查询反模式 - GroupBy和HAVING的理解
为了最简单地说明问题,我特地设计了一张这样的表。
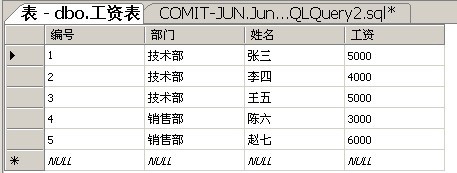
一、GROUP BY单值规则
规则1:单值规则,跟在SELECT后面的列表,对于每个分组来说,必须返回且仅仅返回一个值。
典型的表现就是跟在SELECT后面的列,如果没有使用聚合函数,必须出现在GROUP BY子句后面。
如下面这个查询报错:
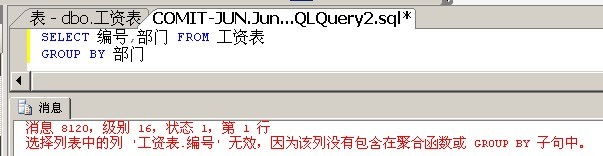
因为对于按照部门分组之后,技术部分组有3个编号,销售部分组有2个编号,你让数据库显示哪个呢?
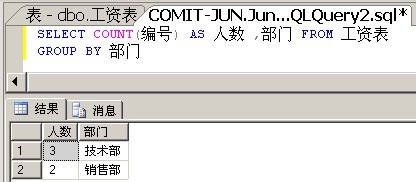
如果假设你使用聚合函数COUNT(编号)之后,对于每个部门分组,就只有一个值 - 该部门下的人数:
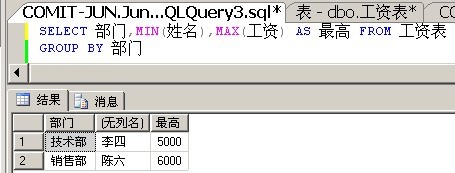
下面来实战下,我们希望查询出每个部门,最高工资的那个人的姓名,部门,工资。
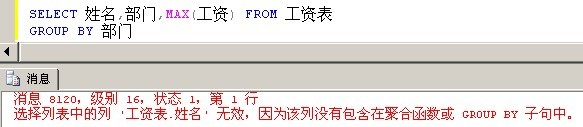
Shit,出师不利。第一次实战就错误了,我们来分析下。
很明显,上面的姓名列是不符合单值规则的。我们的一厢情愿想法是,MAX(工资)之后,SQL Server就能自动帮我们返回不符合单值规则的'姓名'。但是很遗憾,SQL Server并没有这么做。理由如下:
- 如果两个人的工资相同,那么应该将哪个人的姓名返回?
- 如果我们使用的不是MAX()聚合函数,而是SUM、AVG等聚合函数(没有与之匹配的工资),那么姓名返回哪个?
- 如果在查询语句中使用了两个聚合函数,如MAX(),MIN()。那么应该返回的是MAX工资的姓名,还是MIN工资的姓名呢?
综上所述,数据库是不可能能够根据我们输入的一个聚合函数,就帮助我们判断并显示出不符合单值规则的列的。
对于MYSQL来说,当有这种不符合单值规则的列时,默认是返回这一组结果的第一条记录。而SQLite是返回最后一条。
因此,对于以上查询,我们要另寻解决方案。
解决方案1:关联子查询
SELECT 姓名,部门,工资 FROM 工资表 AS T1
WHERE NOT EXISTS (SELECT NULL FROM 工资表 AS T2 WHERE T1.部门 = T2.部门 AND T2.工资 > T1.工资)
输出如下:
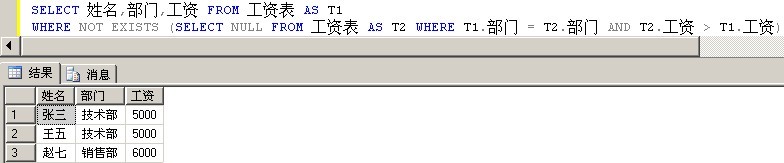
完全符合要求。对于上面的关联子查询,可以理解为:
遍历工资表的所有记录,查找不存在比当前记录部门相同且工资还大的记录。
虽然,关联子查询的语法非常简单,但是性能并不好。因为对于每一条记录,都要执行一次子查询。
解决方案2:衍生表
使用衍生表的思路是,先执行一个子查询,得到一个临时结果集,然后用临时结果集和原表进行INNER JOIN操作。就能得到最高工资的人的信息。
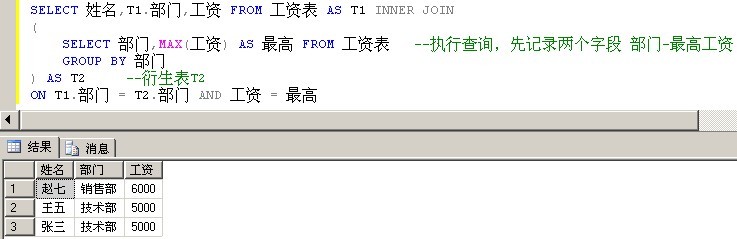
刚写出这个SQL语句时,觉得非常妙,理解了之后觉得非常妙。
SELECT 姓名,T1.部门,工资 FROM 工资表 AS T1 INNER JOIN
(
SELECT 部门,MAX(工资) AS 最高 FROM 工资表 --执行查询,先记录两个字段 部门-最高工资
GROUP BY 部门
) AS T2 --衍生表T2
ON T1.部门 = T2.部门 AND 工资 = 最高
衍生表的方式性能优于关联子查询,因为衍生表的方式只执行了一次子查询。但是它需要一张临时表来存储临时记录。因此,这个方案也并不是最佳的解决方案。
解决方案3:使用JOIN + IS NULL
这是一个更妙的解决方案,当我们用一个外联结去匹配记录时,当匹配的记录不存在,就会用NULL来代替相应的列。
我们先来看一条非常简答的SQL语句:

从中你看到了什么?当T2表中,不存在比T1表中工资高的记录时就返回NULL。
那么,那么,那么一个IS NULL是不是就解决问题了呢?
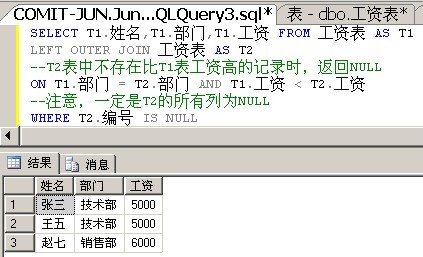
好妙,好妙的方法,让人拍案叫绝的使用了OUTER JOIN。
JOIN解决方案适用于针对大量数据查询并且可伸缩比较时。它总是能比基于子查询的解决方案更好地适应数据量的变量。
解决方案4:对额外的列使用聚合函数
我们知道,GROUP BY时,SELECT列表必须返回的是单值,那么我们可不可以通过使用聚合函数,让这个列返回单值呢?答案是可以的。
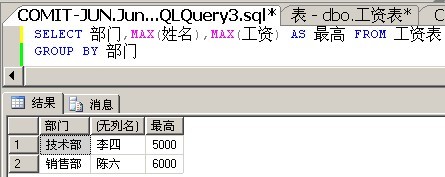
其实,返回的数据是有问题的,当工资相同时,它就返回按姓名从大到小排列的第一个姓名。也就是说,当工资相同时,它只能够返回一条记录。
我们将聚合函数换成MIN看看。
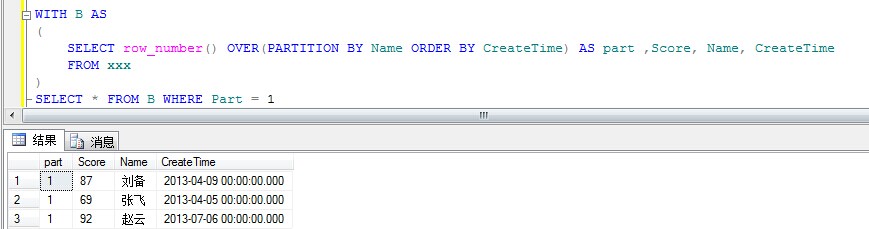
解决方案5:Row_Number() + OVER
WITH B AS
(
SELECT row_number() OVER(PARTITION BY Name ORDER BY CreateTime) AS part ,Score, Name, CreateTime
FROM xxx
)
SELECT * FROM B WHERE Part = 1
输出如下:
二、HAVING的理解
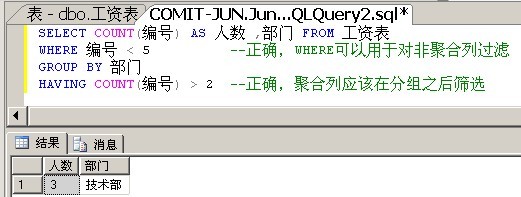
WHERE与HAVING的区别:
- WHERE(分组前过滤):WHERE不能对聚合函数列进行过滤,因为执行WHERE的时候,分组尚未执行,聚合函数也未执行。
- HAVING(分组后过滤):主要用于对聚合函数列进行过滤,因为HAVING实在分组之后执行的。HAVING子句只能配合GROUP BY子句使用。没有GROUP BY子句时不能使用HAVING。
错误使用WHERE的示例:

正确使用WHERE与HAVING的示例:
查询反模式 - GroupBy和HAVING的理解的更多相关文章
- 查询反模式 - GroupBy、HAVING的理解
为了最简单地说明问题,我特地设计了一张这样的表. 一.GROUP BY单值规则 规则1:单值规则,跟在SELECT后面的列表,对于每个分组来说,必须返回且仅仅返回一个值. 典型的表现就是跟在SELEC ...
- 查询反模式 - 正视NULL值
一.提出问题 不可避免地,我们都数据库总有一些字段是没有值的.不管是插入一个不完整的行,还是有些列可以合法地拥有一些无效值.SQL 支持一个特殊的空值,就是NULL. 在很多时候,NULL值导致我们的 ...
- SQL反模式学习笔记1 开篇
什么是“反模式” 反模式是一种试图解决问题的方法,但通常会同时引发别的问题. 反模式分类 (1)逻辑数据库设计反模式 在开始编码之前,需要决定数据库中存储什么信息以及最佳的数据组织方式和内在关联方式. ...
- FWORK-数据存储篇 -- 范式与反模式 (学习和理解)
理解 1.第二范式的侧重点是非主键列是否完全依赖于主键,还是依赖于主键的一部分.第三范式的侧重点是非主键列是直接依赖于主键,还是直接依赖于非主键列. 2. 反模式 范式可以避免数据冗余,减少数据库的 ...
- SQL反模式学习笔记18 减少SQL查询数据,避免使用一条SQL语句解决复杂问题
目标:减少SQL查询数据,避免使用一条SQL语句解决复杂问题 反模式:视图使用一步操作,单个SQL语句解决复杂问题 使用一个查询来获得所有结果的最常见后果就是产生了一个笛卡尔积.导致查询性能降低. 如 ...
- 第二天,导出文件sql,查询,视图view,聚合函数,反模式,字符串处理函数
//把数据库导出到脚本文件mysqldump -uroot -p1234 --databases abc > d:/a/abc.sql CREATE TABLE stud( id INT PRI ...
- SQL反模式学习笔记2 乱穿马路
程序员通常使用逗号分隔的列表来避免在多对多的关系中创建交叉表, 将这种设计方式定义为一种反模式,称为“乱穿马路”. 目标: 存储多属性值,即多对一 反模式:将多个值以格式化的逗号分隔存储在一个字段中 ...
- SQL反模式学习笔记4 建立主键规范【需要ID】
目标:建立主键规范 反模式:每个数据库中的表都需要一个伪主键Id 在表中,需要引入一个对于表的域模型无意义的新列来存储一个伪值,这一列被用作这张表的主键, 从而通过它来确定表中的一条记录,即便其他的列 ...
- SQL反模式学习笔记15 分组
目标:查询得到每组的max(或者min等其他聚合函数)值,并且得到这个行的其他字段 反模式:引用非分组列 单值规则:跟在Select之后的选择列表中的每一列,对于每个分组来说都必须返回且仅返回一直值. ...
随机推荐
- c++第二十九天
p143~p151:其他隐式类型转换1.数组转换成指针,大多数表达式自动转换成指向数组首元素的指针. 2.指针的转换. 3.转换成布尔类型,例如在if (condition) 中. 4.转换成常量. ...
- Python面试题之Python中的类和实例
0x00 前言 类,在学习面向对象我们可以把类当成一种规范,这个思想就我个人的体会,感觉很重要,除了封装的功能外,类作为一种规范,我们自己可以定制的规范,从这个角度来看,在以后我们学习设计模式的时候, ...
- 20145322何志威《网络对抗》逆向及Bof基础
20145322何志威<网络对抗>逆向及Bof基础 实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任 ...
- sqlmap简单使用方法
sqlmap使用 注入点 http://1xx.xxx.xxx.xxxx/dvwa/vulnerabilities/sqli/index.php?id=1&Submit=Submit# 通 ...
- CentOS7.2 切换成iptables规则
关闭firewall service firewalld stop systemctl disable firewalld.service #禁止firewall开机启动 安装iptables规则: ...
- MyBatis基本工作原理
Application是程序员开发的Java代码,蓝色为MyBatis框架. API是MyBatis提供的增删改查等功能接口. 老式SQL写法我们在Dao中写SQL: SELECT * FROM us ...
- Solidity 官方文档中文版 4_Solidity 编程实例
Voting 投票 接下来的合约非常复杂,但展示了很多Solidity的特性.它实现了一个投票合约.当然,电子选举的主要问题是如何赋予投票权给准确的人,并防止操纵.我们不能解决所有的问题,但至少我们会 ...
- Linux删除重复行 排序和不排序的做法--转载
本文部分翻译自这里,来自 Jadu Saikia 的博客,这个博客上有很多非常有用的小技巧,有空可以多看看. 通常如果我们想获取一个文件里不重复的行的时候,我们可以直接通过 sort -u 命令,先把 ...
- hdu 1251 trie树
统计难题 Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131070/65535 K (Java/Others) Problem De ...
- Mac for MySQL 5.7 安装教程
一.环境 MAC OS X 10.10 二.下载MySQL 地址:http://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.10-osx10.10- ...