oracle模糊查询mysql的区别
https://blog.csdn.net/weixin_38673554/article/details/86503982#_1
oracle与使用mysql的区别
https://www.cnblogs.com/nr-zhang/p/10553646.html
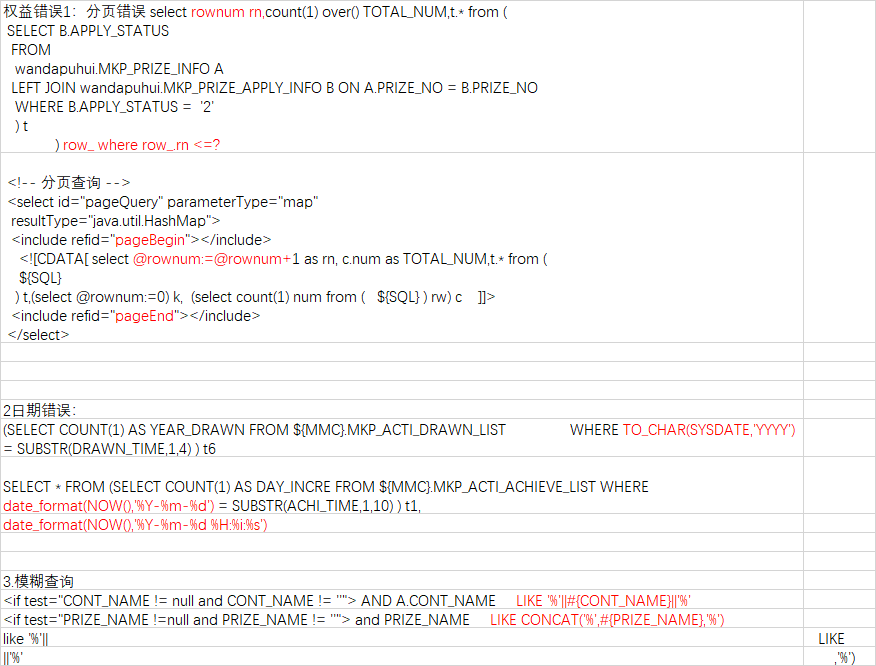
1.Like模糊查询有字符串拼接
所有用 str1||str2 拼接的字符串都要改成CONCAT(str1,str2)
'%'||#{zbmc}||'%'改成CONCAT('%',#{zbmc},'%')
a.fpdm||'-'||a.fphm 改成CONCAT(a.fpdm,'-',a.fphm)
Oracle中concat与||区别(以及与mysql中concat函数区别)
2. 分页查询
oracle中的ROWNUM
SELECT * FROM (SELECT ROWNUM rn,a.* from ( SELECT
A.* from FX_PZ A
) a where ROWNUM<=#{endRow} ) WHERE rn>#{startRow} order by ${sort} ${order}
1
2
3
改成
SELECT A.* from FX_PZ A
order by ${sort} ${order} limit #{startRow},#{rows}
1
2
注意limt关键字是最后才用到的。以下条件的出现顺序一般是:where->group by->having-order by->limit
Oracle与Mysql的分页比较
MySQL的Limit详解
3.Oracle中to_date/to_char函数改成MySql中的函数
to_date(#{kprqs},'yyyy-MM-dd')改成 str_to_date(#{kprqs},'%Y-%m-%d')
to_char(kprq,'yyyy-MM')改成date_format(kprq,'%Y-%m')
to_char(kprq,'q')改成 FLOOR((date_format(kprq, '%m')+2)/3))
mysql和oracle中的to_date()/to_char()互换
Oracle中的时间函数用法(to_date、to_char) (总结)
4.Oracle中nvl/decode函数改成MySql中的函数
nvl(sum(a.je),0)改成ifnull(sum(a.je),0)
nvl、ifnull 用法(将null转代为0)
decode(trim(s.fpzt),'0','正常','2','作废','3','红冲','')
改成
( case trim(s.fpzt)
when '0' then '正常'
when '2' then '作废'
when '3' then '红冲'
else '' end
)
1
2
3
4
5
6
decode(sum(sl), null, 0.00, sum(sl)) as sl,
改成
IFNULL(SUM(sl),0.00)或者( case when sum(je) is null then 0.00 else sum(je) end)
oracle/MySQL 中的decode的使用
5.Oracle中substr/to_number函数改成MySql中的函数
substr(kprq,0,8) 改成 substr(kprq,1,8)
mysql函数substr 注意脚标从1开始
Oracle中的substr()函数 详解及应用
to_number(b.field1)改成 cast(b.field1 as unsigned int)
select cast(11 as unsigned int) /整型/
select cast(11 as decimal(10,2)) /浮点型/
6.Oracle中MERGE INTO批量更新/插入改成MySql的批量更新插入
Mybatis批量新增或更新(mysql数据库)
<update id="updateFlbmBatch" parameterType="java.util.List">
MERGE INTO TAB_FLBM A
USING
<foreach collection="list" item="item" index="index"
separator="union">
(select
#{item.ssflbm,jdbcType=VARCHAR},
#{item.bb,jdbcType=VARCHAR},
#{item.qysj,jdbcType=VARCHAR},
#{item.gdqjzsj,jdbcType=VARCHAR}, #{item.spbm,jdbcType=VARCHAR},
#{item.spmc,jdbcType=VARCHAR},
#{item.sm,jdbcType=VARCHAR},
#{item.zzssl,jdbcType=VARCHAR},
#{item.gjz,jdbcType=VARCHAR},
#{item.hzx,jdbcType=CHAR},
#{item.kyzt,jdbcType=CHAR},
#{item.zzstsgl,jdbcType=VARCHAR},
#{item.zzszcyj,jdbcType=VARCHAR},
#{item.zzstsnrdm,jdbcType=VARCHAR}, #{item.xfsgl,jdbcType=VARCHAR},
#{item.xfszcyj,jdbcType=VARCHAR},
#{item.xfstsnrdm,jdbcType=VARCHAR},
#{item.tjjbm,jdbcType=VARCHAR},
#{item.pid,jdbcType=VARCHAR},
#{item.gxsj,jdbcType=VARCHAR}, #{item.bbh,jdbcType=VARCHAR},
#{item.spbmjc,jdbcType=VARCHAR},
#{item.hgjcksppm,jdbcType=CLOB} from
dual) b
</foreach>
on (a.ssflbm=b.ssflbm)
when matched then
update set a.BB = b.BB,
a.QYSJ = b.QYSJ,
a.GDQJZSJ = b.GDQJZSJ,
a.SPBM = b.SPBM,
a.SPMC = b.SPMC,
a.SM = b.SM,
a.ZZSSL = b.ZZSSL,
a.GJZ = b.GJZ,
a.HZX = b.HZX,
a.KYZT = b.KYZT,
a.ZZSTSGL = b.ZZSTSGL,
a.ZZSZCYJ = b.ZZSZCYJ,
a.ZZSTSNRDM = b.ZZSTSNRDM,
a.XFSGL = b.XFSGL,
a.XFSZCYJ = b.XFSZCYJ,
a.XFSTSNRDM = b.XFSTSNRDM,
a.TJJBM = b.TJJBM,
a.PID = b.PID,
a.GXSJ = b.GXSJ,
a.BBH = b.BBH,
a.SPBMJC = b.SPBMJC
when
not matched then
insert into TAB_FLBM (SSFLBM, BB, QYSJ,
GDQJZSJ, SPBM,
SPMC,
SM, ZZSSL, GJZ, HZX,
KYZT, ZZSTSGL, ZZSZCYJ,
ZZSTSNRDM, XFSGL,
XFSZCYJ,
XFSTSNRDM, TJJBM, PID,
GXSJ, BBH, SPBMJC)
values
(b.ssflbm, b.bb,
b.qysj,
b.gdqjzsj, b.spbm, b.spmc,
b.sm, b.zzssl,
b.gjz,
b.hzx,jdbcType=CHAR},
b.kyzt,jdbcType=CHAR}, b.zzstsgl,
b.zzszcyj,
b.zzstsnrdm, b.xfsgl, b.xfszcyj,
b.xfstsnrdm, b.tjjbm,
b.pid,
b.gxsj,
b.bbh, b.spbmjc)
</update>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
改成
<update id="updateFlbmBatch" parameterType="java.util.List">
insert into TAB_FLBM
(SSFLBM, BB, QYSJ,
GDQJZSJ, SPBM,
SPMC,
SM, ZZSSL, GJZ, HZX,
KYZT, ZZSTSGL, ZZSZCYJ,
ZZSTSNRDM, XFSGL,
XFSZCYJ,
XFSTSNRDM, TJJBM, PID,
GXSJ, BBH, SPBMJC)
values
<foreach collection="list" item="item" index="index"
separator=",">
(
#{item.ssflbm,jdbcType=VARCHAR},
#{item.bb,jdbcType=VARCHAR},
#{item.qysj,jdbcType=VARCHAR},
#{item.gdqjzsj,jdbcType=VARCHAR}, #{item.spbm,jdbcType=VARCHAR},
#{item.spmc,jdbcType=VARCHAR},
#{item.sm,jdbcType=VARCHAR},
#{item.zzssl,jdbcType=VARCHAR},
#{item.gjz,jdbcType=VARCHAR},
#{item.hzx,jdbcType=CHAR},
#{item.kyzt,jdbcType=CHAR},
#{item.zzstsgl,jdbcType=VARCHAR},
#{item.zzszcyj,jdbcType=VARCHAR},
#{item.zzstsnrdm,jdbcType=VARCHAR}, #{item.xfsgl,jdbcType=VARCHAR},
#{item.xfszcyj,jdbcType=VARCHAR},
#{item.xfstsnrdm,jdbcType=VARCHAR},
#{item.tjjbm,jdbcType=VARCHAR},
#{item.pid,jdbcType=VARCHAR},
#{item.gxsj,jdbcType=VARCHAR}, #{item.bbh,jdbcType=VARCHAR},
#{item.spbmjc,jdbcType=VARCHAR},
#{item.hgjcksppm,jdbcType=CLOB}
)
</foreach>
ON DUPLICATE KEY UPDATE
BB = BB,
QYSJ = QYSJ,
GDQJZSJ = GDQJZSJ,
SPBM = SPBM,
SPMC = SPMC,
SM = SM,
ZZSSL = ZZSSL,
GJZ = GJZ,
HZX = HZX,
KYZT = KYZT,
ZZSTSGL = ZZSTSGL,
ZZSZCYJ = ZZSZCYJ,
ZZSTSNRDM = ZZSTSNRDM,
XFSGL = XFSGL,
XFSZCYJ = XFSZCYJ,
XFSTSNRDM = XFSTSNRDM,
TJJBM = TJJBM,
PID = PID,
GXSJ = GXSJ,
BBH = BBH,
SPBMJC = SPBMJC
</update>
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
2019-01-10 补充
7.数据库类型 Oracle中number 改成 mysql中decimal
Oracle 版 类型是number 但是oracle中是直接 number 而没有写成 NUMBER(14,2) 还是会有小数位啊
Mysql版 类型是decimal 不添加小数位 小数部分就会四舍五入 所以这点需要注意
8.Oracle中is not null 和 mysql 中有区别
mysql 对 空字符串 和 null 有区分
is not null 在mysql中 如果该字段为 空字符串 那么就是 true 不会过滤掉
null 会被过滤掉
1
2
3
oracle对空字符串和null没有区分
is not null 在oracle中 如果该字段为 空字符串或 null 那么就是 false 会过滤掉
1
2
所以请注意 如果在MySQL中需要用到 is not null 不要设置字段默认值为 Empty String而是设置成null
MySQL中NULL与空字符串
————————————————
版权声明:本文为CSDN博主「csdn_yfqs」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/csdn_yfqs/article/details/83992739
oracle模糊查询mysql的区别的更多相关文章
- Oracle 模糊查询方法
在这个信息量剧增的时代,怎样帮助用户从海量数据中检索到想要的数据.模糊查询是不可缺少的. 那么在Oracle中模糊查询是怎样实现的呢? 一.我们能够在where子句中使用likeke ...
- Oracle模糊查询CONCAT参数个数无效
在使用MyBatis操作Oracle数据库的时候,写模糊查询突然发现原本在MySql中正确的代码,在Oracle中报错,参数个数无效 <if test="empId!=null and ...
- Oracle 模糊查询 优化
模糊查询是数据库查询中经常用到的,一般常用的格式如下: (1)字段 like '%关键字%' 字段包含"关键字"的记录 即使在目标字段建立索引也不会走索引,速度最慢 (2 ...
- oracle模糊查询效率提高
1.使用两边加‘%’号的查询,oracle是不通过索引的,所以查询效率很低. 例如:select count(*) from lui_user_base t where t.user_name lik ...
- oracle模糊查询效率可这样提高
1.使用两边加'%'号的查询,oracle是不通过索引的,所以查询效率很低. 例如:select count(*) from lui_user_base t where t.user_name lik ...
- oracle 模糊查询中的转义字符用法
drop view aaa; create view aaa as select '_BCDE' A FROM DUAL UNION ALL SELECT 'ABCDE' FROM DUAL UNIO ...
- Oracle模糊查询
通配符 % 匹配零个或更多的任意字符 _ 匹配一个任意字符 [ ] 匹配指定范围中的一个字符([a-z],[0-9]) [^ ] 不属于指定范围,不包含其中的字符 escape转义 --查询 ...
- oracle模糊查询提高效率的方法
转载:https://blog.csdn.net/weixiaohuai/article/details/83513957 https://blog.csdn.net/chihen/article/d ...
- mysql正则表达式,实现多个字段匹配多个like模糊查询
现在有这么一个需求 一个questions表,字段有题目(TestSubject),选项(AnswerA,AnswerB,AnswerC,AnswerD,AnswerE) 要求字段不包含png,jpg ...
随机推荐
- 一.C语言概述
C语言的起源 贝尔实验室的Dennis Ritchie在1972年开发了C,当时他正与ken Thompson一起设计UNIX操作系统,然而,C并不是完全由Ritchie构想出来的.它来自Thomps ...
- JavaScript--总结二(流程控制+调试)
表达式和语句 表达式------ 一个表达式可以产生一个值,有可能式运算,函数调用,有可能是字面量.表达式可以放在任何需要值的地方 语句----- 语句可以理解为一个行为,循环语句和判断语句就是典型的 ...
- MySQL安装8.0图文教程。超级详细
数据库安装 1.官网下载 接下来点击不用登录注册 2.安装 点击安装服务端 ,然后点击下一步 选择自己安装目录(一定要牢记)这里我选择默认目录,点击下一步 这里弹出警告,直接点击yes 直接点击exe ...
- 敏捷史话(三):笃定前行的勇者——Ken Schwaber
很多人之所以平凡,并不在于能力的缺失,而是因为缺乏迈出一步的勇气.只有少部分的人可以带着勇气和坚持,走向不凡.Ken Schwaber 就是这样的人,他带着他的勇气和坚持在敏捷的道路上不断前行,以实现 ...
- Flutter 基础组件:输入框和表单
前言 Material组件库中提供了输入框组件TextField和表单组件Form. 输入框TextField 接口描述 const TextField({ Key key, // 编辑框的控制器,通 ...
- Hdfs手动执行Balance
问题发现: 经巡检,服务器中一台节点的hadoop磁盘占用过多,是其它节点的三倍,导致数据严重不均衡. 解决过程: 两种命令: hadoop的bin目录下,运行命令start-balancer.sh ...
- 【Linux】Linux基础命令 - 目录相关的命令 ls 、cd、du
文章目录 目录相关的命令 ls 命令:列出文件和目录 cd 命令:切换目录 du 命令:显示目录包含的文件大小 总结 参考资料 巩固和复习Linux系统基础命令知识 目录相关的命令 ls 命令:列出文 ...
- 【九阳神功】Nessus 8_VM不限IP及AWVS破解版合体部署
Nessus 8下载地址: https://moehu-my.sharepoint.com/personal/ximcx_moebi_org/_layouts/15/download.aspx?Sou ...
- SVM 支持向量机算法-原理篇
公号:码农充电站pro 主页:https://codeshellme.github.io 本篇来介绍SVM 算法,它的英文全称是 Support Vector Machine,中文翻译为支持向量机. ...
- 【转】自定义ALV控件的工具条按钮
1 CLASS lcl_event_receiver DEFINITION DEFERRED. 2 3 DATA: itab TYPE TABLE OF spfli, 4 wa TYPE spfli. ...