php解析word,获得文档中的图片
背景
前段时间在写一个功能:用原生php将获得word中的内容并导入到网站系统中。因为文档中存在公式,图片,表格等,因此写的比较麻烦。
思路
大体思路是先将word中格式为doc的文档转化为docx,用预处理程序将文档中的公式转化为swf图片格式,将word转化为xml格式,在获得xml中的内容转化为json格式。
预备知识
1. 理解xml基础
xml是一种可扩展标记语言,是互联网数据传输的重要工具,xml可以实现跨互联网平台而不受编程语言和操作系统的限制,可以说是一个拥有互联网最高级别通行证的数据携带者。
xml是当前处理结构化文档信息中的技术,有助于在服务器之间穿梭结构化出具,使得开发工作者可以更加方便的控制数据的存储和传输
xml用于标记电子文件使其具有结构性的标记语言,可用来标记数据,定义数据类型,是一种允许用户对自己的标记语言进行定义的源语言。它是标准通用语言的子集,非常适合web传输。
具体的详解可以看这里:https://blog.csdn.net/com_ma/article/details/73277535
2. word的两种不同的存储方式
word文档的两种存储格式:doc和docx
doc:习惯上被称为word,采用二进制存储数据
docx:也就是word2007,采用xml存储数据
那么后缀明明是docx格式的,为什么成xml格式了?
选择一个test.docx,将后缀名改为.zip,然后进行解压,得到下面的目录结构:
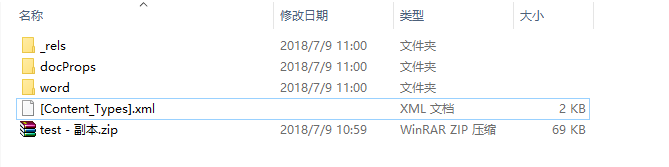
所以你认为的docx文档,其实是一个压缩文件~
3. 了解DOM和PHP DOM XML解析
DOM提供了针对html和xml文档的标准对象集,以及用于访问和操作这些文档的标准接口。XML DOM是为文档定义标准的对象集。使用PHP DOM扩展可以实现PHP对DOM树的一系列操作。
使用PHP DOM读取一个XML文档:
test.xml:
<?xml version="1.0" encoding="utf-8"?>
<teststore>
<test>
<name>php dom test</name>
<author>test-one</author>
</test>
<test>
<title>php dom test 2</title>
<author>test-two</author>
</test>
</teststore>
test.php:
<?php
$doc = new DOMDocument();
$doc->load("test.xml");
//获取标签对象
$book=$doc->getElementsByTagName("test");
//输出第一个中的值
echo $book->item(0)->nodeValue; echo "<br>----------------<br>"; $title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue; echo "<br>----------------<br>";
//遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}
结果:

4. word中xml的定义格式
word中的数据是怎么定义的呢??
我们只会介绍连个l两个文件/文件夹:
一个文件是word/document.xml,这个文件定义了word整个文档的内容。
另一个文件夹是word/media,这个文件夹存放着文档的多媒体内容,换句话说文档中所有的图片,音频视频都是在这个文件夹下存放。
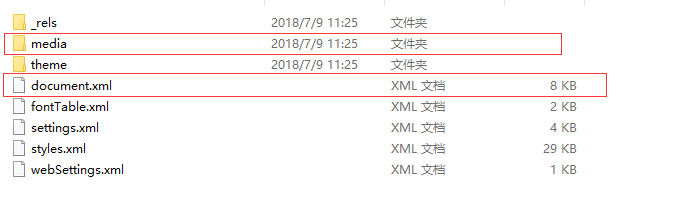
document.ml中的整体结构定义:
<w:document mc:ignorable="w14 w15 wp14" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpscustomdata="http://www.wps.cn/officeDocument/2013/wpsCustomData">
<w:body>
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>
文档段落内容:
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
<w:spacing w:after="150" w:afterautospacing="0" w:before="150" w:beforeautospacing="0" w:line="378" w:linerule="atLeast">
</w:spacing>
<w:ind w:firstline="0" w:left="0" w:right="0">
</w:ind>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
</w:rpr>
</w:ppr>
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:t>
作者: Test
</w:t>
</w:r>
</w:p>
图片内容定义:
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:drawing>
<wp:inline distb="0" distl="114300" distr="114300" distt="0">
<wp:extent cx="5543550" cy="5543550">
</wp:extent>
<wp:effectextent b="0" l="0" r="0" t="0">
</wp:effectextent>
<wp:docpr descr="IMG_256" id="1" name="Picture 1">
</wp:docpr>
<wp:cnvgraphicframepr>
<a:graphicframelocks nochangeaspect="1" xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
</a:graphicframelocks>
</wp:cnvgraphicframepr>
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
<a:graphicdata uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:nvpicpr>
<pic:cnvpr descr="IMG_256" id="1" name="Picture 1">
</pic:cnvpr>
<pic:cnvpicpr>
<a:piclocks nochangeaspect="1">
</a:piclocks>
</pic:cnvpicpr>
</pic:nvpicpr>
<pic:blipfill>
<a:blip r:embed="rId4">
</a:blip>
<a:stretch>
<a:fillrect>
</a:fillrect>
</a:stretch>
</pic:blipfill>
<pic:sppr>
<a:xfrm>
<a:off x="0" y="0">
</a:off>
<a:ext cx="5543550" cy="5543550">
</a:ext>
</a:xfrm>
<a:prstgeom prst="rect">
<a:avlst>
</a:avlst>
</a:prstgeom>
<a:nofill>
</a:nofill>
<a:ln w="9525">
<a:nofill>
</a:nofill>
</a:ln>
</pic:sppr>
</pic:pic>
</a:graphicdata>
</a:graphic>
</wp:inline>
</w:drawing>
</w:r>
结论:
<w:document> 定义整个文档的开始
<w:body> document的子节点,文档的主体内容
<w:p> body的子节点,一个段落,就是word文档中的段落
<w:r> p元素的子节点,一个Run定义了段落中具有相同格式的一段内容
<w:t> Run元素节点的子节点,就是文档的内容
<w:drawing> run元素的子节点,定义了一张图片
<w:inline> drawing子节点,具体应用没有研究
<a:graphic> 定义了图片内容
<pic:blipfill> graphic文档的子节点,定义了图片内容的索引.
具体的说,如果用java,那么XWPF解析docx文档就是做xml文档解析,获得所有的节点并转换成更好用的属性提供API进行使用,在java中poi能根据这个名称拿到图片相对应的资源,而获取图片位置的关键也就是这里。

但是很不幸,我用的是php~~~所以我们需要通过php的相关接口手动实现获得图片.
下面说一下我的具体思路:通过PHP的内置DOMDocument接口获得docx文档的xml节点,遍历xml节点找到保存图片的节点元素,向下遍历图片节点扎到r:embed索引的值。因为docx文档是一个压缩包格式,所以通过PHP内置接口ZipArchive接口遍历该docx文档(实质就是遍历.zip压缩包),通过索引找到对应的图片,转换成二进制数据,在拼接img标签显示格式为base64的图片数据。
转换成xml:
private $rels_xml;
private $doc_xml; private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file'); if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file'); $this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML(); $this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML(); }
判断是否为图片节点:
if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
}
获得图片索引:
private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
}
显示压缩包中图片文件:
private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 < 10) ? mb_substr($file_name,mb_strlen($imgname,"utf-8"),1, 'utf-8') : '';
if($rIdIndex-8 < 10 && $a != '.') continue;
if ($enter_zp = zip_entry_open($zip, $zip_entry, "r")) { //读取包中文件
$ext = pathinfo(zip_entry_name ($zip_entry),PATHINFO_EXTENSION);//获取图片文件扩展名
$content = zip_entry_read($zip_entry,zip_entry_filesize($zip_entry));//读取文件二进制数据
return sprintf('<img src="data:image/%s;base64,%s">', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}
php解析word,获得文档中的图片的更多相关文章
- Java解析word,获取文档中图片位置
前言(背景介绍): Apache POI是Apache基金会下一个开源的项目,用来处理office系列的文档,能够创建和解析word.excel.ppt格式的文档. 其中对word文档的处理有两个技术 ...
- C# 提取Word文档中的图片
C# 提取Word文档中的图片 图片和文字是word文档中两种最常见的对象,在微软word中,如果我们想要提取出一个文档内的图片,只需要右击图片选择另存为然后命名保存就可以了,今天这篇文章主要是实现使 ...
- 在LaTeX文档中插入图片的几种常用的方法
LaTeX中一般只直接支持插入eps(Encapsulated PostScript)格式的图形文件, 因此在图片插入latex文档之前应先设法得到图片的eps格式的文件. 在LaTeX文档中插入图片 ...
- 利用POI操作不同版本号word文档中的图片以及创建word文档
我们都知道要想利用java对office操作最经常使用的技术就应该是POI了,在这里本人就不多说到底POI是什么和怎么用了. 先说本人遇到的问题,不同于利用POI去向word文档以及excel文档去写 ...
- dom4j解析xml报"文档中根元素后面的标记格式必须正确"
今天,在写个批量启动报盘机的自动化应用,为了简化起见,将配置信息存储在xml中,格式如下: <?xml version="1.0" encoding="UTF-8& ...
- python实现解析markdown文档中的图片,并且保存到本地~
背景 前阵子简书好像说是凉了,搞得我有点小慌,毕竟我的大部分博客都是放在简书上面的,虽然简书提供了打包导出功能,但是只能导出文字,图片的话还是存在简书服务器上面,再加上我一直想要重新做一个个人博客,于 ...
- 【.net 深呼吸】导出 Office 文档中的图片
我们常用的 Office 文档其实就三种——Word.Excel.PowerPoint,分别对应的扩展名为:.docx..pptx..xlsx. 许多教程都告诉我们,要提取这些文件中的图片(其实像视频 ...
- 将Word,PDF文档转化为图片
#region 将Word文档转化为图片 /// <summary> /// 将Word文档转化为图片 /// </summary> /// <param name=&q ...
- 第一节:python提取PDF文档中的图片
由于项目需要将PDF文档当中的图片转换成图片,所以参考了这篇文章https://blog.csdn.net/qq_15969343/article/details/81673302后项目得以解决. 1 ...
随机推荐
- Ruby快速入门
Rb是什么 ? 交互式Ruby(IRB)为实验提供了一个shell.内置IRB shell,你可以立即一行行查看表达式的结果.该工具自带Ruby安装,所以你必须做一些额外的IRB工作无关.只需键入在命 ...
- Android 一些注意
半年没碰android,想给一个按钮写个click,硬是想不起来怎么搞,哎! 1.编码问题调整 2.引用框架问题 3.界面设计无法显示问题,需要调整设计界面的API Level 4.任意输入自动提示 ...
- srping boot thymeleaf 学习总结 (2) - thymeleaf properties 国际化 mesaage
thymeleaf获取配置properties中的数据与thymeleaf国际化(摘录) 使用thymeleaf提供的国际化 有时候会有直接在模板中获取配置文件properties中的配置信息,比如: ...
- 指向字符串的指针在printf与cout区别
根据指针用法: * 定义一个指针, &取变量地址, int b = 1; int *a = &b; 则*a =1,但对于字符串而言并非如此,直接打印指向字符串的指针打印的是地址还是字符 ...
- windows平台使用spark-submit以client方式提交spark应用到standalone集群
1.spark应用打包,我喜欢打带依赖的,这样省事. 2.使用spark-submit.bat 提交应用,代码如下: for /f "tokens=1,2 delims==" %% ...
- Google Tango初学者教程
Getting Started with the Tango Java API In this tutorial, we'll go through setting up your build env ...
- (最小生成树)Eddy's picture -- hdu -- 1162
链接: http://acm.hdu.edu.cn/showproblem.php?pid=1162 Time Limit: 2000/1000 MS (Java/Others) Memory ...
- mysql server 自动断开的问题
今天发现mysql的一个问题,当跑update语句的时候,mysql 服务会自动断掉,无论用 phpmyadmin, navicat , mysql workbench 甚至用 mysql命令行效果一 ...
- 三部曲搭建本地nuget服务器(图文版)
下载Demo: 1.新建web的空项目 2.引入nuget包 3.修改配置文件config(可以默认) 运行效果:
- 比较git commit 两个版本之间次数
#!/bin/bash f1="$1*" f2="$2*" echo "第一个版本:"$f1 echo "第二个版本:" ...