统计学三大相关性系数:pearson,spearman,kendall
目录
- person correlation coefficient(皮尔森相关性系数-r)
- spearman correlation coefficient(斯皮尔曼相关性系数-p)
- kendall correlation coefficient(肯德尔相关性系数-k)
- R语言计算correlation
在文献以及各种报告中,我们可以看到描述数据之间的相关性:pearson correlation,spearman correlation,kendall correlation。它们分别是什么呢?计算公式?怎样用R语言简单实现计算呢?本文一一介绍~
建议前期阅读:协方差与相关系数-“傻傻”也能分清
总的来讲,三个相关性系数(pearson, spearman, kendall)反应的都是两个变量之间变化趋势的方向以及程度,其值范围为-1到+1,0表示两个变量不相关,正值表示正相关,负值表示负相关,值越大表示相关性越强
person correlation coefficient(皮尔森相关性系数-r)
公式: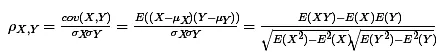
两个变量(X, Y)的皮尔森相关性系数(ρX,Y)等于它们之间的协方差cov(X,Y)除以它们各自标准差的乘积(σX, σY)。(分母是变量的标准差,这就意味着变量的标准差不能为0(分母不能为0),也就是说你每个变量所包含值不能都是相同的。如果没有变化,方差为0,那么是无法计算的)
方差是表示一个变量的波动情况,方差越小表示数据越集中,越大表示数据越离散;
标准差:等于(或近似等于)方差的开根号;
协方差:可以理解成两个变量之间的方差,其取值可以是负无穷到正无穷,它可以表示两个变量之间的变化趋势,但是不能表示它们之间的程度
局限性:
- 实验数据通常假设是成对的来自于正态分布的总体。为啥通常会假设为正态分布呢?因为我们在求皮尔森相关性系数以后,通常还会用t检验之类的方法来进行皮尔森相关性系数检验。
- 实验数据之间的差距不能太大,或者说皮尔森相关性系数受异常值的影响比较大。因为根据公式可以看到是直接是用x,y的值进行计算。相对应的spearman correlation对异常值不敏感,因为它是属于rank test,具体见下面介绍。
spearman correlation coefficient(斯皮尔曼相关性系数-p)
通常也叫斯皮尔曼秩相关系数。
“秩”,可以理解成就是一种顺序或者排序,那么它就是根据原始数据的排序位置进行求解,而不是直接是用x,y的值进行求解(因此对异常值不敏感,也不要求正态分布)。
公式: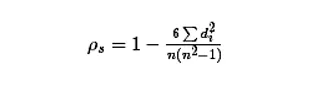
计算过程就是:
- 获得秩次:记下原始X Y值得排序位置(X’, Y’),(X’, Y’)的值就称为秩次
- 对两个变量(X, Y)的数据进行排序
- 计算两个变量秩次的差值,也就是上面公式中的di,n就是变量中数据的个数
- 最后带入公式就可求解结果。
举个例子吧,假设我们实验的数据如下: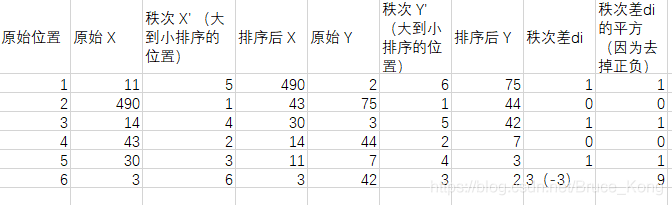
带入公式,求得斯皮尔曼相关性系数:ρ(s)= 1-6*(1+1+1+9)/6*35=0.657
不用管X和Y这两个变量具体的值到底差了多少,只需要算一下它们每个值所处的排列位置的差值,就可以求出相关性系数了。(如果原始数据中有重复值,则在求秩次时要以它们的平均值为准)
优势:
- 即便在变量值没有变化的情况下,也不会出现像皮尔森系数那样分母为0而无法计算的情况。
- 即使出现异常值,由于异常值的秩次通常不会有明显的变化(比如过大或者过小,那要么排第一,要么排最后),所以对斯皮尔曼相关性系数的影响也非常小
- 斯皮尔曼相关性系数没有那些数据条件要求,适用的范围广
pearson和spearman都是衡量连续型变量间的相关性,那么如果是分类变量呢?
kendall correlation coefficient(肯德尔相关性系数-k)
肯德尔相关性系数,又称肯德尔秩相关系数,它也是一种秩相关系数,不过它所计算的对象是分类变量。分类变量可以理解成有类别的变量,可以分为无序的,比如性别(男、女)、血型(A、B、O、AB),以及有序的,比如肥胖等级(重度肥胖,中度肥胖、轻度肥胖、不肥胖)。通常需要求相关性系数的都是有序分类变量。
例子:比如评委对选手的评分(优、中、差等),我们想看两个(或者多个)评委对几位选手的评价标准是否一致;或者医院的尿糖化验报告,想检验各个医院对尿糖的化验结果是否一致,这时候就可以使用肯德尔相关性系数进行衡量。
由于数据情况不同,求得肯德尔相关性系数的计算公式不一样,一般有3种计算公式,在这里就不繁琐地列出计算公式了,具体感兴趣的话可以自行搜寻资料。
R语言计算correlation
x <- c(seq(10))
y <- c(seq(11,20))
res <- cor.test(x, y,method = "pearson") # method 参数修改:“spearman","kendall"
# 具体见 ?cor.test
参考链接:聊聊统计学三大相关性系数
统计学三大相关性系数:pearson,spearman,kendall的更多相关文章
- 相关性分析 -pearson spearman kendall相关系数
先说独立与相关的关系:对于两个随机变量,独立一定不相关,不相关不一定独立.有这么一种直观的解释(不一定非常准确):独立代表两个随机变量之间没有任何关系,而相关仅仅是指二者之间没有线性关系,所以不难推出 ...
- 三大相关系数: pearson, spearman, kendall(python示例实现)
三大相关系数:pearson, spearman, kendall 统计学中的三大相关性系数:pearson, spearman, kendall,他们反应的都是两个变量之间变化趋势的方向以及程度,其 ...
- 【转】Pearson,Spearman,Kendall相关系数的具体分析
测量相关程度的相关系数很多,各种参数的计算方法及特点各异. 连续变量的相关指标: 此时一般用积差相关系数,又称pearson相关系数来表示其相关性的大小,积差相关系数只适用于两变量呈线性相关时.其数值 ...
- 相关性系数及其python实现
参考文献: 1.python 皮尔森相关系数 https://www.cnblogs.com/lxnz/p/7098954.html 2.统计学之三大相关性系数(pearson.spearman.ke ...
- 相似性 similarity | Pearson | Spearman | p-value | 相关性 correlation | 距离 distance | distance measure
这几个概念不能混淆,估计大部分人都没有完全搞懂这几个概念. 看下这个,非常有用:Interpret the key results for Correlation euclidean | maximu ...
- 相关性系数缺点与证明 k阶矩
相关性系数 https://baike.baidu.com/item/相关系数/3109424?fr=aladdin 缺点 需要指出的是,相关系数有一个明显的缺点,即它接近于1的程度与数据组数n相关, ...
- PHP 相关性系数计算
相关系数公式 参考:https://baike.baidu.com/item/相关系数 PHP 实现代码 public static function calc($list) { $cv = []; ...
- Python数据分析与展示[第三周](pandas数据特征分析单元8)
数据理解 基本统计 分布/累计统计 数据特征 数据挖掘 数据排序 操作索引的排序 .sort_index() 在指定轴上排序,默认升序 参数 axis=0 column ascending=True ...
- 数据分析R语言1
数据分析R语言 无意中发现网上的一个数据分析R应用教程,看了几集感觉还不错,本文做一个学习笔记(知识点来源:视频内容+R实战+自己的理解),视频详细的信息请参考http://www.itao521.c ...
随机推荐
- 浅谈JavaScript代码性能优化2
一.减少判断层级 从下图代码中可以明显看出,同样的效果判断层级的减少可以优化性能 二.减少作用域链查找层级 简单解释下,下图中第一个运行foo函数,bar函数内打印name,bar作用域内没有name ...
- SQL Server 日志收缩方法
在日常运维中,有时会遇到"The transaction log for database 'xxxx' is full due to 'ACTIVE_TRANSACTION'." ...
- SpringBoot 2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池.按照发展历程,业界知名的数据库连接池有以下几种:c3p0.DBCP.Tomcat JDBC ...
- Python+Selenium+Unittest实现PO模式web自动化框架(3)
1.Outputs目录下的具体目录功能 2.logs目录 logs目录是用于存放log日志的一个目录. 2.reports目录 reports目录是用于存放测试报告的. 3.screenshots目录 ...
- day03 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8.内置函数
本节内容 1. 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8.内置函数 温故知新 1. 集合 主要作用: 去重 关系测 ...
- hadoop 集群搭建 配置 spark yarn 对效率的提升永无止境 Hadoop Volume 配置
[手动验证:任意2个节点间是否实现 双向 ssh免密登录] 弄懂通信原理和集群的容错性 任意2个节点间实现双向 ssh免密登录,默认在~目录下 [实现上步后,在其中任一节点安装\配置hadoop后,可 ...
- centos7-docker的安装过程
一.卸载旧版本以及依赖(第一次安装忽略) sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ ...
- python基础三---- time模块,函数的定义和调用
此处重点说明一下: 注意: 1.用例之间不要存在依赖关系,每个用例都可以单独运行 2.用例不要互相调用,需要调用的公共方法可以写成方法去调用 1.等待 (在脚本运行的时候,有些线程之间需要间隔时间,可 ...
- Vue3.0短视频+直播|vue3+vite2+vant3仿抖音界面|vue3.x小视频实例
基于vue3.0构建移动端仿抖音/快手短视频+直播实战项目Vue3-DouYin. 5G时代已来,短视频也越来越成为新一代年轻人的娱乐方式,在这个特殊之年,又将再一次成为新年俗! 基于vue3.x+v ...
- Java——I/O,字节流与字符流,BufferedOutputStream,InputStream等(附相关练习代码)
I/O: I/O是什么? 在程序中,所有的数据都是以流的形式进行传输或者保存. 程序需要数据的时候,就要使用输入流读取数据. 程序需要保存数据的时候,就要使用输出流来完成. 程序的输入以及输出都是以流 ...