BERT模型详解
1 简介
- BERT全称Bidirectional Enoceder Representations from Transformers,即双向的Transformers的Encoder。是谷歌于2018年10月提出的一个语言表示模型(language representation model)。
1.1 创新点
- 预训练方法(pre-trained):
- 用Masked LM学习词语在上下文中的表示;
- 用Next Sentence Prediction来学习句子级表示。
1.2 成功
- 强大,效果好。出来之时,在11种自然语言处理任务上霸榜。
2 模型
2.1 基本思想
Bert之前的几年,人们通过DNN对语言模型进行“预训练”,得到词向量,然后在一些下游NLP任务(问题回答,自然语言推断,情感分析等)上进行了微调,取得了很好的效果。
对于下游任务,通常并不是直接使用预训练的语言模型,而是使用语言模型的副产物--词向量。实际上,预训练语言模型通常是希望得到“每个单词的最佳上下文表示”。如果每个单词只能看到自己“左侧的上下文”,显然会缺少许多语境信息。因此需要训练从右到左的模型。这样,每个单词都有两个表示形式:从左到右和从右到左,然后就可以将它们串联在一起以完成下游任务了。
综上,从直觉上讲,如果可以训练一个高度双向的语言模型,那将非常棒。
2.2 建模目标
可以和同是双向的ELMo对比一下:
- ELMo:
- \(P(w_i|w_1, w_2, ..., w_{i-1})\) 和 \(P(w_i|w_{i+1}, w_{i+2},...,w_n)\)作为目标函数,独立训练处两个representation然后拼接。
- BERT的目标函数:
- \(P(w_i|w_1, ..., w_{i-1}, w_{i+1},...,w_n)\)以此训练LM。
2.3 词嵌入(Embedding)
-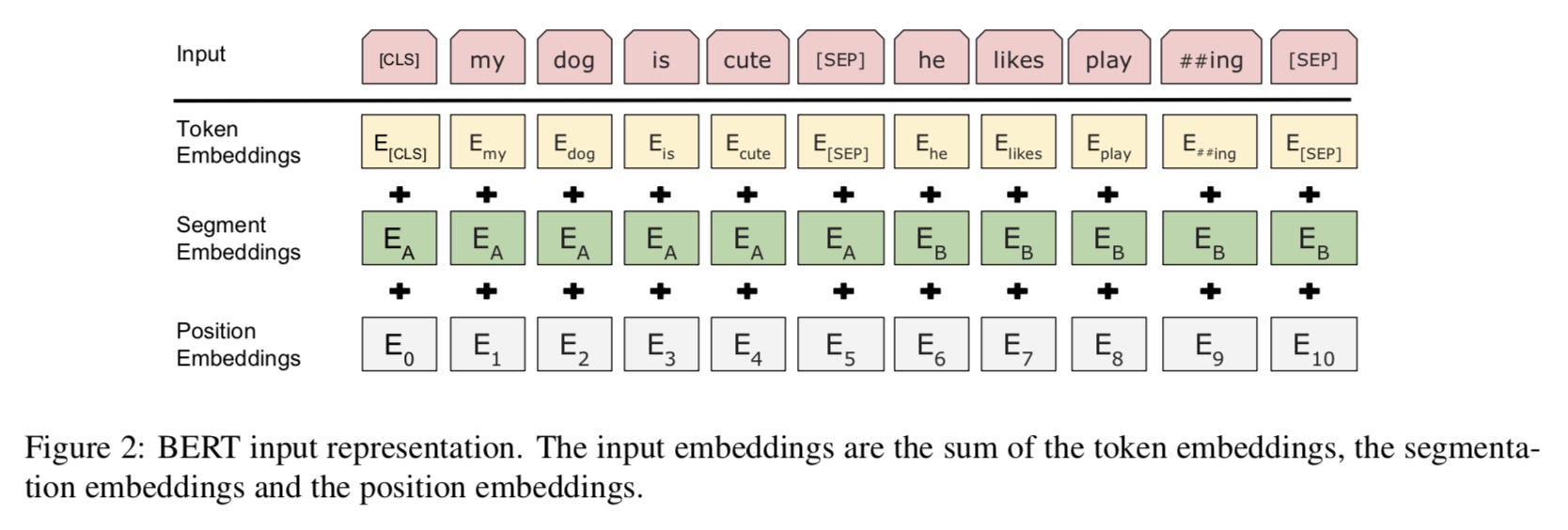
- Bert的Embedding由三种Embedding求和而成。
- Token Embeddings 是指的词(字)向量。第一个单词是CLS标志,可以用于之后的分类任务。????
- Segment Embeddings用来区别两种句子,预训练除了LM,还需要做判断两个句子先后顺序的分类任务。
- Position Embeddings和Transformer的Position Embeddings不一样,在Transformer中使用的是公式法在bert这里是通过训练得到的。
2.4 预训练任务(Pre-training Task)
2.4.1 Task 1: Masked LM
在将单词序列输入给 BERT 之前,每个序列中有 15% 的单词被 [MASK] token 替换。然后模型尝试基于序列中其他未被 mask 的单词的上下文来预测被mask的原单词。最终的损失函数只计算被mask掉那个token。
如果一直用标记[MASK]代替(在实际预测时是碰不到这个标记的)会影响模型,具体的MASK是有trick的:
随机mask的时候10%的单词会被替代成其他单词,10%的单词不替换,剩下80%才被替换为[MASK]。作者没有说明什么原因,应该是基于实验效果?
要注意的是Masked LM预训练阶段模型是不知道真正被mask的是哪个词,所以模型每个词都要关注。
训练技巧:序列长度太大(512)会影响训练速度,所以90%的steps都用seq_len=128训练,余下的10%步数训练512长度的输入。
具体实现注意:
- i) 在encoder的输出上添加一个分类层。
- ii) 用嵌入矩阵乘以输出向量,将其转换为词汇的维度。
- iii) 用softmax计算词汇表中每个单词的概率。
BERT的损失函数只考虑了mask的预测值,忽略了没有掩蔽的字的预测。这样的话,模型要比单向模型收敛得慢,不过结果的情境意识增加了。
2.4.2 Task 2: Next Sentence Prediction
- LM存在的问题是,缺少句子之间的关系,这对许多NLP任务很重要。为预训练句子关系模型,bert使用一个非常简单的二分类任务:将两个句子A和B链接起来,预测原始文本中句子B是否排在句子A之后。
- 具体训练的时候,50%的输入对在原始文档中是前后关系,另外50%中是从语料库中随机组成的,并且是与第一句断开的。
- 为了帮助模型区分开训练中的两个句子,输入在进入模型之前要按以下方式进行处理:
- 在第一个句子的开头插入 [CLS] 标记,在每个句子的末尾插入 [SEP] 标记。
- 将表示句子 A 或句子 B 的一个句子 embedding 添加到每个 token 上,即前文说的Segment Embeddings。
- 给每个token添加一个位置embedding,来表示它在序列中的位置。
- 为了预测第二个句子是否是第一个句子的后续句子,用下面几个步骤来预测:
- 整个输入序列输入给 Transformer 模型用一个简单的分类层将[CLS]标记的输出变换为 2×1 形状的向量。
- 用 softmax 计算 IsNextSequence 的概率
- 在训练BERT模型时,Masked LM和 Next Sentence Prediction 是一起训练的,目标就是要最小化两种策略的组合损失函数。
2.5 微调(Fine-tunning)
- 对于不同的下游任务,我们仅需要对BERT不同位置的输出进行处理即可,或者直接将BERT不同位置的输出直接输入到下游模型当中。具体的如下:
- 对于情感分析等单句分类任务,可以直接输入单个句子(不需要[SEP]分隔双句),将[CLS]的输出直接输入到分类器进行分类
- 对于句子对任务(句子关系判断任务),需要用[SEP]分隔两个句子输入到模型中,然后同样仅须将[CLS]的输出送到分类器进行分类
- 对于问答任务,将问题与答案拼接输入到BERT模型中,然后将答案位置的输出向量进行二分类并在句子方向上进行softmax(只需预测开始和结束位置即可)
- 对于命名实体识别任务,对每个位置的输出进行分类即可,如果将每个位置的输出作为特征输入到CRF将取得更好的效果。
- 对于常规分类任务中,需要在 Transformer 的输出之上加一个分类层
3 优缺点
3.1 优点
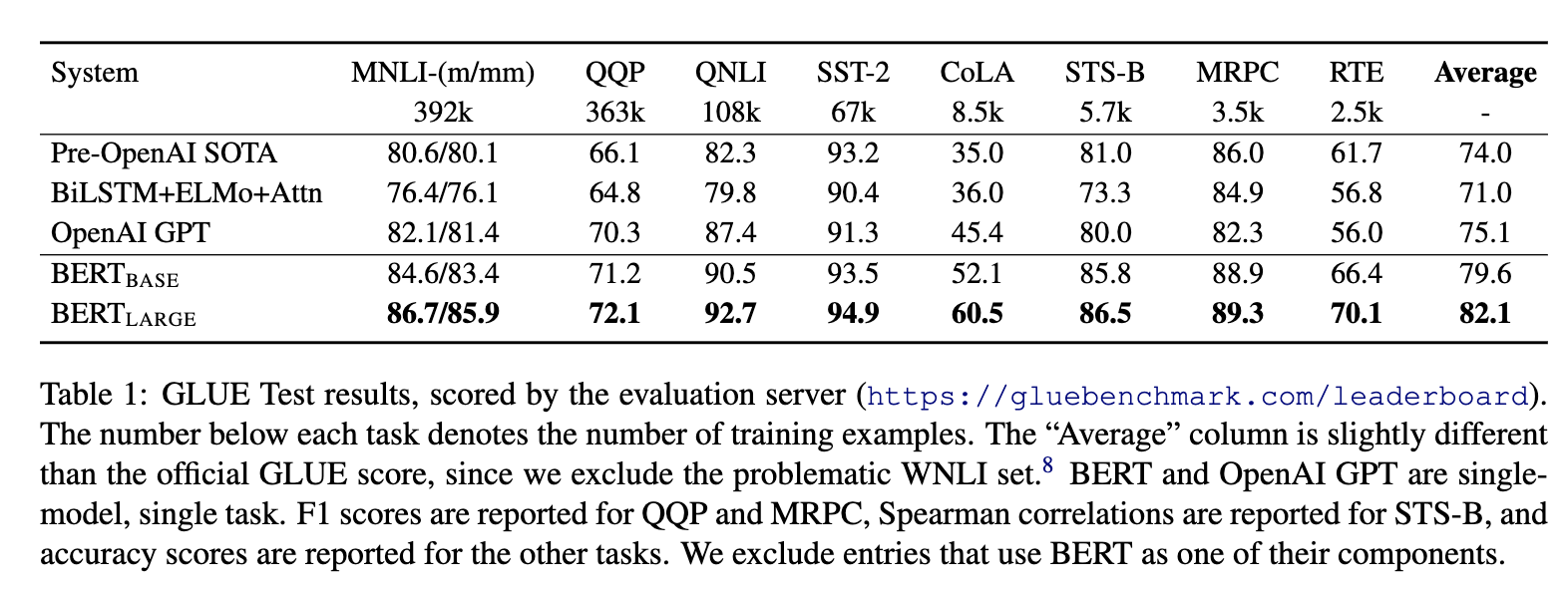
- 效果好,横扫了11项NLP任务。bert之后基本全面拥抱transformer。微调下游任务的时候,即使数据集非常小(比如小于5000个标注样本),模型性能也有不错的提升。
3.2 缺点
作者在文中主要提到的就是MLM预训练时的mask问题:
- [MASK]标记在实际预测中不会出现,训练时用过多[MASK]影响模型表现
- 每个batch只有15%的token被预测,所以BERT收敛得比left-to-right模型要慢(它们会预测每个token)
- BERT的预训练任务MLM使得能够借助上下文对序列进行编码,但同时也使得其预训练过程与中的数据与微调的数据不匹配,难以适应生成式任务
- BERT没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计
- 由于最大输入长度的限制,适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分类)
4 参考文献
- BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, 11 Oct 2018 (v1), last revised 24 May 2019 (v2)
- https://www.reddit.com/r/MachineLearning/comments/9nfqxz/r_bert_pretraining_of_deep_bidirectional/
- https://zhuanlan.zhihu.com/p/46652512
BERT模型详解的更多相关文章
- ASP.NET Core的配置(2):配置模型详解
在上面一章我们以实例演示的方式介绍了几种读取配置的几种方式,其中涉及到三个重要的对象,它们分别是承载结构化配置信息的Configuration,提供原始配置源数据的ConfigurationProvi ...
- ISO七层模型详解
ISO七层模型详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在我刚刚接触运维这个行业的时候,去面试时总是会做一些面试题,笔试题就是看一个运维工程师的专业技能的掌握情况,这个很 ...
- 28、vSocket模型详解及select应用详解
在上片文章已经讲过了TCP协议的基本结构和构成并举例,也粗略的讲过了SOCKET,但是讲解的并不完善,这里详细讲解下关于SOCKET的编程的I/O复用函数. 1.I/O复用:selec函数 在介绍so ...
- 第94天:CSS3 盒模型详解
CSS3盒模型详解 盒模型设定为border-box时 width = border + padding + content 盒模型设定为content-box时 width = content所谓定 ...
- JVM的类加载过程以及双亲委派模型详解
JVM的类加载过程以及双亲委派模型详解 这篇文章主要介绍了JVM的类加载过程以及双亲委派模型详解,类加载器就是根据指定全限定名称将 class 文件加载到 JVM 内存,然后再转化为 class 对象 ...
- 云时代架构阅读笔记六——Java内存模型详解(二)
承接上文:云时代架构阅读笔记五——Java内存模型详解(一) 原子性.可见性.有序性 Java内存模型围绕着并发过程中如何处理原子性.可见性和有序性这三个特征来建立的,来逐个看一下: 1.原子性(At ...
- css 06-CSS盒模型详解
06-CSS盒模型详解 #盒子模型 #前言 盒子模型,英文即box model.无论是div.span.还是a都是盒子. 但是,图片.表单元素一律看作是文本,它们并不是盒子.这个很好理解,比如说,一张 ...
- 图解机器学习 | LightGBM模型详解
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/34 本文地址:http://www.showmeai.tech/article-det ...
- flink内存模型详解与案例
任务提交时的一些yarn设置(通用客户端模式) 指定并行度 -p 5 \ 指定yarn队列 -Dyarn.appl ...
随机推荐
- html+css入门基础案例之圣诞那些事
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 技术解析丨C++元编程之Parser Combinator
摘要:借助C++的constexpr能力,可以轻而易举的构造Parser Combinator,对用户定义的字符串(User defined literal)释放了巨大的潜力. ## 引子 前不久在C ...
- hystrix动态修改参数
Hystrix 从入门到深入——运行时修改动态配置 /** * * @author zhangshuo * */ @Component public class DynamicConfigSource ...
- 1.8HDFS细节
- 【Processing-日常1】小圆碰撞
之前在CSDN上发表过: https://blog.csdn.net/fddxsyf123/article/details/79741637
- Processing 状态量控制动画技巧
之前在CSDN上发表过: https://blog.csdn.net/fddxsyf123/article/details/62848357
- MySql WorkBench 导入sql文件 中文出现乱码
在workbench中导入sql文件. 查看系统的编码. 导入sql文件时出现了如下警告.但是文件是UTF-8.由于包含中文,使用latin1编码方式会出现乱码. 选择UTF-8,出现错误. 不知道什 ...
- Centos-yum软件包安装-yum
yum 自动安装相关软件依赖,可以同时配置多个yum源,初始启动yum时候首先会缓存资源包到 /var/cache/yum目录下 yum确认 -y yum安装和卸载 install 安装,自动安装软件 ...
- 一种统计ListView滚动距离的方法
注:本文同步发布于微信公众号:stringwu的互联网杂谈 一种统计ListView滚动距离的方法 ListView做为Android中最常使用的列表控件,主要用来显示同一类的数据,如应用列表,商品列 ...
- Go 指针相关
Go指针 Go语言中的指针非常简单,没有偏移和运算,只需要记住两个符号.&取变量地址与*根据地址取值. 以下是一个简单的示例: package main import ( "fmt& ...