json&pickle&shelve
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
import json
x="[null,true,false,1]"
print(eval(x))
print(json.loads(x))
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
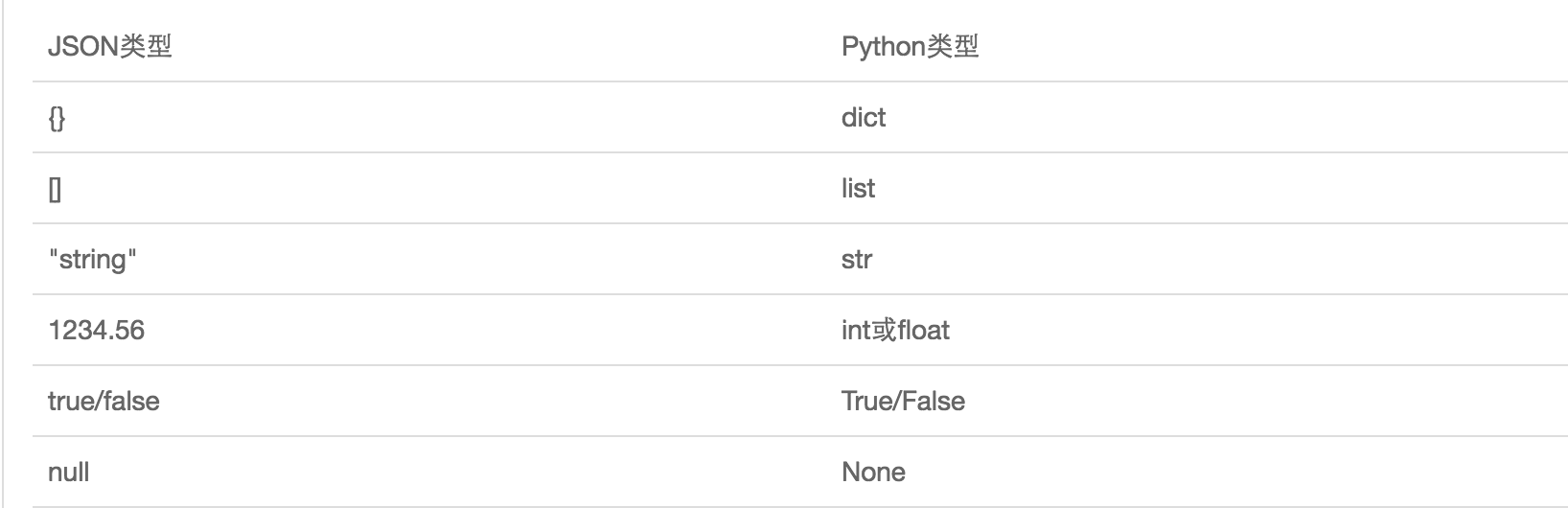
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
#----------------------------序列化
import json dic={'name':'alvin','age':23,'sex':'male'}
print(type(dic))#<class 'dict'> j=json.dumps(dic)
print(type(j))#<class 'str'> f=open('序列化对象','w')
f.write(j) #-------------------等价于json.dump(dic,f)
f.close()
#-----------------------------反序列化<br>
import json
f=open('序列化对象')
data=json.loads(f.read())# 等价于data=json.load(f)
pickle
##----------------------------序列化
import pickle dic={'name':'alvin','age':23,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic)
print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f) f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f) print(data['age'])
Pickle的问题和所有其他编程语言特有的序列化问题一样,就是它只能用于Python,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f = shelve.open(r'shelve.txt')
# f['stu1_info']={'name':'alex','age':'18'}
# f['stu2_info']={'name':'alvin','age':'20'}
# f['school_info']={'website':'oldboyedu.com','city':'beijing'}
#
#
# f.close()
print(f.get('stu_info')['age'])
原文链接:https://www.cnblogs.com/yuanchenqi/articles/5732581.html
json&pickle&shelve的更多相关文章
- python序列化: json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- python 全栈开发,Day25(复习,序列化模块json,pickle,shelve,hashlib模块)
一.复习 反射 必须会 必须能看懂 必须知道在哪儿用 hasattr getattr setattr delattr内置方法 必须能看懂 能用尽量用__len__ len(obj)的结果依赖于obj. ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
- 常用模块(random,os,json,pickle,shelve)
常用模块(random,os,json,pickle,shelve) random import random print(random.random()) # 0-1之间的小数 print(rand ...
- day6_python序列化之 json & pickle & shelve 模块
一.json & pickle & shelve 模块 json,用于字符串 和 python数据类型间进行转换pickle,用于python特有的类型 和 python的数据类型间进 ...
- Python学习笔记——基础篇【第六周】——json & pickle & shelve & xml处理模块
json & pickle 模块(序列化) json和pickle都是序列化内存数据到文件 json和pickle的区别是: json是所有语言通用的,但是只能序列化最基本的数据类型(字符串. ...
- Day 4-5 序列化 json & pickle &shelve
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 反序列化: 把字符转成内存里的数据类型. 用于序列化的两个模块.他 ...
- 模块 - json/pickle/shelve/xml/configparser
序列化: 序列化是指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes. 为什么要序列化: 有种办法可以直接把内存数据(eg:10个列表,3 ...
- Python模块:shutil、序列化(json&pickle&shelve)、xml
shutil模块: 高级的 文件.文件夹.压缩包 处理模块 shutil.copyfileobj(fscr,fdst [, length]) # 将文件内容拷贝到另一个文件中 import shu ...
- Python json & pickle & shelve模块
json & pickle 之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇 ...
随机推荐
- JavaScript学习 Ⅴ
十. 一些对象 Date 对象 Date对象用来表示一个时间 创建Date对象 如果直接使用构造函数创建一个Date对象,则会封装为当前代码执行的时间 var d = new Date(); 创建一个 ...
- celery 基础教程(四):定时任务
简介 celery beat 是一个调度器:它以常规的时间间隔开启任务,任务将会在集群中的可用节点上运行. 默认情况下,入口项是从 beat_schedule 设置中获取,但是自定义的存储也可以使用, ...
- 数据可视化之DAX篇(二十八)Power BI时间序列分析用到的度量值,一次全给你
https://zhuanlan.zhihu.com/p/88528732 在各种经营分析报告中,我们常常会看到YTD,YOY这样的统计指标,这样的数据计算并不难,尤其是在PowerBI中,因为有时间 ...
- redis(一):Redis 数据类型
Redis 数据类型 Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合). String(字符串) st ...
- Python之堡垒机
本节内容 项目实战:运维堡垒机开发 前景介绍 到目前为止,很多公司对堡垒机依然不太感冒,其实是没有充分认识到堡垒机在IT管理中的重要作用的,很多人觉得,堡垒机就是跳板机,其实这个认识是不全面的,跳板功 ...
- 用Python演奏音乐
目录 背景 准备 安装mingus 下载并配置fluidsynth 下载soundfont文件 分析 乐谱格式 乐谱解析 弹奏音乐 添加伴奏 保存音乐 完整程序 背景 笔者什么乐器也不会,乐理知识也只 ...
- 一、Python系列——函数的应用之名片管理系统
card_list = [] def main_desk(): print('*'*50) print('欢迎使用[名片管理系统]V1.0') print('1.新建名片') print('2.显示全 ...
- Active Directory - Right Delegation and Audit
Delegate proper right to some user: Login/Logout Audit - GPO Setting - Event Viewer File Auditing M ...
- 视图相关SQL
前面介绍了视图的概念和作用,接下来简单的用实例SQL来展现视图. 例如:首先,创建表e_information.表e_shareholder: 然后插入表数据等,在此,这简单的部分我就省略了,直接写视 ...
- 基于Scrapy的B站爬虫
基于Scrapy的B站爬虫 最近又被叫去做爬虫了,不得不拾起两年前搞的东西. 说起来那时也是突发奇想,想到做一个B站的爬虫,然后用的都是最基本的Python的各种库. 不过确实,实现起来还是有点麻烦的 ...