python3编码(encode,decode)
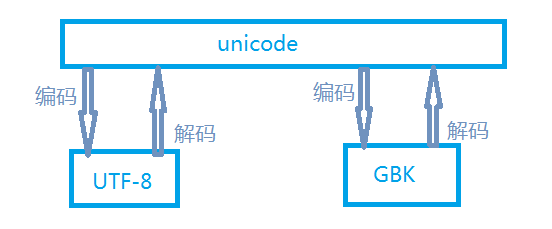
python3默认编码为unicode,由str类型进行表示。二进制数据使用byte类型表示。
字符串通过编码转换成字节码,字节码通过解码成为字符串
encode:str --> bytes
decode:bytes --> str
实例python 3.0+
str = "我是Python3"
str_utf8 = str.encode('utf-8')
str_gbk = str.encode('GBK') print(str) print("UTF-8 编码:", str_utf8)
print("GBK 编码:",str_gbk) print("UTF-8 解码:", str_utf8.decode('utf-8'))
print("GBK解码:",str_gbk.decode('GBK'))
输出结果如下:
我是Python3
UTF- 编码: b'\xe6\x88\x91\xe6\x98\xafPython3'
GBK 编码: b'\xce\xd2\xca\xc7Python3'
UTF- 解码: 我是Python3
GBK解码: 我是Python3
分析:
- python3默认的编码为unicode,utf-8可以看做是unicode的一个扩展集
- encode:指明要使用的编码,decode:指明当前编码的编码格式
#-*-coding:gb2312 -*- #这个也可以去掉 import sys
print(sys.getdefaultencoding()) msg = "我爱北京天安门"
#msg_gb2312 = msg.decode("utf-8").encode("gb2312")
msg_gb2312 = msg.encode("gb2312") #默认就是unicode,不用再decode,喜大普奔
gb2312_to_unicode = msg_gb2312.decode("gb2312")
gb2312_to_utf8 = msg_gb2312.decode("gb2312").encode("utf-8") print(msg)
print(msg_gb2312)
print(gb2312_to_unicode)
print(gb2312_to_utf8)
输出结果:
utf-
我爱北京天安门
b'\xce\xd2\xb0\xae\xb1\xb1\xbe\xa9\xcc\xec\xb0\xb2\xc3\xc5'
我爱北京天安门
b'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
python3编码(encode,decode)的更多相关文章
- is 和 == 区别,id() ,回顾编码,encode(),decode()
1. is 和 == 区别 id()函数 == 判断两边的值 is 判断内存地址例 s = "alex 是 大 xx"# abc = id(s) # 得到内存地址# print(a ...
- python编码encode decode(解惑)
关于python 字符串编码一直没有搞清楚,今天总结了一下. Python 字符串类型 Python有两种字符串类型:str 与 unicode. 字符串实例 # -*- coding: utf-8 ...
- 太白老师 day06 编码 encode decode
ASCII : 字母, 数字, 特殊字符 字符:1个字节 数字: 1个字节 Unicode: 万国码, 包含所有文字 创建之初 字符: 2个字节 中文: 2个字节 升级: 字符: 4个字节 中文 : ...
- python3.3 unicode(encode&decode)
最近在用python写多语言的一个插件时,涉及到python3.x中的unicode和编码操作,本文就是针对编码问题研究的汇总,目前已开源至github.以下内容来自项目中的README. 1 ASC ...
- python3的encode()和decode()
python3的encode()和decode() 在python3的内存中. 在程序运行阶段. 使⽤用的是unicode编码. 因为unicode是万国码. 什么内容都可以进行显示. 那么在数据传输 ...
- python编码encode和decode
计算机里面,编码方法有很多种,英文的一般用ascii,而中文有unicode,utf-8,gbk,utf-16等等. unicode是 utf-8,gbk,utf-16这些的父编码,这些子编码都能转换 ...
- pyhton字符编码问题--decode和encode方法
1 decode和encode方法 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成uni ...
- python编码问题之\"encode\"&\"decode\"
python encode decode 编码 decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换 ...
- Java如何进行Base64的编码(Encode)与解码(Decode)?
https://blog.csdn.net/zhou_kapenter/article/details/62890262 *************************************** ...
随机推荐
- bzoj3237 cdq分治+可撤销并查集
https://www.lydsy.com/JudgeOnline/problem.php?id=3237 年轻的花花一直觉得cdq分治只能用来降维,不料竟然可以用来分治询问 N<=100000 ...
- npmrc npm配置文件
一.全局 这个文件在全局会放在/users/${yourname}/.npmrc 里面最重要的是registry,npm的源 二.项目 项目里面如果和package.json同级存放了这个.npmrc ...
- tomcat插件使用
1.pom.xml添加插件 <build> <plugins> <!-- tomcat7插件 --> <!-- 注意:目前来说,maven中央仓库还没有tom ...
- 【MSSQL】SQL Server 设置用户只能查看并访问特定数据库
#背景 SQL Server实例上有多个服务商的数据库,每个数据库要由各自的服务商进行维护, 为了限定不同服务商商的维护人员只能访问自己的数据库,且不能看到其他服务商的数据库,现需要给各个服务商商限定 ...
- CentOS 安装最新版本 Git
查看默认 yum 源的 git版本 # 安装 yum install -y git # 查看版本 git version # git version 1.8.3.1 参看官网,CentOS 安装新版本 ...
- 解决composer出错的原因
1.执行了php -r "copy('https://install.phpcomposer.com/installer', 'composer-setup.php');" 2.出 ...
- shop++改造之ResponseEntity的坑
后台shop++购物车请求的数据是一个Map结构的数据,业务需要要在类似的购物车中加一个套餐. 那么套餐里面就包含商品信息了,觉得不用他的Map了于是封装了两个类: 套餐信息显示类,商品信息显示类 请 ...
- js拼接HTML页面元素a标签遇到的问题
业务,如下图需要做一个广告轮播的图片链接 使用了ajax请求后台,在js拼接html,关键代码: $("#scroll_img").html(""); for ...
- 使用List和Map遇到得空指针异常
如题,经常遇到同类得问题,因为集合在使用之前必须先new一个对象. private List<Orderdatil> orderdatilList=new ArrayList<Ord ...
- UVA - 1401 | LA 3942 - Remember the Word(dp+trie)
https://vjudge.net/problem/UVA-1401 题意 给出S个不同的单词作为字典,还有一个长度最长为3e5的字符串.求有多少种方案可以把这个字符串分解为字典中的单词. 分析 首 ...