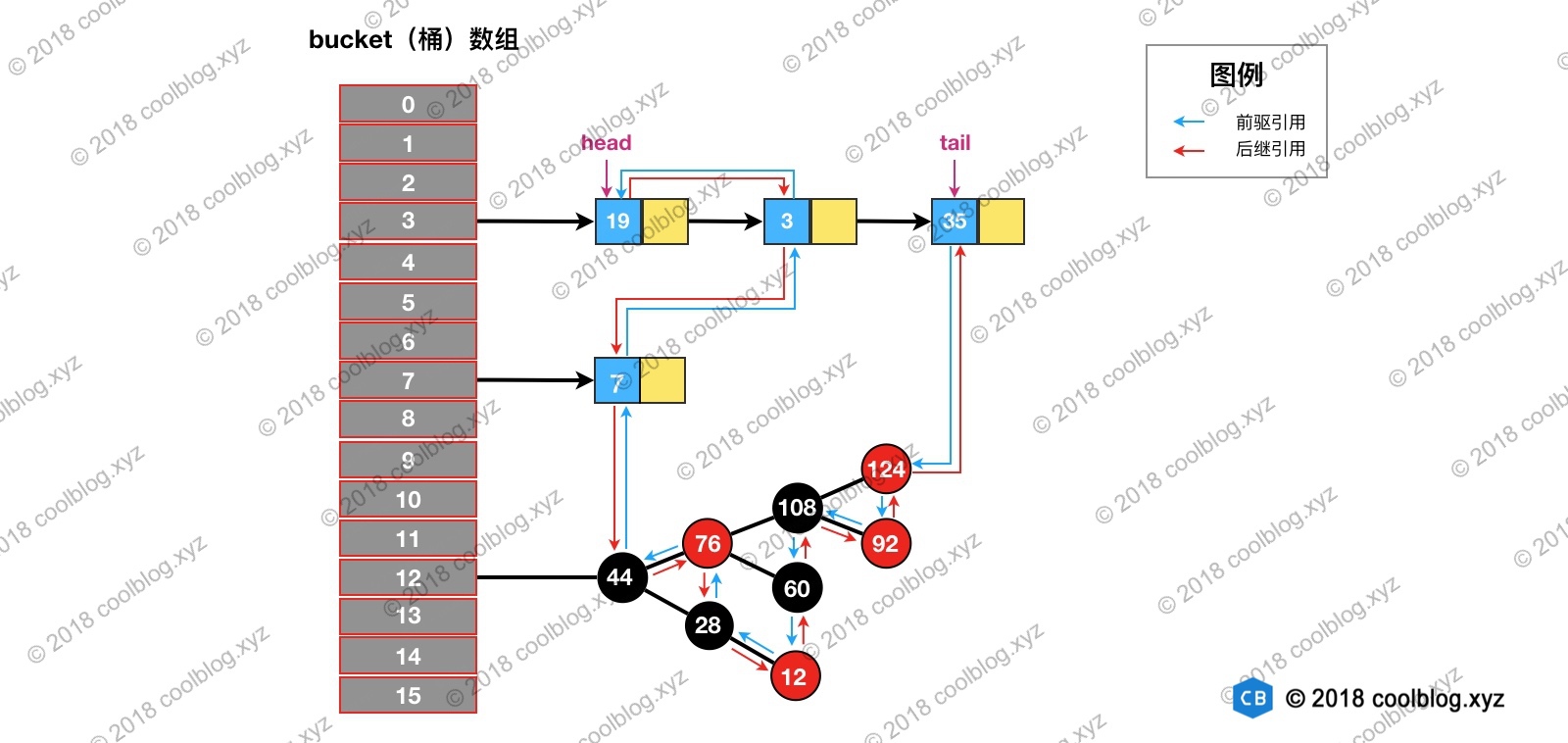
如上,节点上多出的红色和蓝色箭头代表了Entry中的before和after。在put元素时,会自动在尾节点后加上该元素,维持双向链表。了解LinkedHashMap结构后,在看看究竟什么是维护节点的访问顺序。先说结论,当开启accessOrder后,在对元素进行get操作时,会将该元素放在双向链表的队尾节点。源码如下:
public V get(Object key) {
Node<K,V> e;
// 调用HashMap的getNode方法,获取元素
if ((e = getNode(hash(key), key)) == null)
return null;
// 默认为false,如果开启维护链表访问顺序,执行如下方法
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
// 方法实现(将e放入尾节点处)
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
// 当节点不是双向链表的尾节点时
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after; // 将待调整的e节点赋值给p
p.after = null;
if (b == null) // 说明e为头节点,将老e的下一节点值为头节点
head = a;
else
b.after = a;// 否则,e的上一节点直接指向e的下一节点
if (a != null)
a.before = b; // e的下一节点的上节点为e的上一节点
else
last = b;
if (last == null)
head = p;
else {
p.before = last; // last和p互相连接
last.after = p;
}
tail = p; // 将双向链表的尾节点指向p
++modCount; // 修改次数加以
}
}
代码很简单,如上面的图,我访问了节点值为3的节点,那木经过get操作后,结构变成如下

经过如上分析我们知道,如果限制双向链表的长度,每次删除头节点的值,就变为一个lru的淘汰策略了。举个例子,我想限制双向链表的长度为3,依次put 1 2 3,链表为 1 -> 2 -> 3,访问元素2,链表变为 1 -> 3-> 2,然后put 4 ,发现链表长度超过3了,淘汰1,链表变为3 -> 2 ->4;
那木linkedHashMap是怎样知道自定义的限制策略,看代码,因为LinkedHashMap中没有提供自己的put方法,是直接调用的HashMap的put方法,查看hashMap代码如下:
// hashMap
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
// 看这个方法
afterNodeInsertion(evict);
return null;
} // linkedHashMap重写了此方法 void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
// removeEldestEntry默认返回fasle
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
// 移除双向链表中的头指针元素
removeNode(hash(key), key, null, false, true);
}
}
大功告成。原来只需要重新实现removeEldestEntry就可以自定义实现lru功能了。
下文分析LruCache就好多了。
myBatis源码解析-缓存篇(2)的更多相关文章
- jQuery2.x源码解析(缓存篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 缓存是jQuery中的又一核心设计,jQuery ...
- myBatis源码解析-数据源篇(3)
前言:我们使用mybatis时,关于数据源的配置多使用如c3p0,druid等第三方的数据源.其实mybatis内置了数据源的实现,提供了连接数据库,池的功能.在分析了缓存和日志包的源码后,接下来分析 ...
- myBatis源码解析-反射篇(4)
前沿 前文分析了mybatis的日志包,缓存包,数据源包.源码实在有点难顶,在分析反射包时,花费了较多时间.废话不多说,开始源码之路. 反射包feflection在mybatis路径如下: 源码解析 ...
- myBatis源码解析-类型转换篇(5)
前言 开始分析Type包前,说明下使用场景.数据构建语句使用PreparedStatement,需要输入的是jdbc类型,但我们一般写的是java类型.同理,数据库结果集返回的是jdbc类型,而我们需 ...
- myBatis源码解析-日志篇(1)
上半年在进行知识储备,下半年争取写一点好的博客来记录自己源码之路.在学习源码的路上也掌握了一些设计模式,可所谓一举两得.本次打算写Mybatis的源码解读. 准备工作 1. 下载mybatis源码 下 ...
- jQuery2.x源码解析(构建篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 笔者阅读了园友艾伦 Aaron的系列博客< ...
- jQuery2.x源码解析(设计篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 这一篇笔者主要以设计的角度探索jQuery的源代 ...
- jQuery2.x源码解析(回调篇)
jQuery2.x源码解析(构建篇) jQuery2.x源码解析(设计篇) jQuery2.x源码解析(回调篇) jQuery2.x源码解析(缓存篇) 通过艾伦的博客,我们能看出,jQuery的pro ...
- 【MyBatis源码解析】MyBatis一二级缓存
MyBatis缓存 我们知道,频繁的数据库操作是非常耗费性能的(主要是因为对于DB而言,数据是持久化在磁盘中的,因此查询操作需要通过IO,IO操作速度相比内存操作速度慢了好几个量级),尤其是对于一些相 ...
随机推荐
- 数据库周刊30丨数据安全法草案将亮相;2020数据库产业报告;云南电网上线达梦;达梦7误删Redo Log;Oracle存储过程性能瓶颈;易鲸捷实践案例……
摘要:墨天轮数据库周刊第30期发布啦,每周1次推送本周数据库相关热门资讯.精选文章.干货文档. 热门资讯 1.数据安全法草案即将亮相:将确立数据分级分类管理.应急处置制度[摘要]数据安全法草案即将在本 ...
- 2020年的六种编程语言排名中,java排第几只有不到1%的人知道
前言 编程语言是开发的基础.有不同的类型和特征,并且开发人员针对不同的场景选择正确的语言,但是您知道使用哪种语言吗?中国和世界各地有多少开发人员正在使用它?他们的排名是多少?快来看看您知道多少个列表! ...
- CSS3 transform详解,关于如何使用transform
transform是css3的新特性之一.有了它可以box module变的更真实,这篇文章将全面介绍关于transform的使用. transform的作用 transform可以让元素应用 2D ...
- 3dTiles 数据规范详解[3] 内嵌在瓦片文件中的两大数据表
转载请声明出处:全网@秋意正寒 零.本篇前言 说实话,我很纠结是先介绍瓦片的二进制数据文件结构,还是先介绍这两个重要的表.思前想后,我决定还是先介绍这两个数据表. 因为这两个表不先给读者灌输,那么介绍 ...
- grunt之easy demo
首先安装grunt-cli cnpm install -g grunt-cli 接下来创建package.json,内容如下 { "name": "demo ...
- OldTrafford after 102 days
THE RED GO MARCHING ON One Team One Love Through the highs and the lows One hundred and two long ...
- Let's GO(一)
近来开始学Go,留此博客以记录学习过程,顺便鞭策自己更加努力. 人生苦短,Let's GO! Let's GO(一) Let's GO(二) Let's GO(三) Let's GO(四) 简单介绍 ...
- 错题重错之枪战Maf
题目描述 有 n 个人,用1∼n 进行编号,每个人手里有一把手枪.一开始所有人都选定一个人瞄准(有可能瞄准自己).然后他们按某个顺序开枪,且任意时刻只有一个人开枪.因此,对于不同的开枪顺序,最后死的人 ...
- 数据可视化之DAX篇(十一)Power BI度量值不能作为坐标轴?这个解决思路送给你
https://zhuanlan.zhihu.com/p/79522456 对于PowerBI使用者而言,经常碰到的一个问题是,想把度量值放到坐标轴上,却发现无法实现.尤其是初学者,更是习惯性的想这么 ...
- cmake安装使用
1.安装命令: yum install -y gcc gcc-c++ make automake wget http://www.cmake.org/files/v2.8/cmake-2.8.10.2 ...