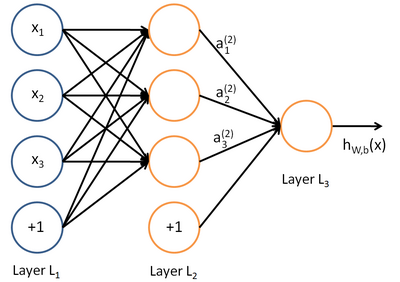
BP(back propagation)反向传播
转自:http://www.zhihu.com/question/27239198/answer/89853077
机器学习可以看做是数理统计的一个应用,在数理统计中一个常见的任务就是拟合,也就是给定一些样本点,用合适的曲线揭示这些样本点随着自变量的变化关系。
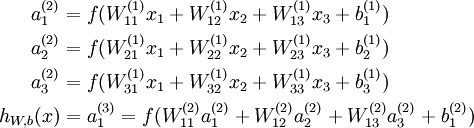
梯度下降法需要给定一个初始点,并求出该点的梯度向量,然后以负梯度方向为搜索方向,以一定的步长进行搜索,从而确定下一个迭代点,再计算该新的梯度方向,如此重复直到cost收敛。那么如何计算梯度呢?
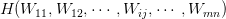 ,
, 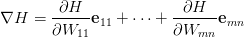
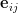 表示正交单位向量。为此,我们需求出cost函数H对每一个权值Wij的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。
表示正交单位向量。为此,我们需求出cost函数H对每一个权值Wij的偏导数。而BP算法正是用来求解这种多层复合函数的所有变量的偏导数的利器。它的复合关系画出图可以表示如下:
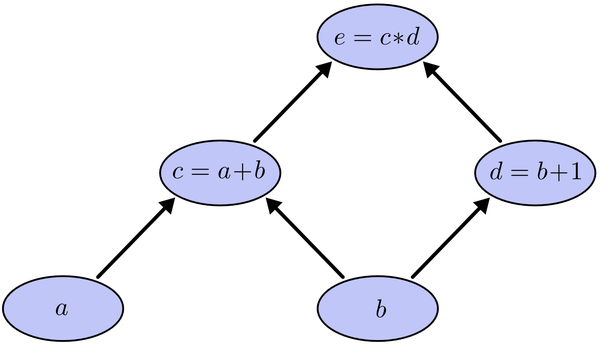
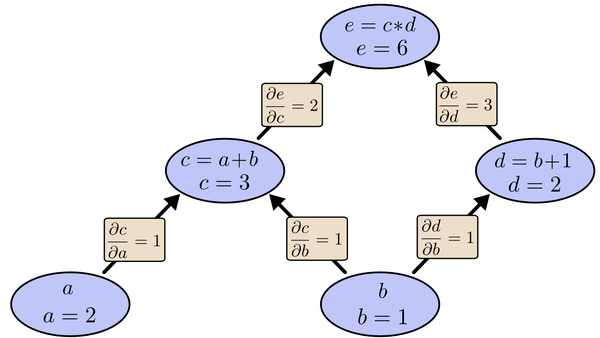
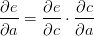 以及
以及 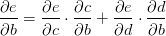
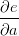 的值等于从a到e的路径上的偏导值的乘积,而
的值等于从a到e的路径上的偏导值的乘积,而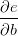 的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得
的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得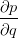 ,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到
,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到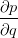 的值。
的值。大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
链接:https://zhuanlan.zhihu.com/p/21407711
来源:知乎
内容列表:
- 简介
- 简单表达式和理解梯度
- 复合表达式,链式法则,反向传播
- 直观理解反向传播
- 模块:Sigmoid例子
- 反向传播实践:分段计算
- 回传流中的模式
- 用户向量化操作的梯度
- 小结
简介
目标:本节将帮助读者对反向传播形成直观而专业的理解。反向传播是利用链式法则递归计算表达式的梯度的方法。理解反向传播过程及其精妙之处,对于理解、实现、设计和调试神经网络非常关键。
问题陈述:这节的核心问题是:给定函数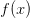 ,其中x是输入数据的向量,需要计算函数f关于x的梯度,也就是
,其中x是输入数据的向量,需要计算函数f关于x的梯度,也就是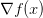 。
。
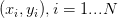 、权重W和偏差b。注意训练集是给定的(在机器学习中通常都是这样),而权重是可以控制的变量。因此,即使能用反向传播计算输入数据
、权重W和偏差b。注意训练集是给定的(在机器学习中通常都是这样),而权重是可以控制的变量。因此,即使能用反向传播计算输入数据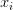 上的梯度,但在实践为了进行参数更新,通常也只计算参数(比如W,b)的梯度。然而
上的梯度,但在实践为了进行参数更新,通常也只计算参数(比如W,b)的梯度。然而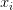 的梯度有时仍然是有用的:比如将神经网络所做的事情可视化便于直观理解的时候,就能用上。
的梯度有时仍然是有用的:比如将神经网络所做的事情可视化便于直观理解的时候,就能用上。简单表达式和理解梯度
从简单表达式入手可以为复杂表达式打好符号和规则基础。先考虑一个简单的二元乘法函数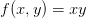 。对两个输入变量分别求偏导数还是很简单的:
。对两个输入变量分别求偏导数还是很简单的:
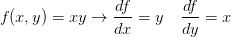
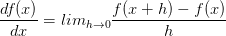
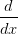 被应用于函数f,并返回一个不同的函数(导数)。对于上述公式,可以认为h值非常小,函数可以被一条直线近似,而导数就是这条直线的斜率。换句话说,每个变量的导数指明了整个表达式对于该变量的值的敏感程度。比如,若
被应用于函数f,并返回一个不同的函数(导数)。对于上述公式,可以认为h值非常小,函数可以被一条直线近似,而导数就是这条直线的斜率。换句话说,每个变量的导数指明了整个表达式对于该变量的值的敏感程度。比如,若 =4,y=-3,则
=4,y=-3,则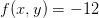 ,
, 的导数
的导数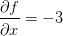 。这就说明如果将变量
。这就说明如果将变量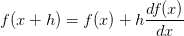 )。同样,因为
)。同样,因为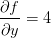 ,可以知道如果将y的值增加h,那么函数的输出也将增加(原因在于正号),且增加量是4h。
,可以知道如果将y的值增加h,那么函数的输出也将增加(原因在于正号),且增加量是4h。
【*】函数关于每个变量的导数指明了整个表达式对于该变量的敏感程度。
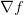 是偏导数的向量,所以有
是偏导数的向量,所以有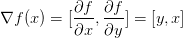 。即使是梯度实际上是一个向量,仍然通常使用类似“x上的梯度”的术语,而不是使用如“x的偏导数”的正确说法,原因是因为前者说起来简单。
。即使是梯度实际上是一个向量,仍然通常使用类似“x上的梯度”的术语,而不是使用如“x的偏导数”的正确说法,原因是因为前者说起来简单。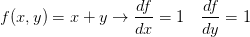
这就是说,无论其值如何,x,y的导数均为1。这是有道理的,因为无论增加中任一个的值,函数
的值都会增加,并且增加的变化率独立于
的具体值(情况和乘法操作不同)。取最大值操作也是常常使用的:
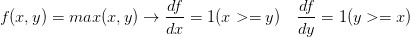
上式是说,如果该变量比另一个变量大,那么梯度是1,反之为0。例如,若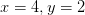 ,那么max是4,所以函数对于y就不敏感。也就是说,在
,那么max是4,所以函数对于y就不敏感。也就是说,在上增加
,函数还是输出为4,所以梯度是0:因为对于函数输出是没有效果的。当然,如果给
增加一个很大的量,比如大于2,那么函数
的值就变化了,但是导数并没有指明输入量有巨大变化情况对于函数的效果,他们只适用于输入量变化极小时的情况,因为定义已经指明:
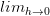 。
。
使用链式法则计算复合表达式
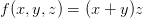 。虽然这个表达足够简单,可以直接微分,但是在此使用一种有助于读者直观理解反向传播的方法。将公式分成两部分:
。虽然这个表达足够简单,可以直接微分,但是在此使用一种有助于读者直观理解反向传播的方法。将公式分成两部分: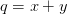 和
和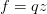 。在前面已经介绍过如何对这分开的两个公式进行计算,因为f是q和z相乘,所以
。在前面已经介绍过如何对这分开的两个公式进行计算,因为f是q和z相乘,所以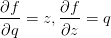 ,又因为q是x加y,所以
,又因为q是x加y,所以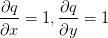 。然而,并不需要关心中间量
。然而,并不需要关心中间量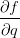 没有用。相反,函数f关于x,y,z的梯度才是需要关注的。链式法则指出将这些梯度表达式链接起来的正确方式是相乘,比如
没有用。相反,函数f关于x,y,z的梯度才是需要关注的。链式法则指出将这些梯度表达式链接起来的正确方式是相乘,比如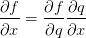 。在实际操作中,这只是简单地将两个梯度数值相乘,示例代码如下:
。在实际操作中,这只是简单地将两个梯度数值相乘,示例代码如下:
# 设置输入值
x = -2; y = 5; z = -4 # 进行前向传播
q = x + y # q becomes 3
f = q * z # f becomes -12 # 进行反向传播:
# 首先回传到 f = q * z
dfdz = q # df/dz = q, 所以关于z的梯度是3
dfdq = z # df/dq = z, 所以关于q的梯度是-4
# 现在回传到q = x + y
dfdx = 1.0 * dfdq # dq/dx = 1. 这里的乘法是因为链式法则
dfdy = 1.0 * dfdq # dq/dy = 1
最后得到变量的梯度[dfdx, dfdy, dfdz],它们告诉我们函数f对于变量[x, y, z]的敏感程度。这是一个最简单的反向传播。一般会使用一个更简洁的表达符号,这样就不用写df了。这就是说,用dq来代替dfdq,且总是假设梯度是关于最终输出的。
这次计算可以被可视化为如下计算线路图像:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------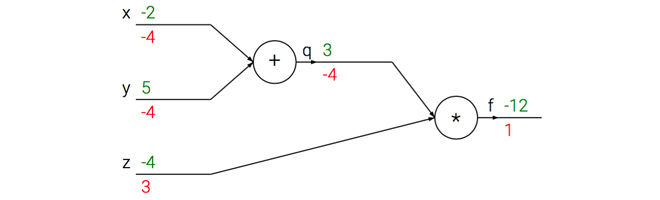
上图的真实值计算线路展示了计算的视觉化过程。前向传播从输入计算到输出(绿色),反向传播从尾部开始,根据链式法则递归地向前计算梯度(显示为红色),一直到网络的输入端。可以认为,梯度是从计算链路中回流。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
反向传播的直观理解
【*】这里对于每个输入的乘法操作是基于链式法则的。该操作让一个相对独立的门单元变成复杂计算线路中不可或缺的一部分,这个复杂计算线路可以是神经网络等。
因此,反向传播可以看做是门单元之间在通过梯度信号相互通信,只要让它们的输入沿着梯度方向变化,无论它们自己的输出值在何种程度上升或降低,都是为了让整个网络的输出值更高。
模块化:Sigmoid例子
上面介绍的门是相对随意的。任何可微分的函数都可以看做门。可以将多个门组合成一个门,也可以根据需要将一个函数分拆成多个门。现在看看一个表达式:
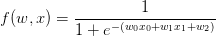
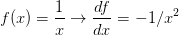
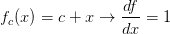
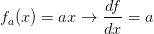
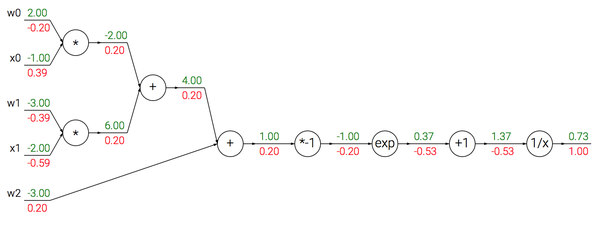
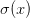 。sigmoid函数关于其输入的求导是可以简化的(使用了在分子上先加后减1的技巧):
。sigmoid函数关于其输入的求导是可以简化的(使用了在分子上先加后减1的技巧):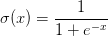
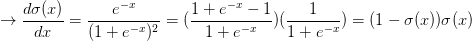
w = [2,-3,-3] # 假设一些随机数据和权重
x = [-1, -2] # 前向传播
dot = w[0]*x[0] + w[1]*x[1] + w[2]
f = 1.0 / (1 + math.exp(-dot)) # sigmoid函数 # 对神经元反向传播
ddot = (1 - f) * f # 点积变量的梯度, 使用sigmoid函数求导
dx = [w[0] * ddot, w[1] * ddot] # 回传到x
dw = [x[0] * ddot, x[1] * ddot, 1.0 * ddot] # 回传到w
# 完成!得到输入的梯度
实现提示:分段反向传播。上面的代码展示了在实际操作中,为了使反向传播过程更加简洁,把向前传播分成不同的阶段将是很有帮助的。比如我们创建了一个中间变量dot,它装着w和x的点乘结果。在反向传播的时,就可以(反向地)计算出装着w和x等的梯度的对应的变量(比如ddot,dx和dw)。
本节的要点就是展示反向传播的细节过程,以及前向传播过程中,哪些函数可以被组合成门,从而可以进行简化。知道表达式中哪部分的局部梯度计算比较简洁非常有用,这样他们可以“链”在一起,让代码量更少,效率更高。
反向传播实践:分段计算
看另一个例子。假设有如下函数:
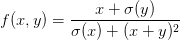
x = 3 # 例子数值
y = -4 # 前向传播
sigy = 1.0 / (1 + math.exp(-y)) # 分子中的sigmoi #(1)
num = x + sigy # 分子 #(2)
sigx = 1.0 / (1 + math.exp(-x)) # 分母中的sigmoid #(3)
xpy = x + y #(4)
xpysqr = xpy**2 #(5)
den = sigx + xpysqr # 分母 #(6)
invden = 1.0 / den #(7)
f = num * invden # 搞定! #(8)
# 回传 f = num * invden
dnum = invden # 分子的梯度 #(8)
dinvden = num #(8)
# 回传 invden = 1.0 / den
dden = (-1.0 / (den**2)) * dinvden #(7)
# 回传 den = sigx + xpysqr
dsigx = (1) * dden #(6)
dxpysqr = (1) * dden #(6)
# 回传 xpysqr = xpy**2
dxpy = (2 * xpy) * dxpysqr #(5)
# 回传 xpy = x + y
dx = (1) * dxpy #(4)
dy = (1) * dxpy #(4)
# 回传 sigx = 1.0 / (1 + math.exp(-x))
dx += ((1 - sigx) * sigx) * dsigx # Notice += !! See notes below #(3)
# 回传 num = x + sigy
dx += (1) * dnum #(2)
dsigy = (1) * dnum #(2)
# 回传 sigy = 1.0 / (1 + math.exp(-y))
dy += ((1 - sigy) * sigy) * dsigy #(1)
# 完成! 嗷~~
需要注意的一些东西:
对前向传播变量进行缓存:在计算反向传播时,前向传播过程中得到的一些中间变量非常有用。在实际操作中,最好代码实现对于这些中间变量的缓存,这样在反向传播的时候也能用上它们。如果这样做过于困难,也可以(但是浪费计算资源)重新计算它们。
在不同分支的梯度要相加:如果变量x,y在前向传播的表达式中出现多次,那么进行反向传播的时候就要非常小心,使用+=而不是=来累计这些变量的梯度(不然就会造成覆写)。这是遵循了在微积分中的多元链式法则,该法则指出如果变量在线路中分支走向不同的部分,那么梯度在回传的时候,就应该进行累加。
回传流中的模式
一个有趣的现象是在多数情况下,反向传播中的梯度可以被很直观地解释。例如神经网络中最常用的加法、乘法和取最大值这三个门单元,它们在反向传播过程中的行为都有非常简单的解释。先看下面这个例子:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
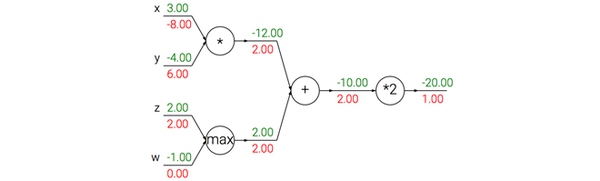
从上例可知:
加法门单元把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。这是因为加法操作的局部梯度都是简单的+1,所以所有输入的梯度实际上就等于输出的梯度,因为乘以1.0保持不变。上例中,加法门把梯度2.00不变且相等地路由给了两个输入。
取最大值门单元对梯度做路由。和加法门不同,取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。这是因为在取最大值门中,最高值的局部梯度是1.0,其余的是0。上例中,取最大值门将梯度2.00转给了z变量,因为z的值比w高,于是w的梯度保持为0。
乘法门单元相对不容易解释。它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。上例中,x的梯度是-4.00x2.00=-8.00。
非直观影响及其结果。注意一种比较特殊的情况,如果乘法门单元的其中一个输入非常小,而另一个输入非常大,那么乘法门的操作将会不是那么直观:它将会把大的梯度分配给小的输入,把小的梯度分配给大的输入。在线性分类器中,权重和输入是进行点积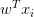 ,这说明输入数据的大小对于权重梯度的大小有影响。例如,在计算过程中对所有输入数据样本
,这说明输入数据的大小对于权重梯度的大小有影响。例如,在计算过程中对所有输入数据样本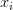 乘以1000,那么权重的梯度将会增大1000倍,这样就必须降低学习率来弥补。这就是为什么数据预处理关系重大,它即使只是有微小变化,也会产生巨大影响。对于梯度在计算线路中是如何流动的有一个直观的理解,可以帮助读者调试网络。
乘以1000,那么权重的梯度将会增大1000倍,这样就必须降低学习率来弥补。这就是为什么数据预处理关系重大,它即使只是有微小变化,也会产生巨大影响。对于梯度在计算线路中是如何流动的有一个直观的理解,可以帮助读者调试网络。
用向量化操作计算梯度
上述内容考虑的都是单个变量情况,但是所有概念都适用于矩阵和向量操作。然而,在操作的时候要注意关注维度和转置操作。
矩阵相乘的梯度:可能最有技巧的操作是矩阵相乘(也适用于矩阵和向量,向量和向量相乘)的乘法操作:
# 前向传播
W = np.random.randn(5, 10)
X = np.random.randn(10, 3)
D = W.dot(X) # 假设我们得到了D的梯度
dD = np.random.randn(*D.shape) # 和D一样的尺寸
dW = dD.dot(X.T) #.T就是对矩阵进行转置
dX = W.T.dot(dD)
提示:要分析维度!注意不需要去记忆dW和dX的表达,因为它们很容易通过维度推导出来。例如,权重的梯度dW的尺寸肯定和权重矩阵W的尺寸是一样的,而这又是由X和dD的矩阵乘法决定的(在上面的例子中X和W都是数字不是矩阵)。总有一个方式是能够让维度之间能够对的上的。例如,X的尺寸是[10x3],dD的尺寸是[5x3],如果你想要dW和W的尺寸是[5x10],那就要dD.dot(X.T)。
使用小而具体的例子:有些读者可能觉得向量化操作的梯度计算比较困难,建议是写出一个很小很明确的向量化例子,在纸上演算梯度,然后对其一般化,得到一个高效的向量化操作形式。
小结
对梯度的含义有了直观理解,知道了梯度是如何在网络中反向传播的,知道了它们是如何与网络的不同部分通信并控制其升高或者降低,并使得最终输出值更高的。
讨论了分段计算在反向传播的实现中的重要性。应该将函数分成不同的模块,这样计算局部梯度相对容易,然后基于链式法则将其“链”起来。重要的是,不需要把这些表达式写在纸上然后演算它的完整求导公式,因为实际上并不需要关于输入变量的梯度的数学公式。只需要将表达式分成不同的可以求导的模块(模块可以是矩阵向量的乘法操作,或者取最大值操作,或者加法操作等),然后在反向传播中一步一步地计算梯度。
在下节课中,将会开始定义神经网络,而反向传播使我们能高效计算神经网络各个节点关于损失函数的梯度。换句话说,我们现在已经准备好训练神经网络了,本课程最困难的部分已经过去了!ConvNets相比只是向前走了一小步。
BP(back propagation)反向传播的更多相关文章
- BP人工神经网络-反向传播法
0 网络计算结果 B(m)=f( ∑n( W(n,m)*X(n) ) + Θ(m) ) %中间层的输出 Y(k)=f( ∑m( V(m,k)*B(m) ) + ф(k) ) %输出层的输出 1 计算误 ...
- 再谈反向传播(Back Propagation)
此前写过一篇<BP算法基本原理推导----<机器学习>笔记>,但是感觉满纸公式,而且没有讲到BP算法的精妙之处,所以找了一些资料,加上自己的理解,再来谈一下BP.如有什么疏漏或 ...
- Backpropagation反向传播算法(BP算法)
1.Summary: Apply the chain rule to compute the gradient of the loss function with respect to the inp ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 前向传播算法(Forward propagation)与反向传播算法(Back propagation)
虽然学深度学习有一段时间了,但是对于一些算法的具体实现还是模糊不清,用了很久也不是很了解.因此特意先对深度学习中的相关基础概念做一下总结.先看看前向传播算法(Forward propagation)与 ...
- 吴恩达深度学习 反向传播(Back Propagation)公式推导技巧
由于之前看的深度学习的知识都比较零散,补一下吴老师的课程希望能对这块有一个比较完整的认识.课程分为5个部分(粗体部分为已经看过的): 神经网络和深度学习 改善深层神经网络:超参数调试.正则化以及优化 ...
- 人工神经网络反向传播算法(BP算法)证明推导
为了搞明白这个没少在网上搜,但是结果不尽人意,最后找到了一篇很好很详细的证明过程,摘抄整理为 latex 如下. (原文:https://blog.csdn.net/weixin_41718085/a ...
- 反向传播(Back Propagation)
反向传播(Back Propagation) 通常在设计好一个神经网络后,参数的数量可能会达到百万级别.而我们利用梯度下降去跟新参数的过程如(1).但是在计算百万级别的参数时,需要一种有效计算梯度的方 ...
- 反向传播(BP)算法
著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处.作者:刘皮皮链接:https://www.zhihu.com/question/24827633/answer/29120394来源 ...
随机推荐
- spring随手笔记2:初始化方法
1.init-method="init" public class HelloWorldServiceImpl implements HelloWorldService { pri ...
- input框限制只能输入正整数,逻辑与和或运算
推荐下自己刚写的项目,请大家指正:童话之翼 有时需要限制文本框输入内容的类型,本节分享下正则表达式限制文本框只能输入数字.小数点.英文字母.汉字等代码. 例如,输入大于0的正整数 代码如下: < ...
- numtoyminterval函数——数字转换函数
numtoyminterval函数——数字转换函数 ----转至51CTO 水滴的博客 语法:NUMTOYMINTERVAL ( n , 'char_expr' ) c ...
- 转: javascript实现全国城市三级联动菜单代码
<html> <head> <title>js全国城市三级联动菜单代码_B5教程网</title> <meta http-equiv=" ...
- iOS流量监控
http://code4app.com/snippets/one/iOS%E6%B5%81%E9%87%8F%E7%9B%91%E6%8E%A7/5020ba7a6803fae325000000 1. ...
- Google加强版权保护
在版权保护方面,我们一直是反面教材,而在场面上Google早已退出我们的世界,所以Google的加强版权保护对国内的互联网不会有太多的影响,即便无法在Google搜索到我们需要的XXX软件破解版,百度 ...
- Invalid byte 3 of 3-byte UTF-8 sequence
用maven编译,tomcat启动时报错:IOException parsing XML document from class path resource [applicationContext.x ...
- android studio 开启genymotion 出现"failed to create framebuffer image"
出现错误 Unable to start the virtul device To start virtual devices, make sure that your video card supp ...
- 数据交互 ajax 初始化省
1 //初始化省 2 function initProvince() { 3 if( areaLvel == 0 ) { 4 return; 5 } 6 // 清空option 7 $("# ...
- uoot启动过程
1.从我们的start_armboot开始讲起 u-boot整体由汇编段和C语言段外加连接脚本组成.关于汇编段请看我之前的博客<u-boot源码汇编段简要分析>,好,让我们进入start_ ...