JDBC-DbUtils
依赖
pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion> <groupId>yofc</groupId>
<artifactId>jdbc</artifactId>
<version>1.0-SNAPSHOT</version> <dependencies>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter-api</artifactId>
<version>5.4.0</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.14</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-nop</artifactId>
<version>1.7.26</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>commons-dbutils</groupId>
<artifactId>commons-dbutils</artifactId>
<version>1.7</version>
</dependency>
</dependencies> <build>
<plugins>
<!-- 指定jdk -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>
实体类
package com.jdbc;
public class User {
private Integer id;
private String name;
private Integer age;
public User(Integer id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public User() {}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}
CURD
INSERT, UPDATE 和 DELETE
import com.alibaba.druid.pool.DruidDataSource;
import com.jdbc.User;
import org.apache.commons.dbutils.QueryLoader;
import org.apache.commons.dbutils.QueryRunner;
import org.apache.commons.dbutils.ResultSetHandler;
import org.apache.commons.dbutils.handlers.*;
import org.junit.jupiter.api.AfterEach;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test; import java.io.IOException;
import java.sql.Connection;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map; public class DBUtilsTest { private Connection connection; @BeforeEach
public void start() throws Exception {
DruidDataSource dataSource = new DruidDataSource();
dataSource.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://192.168.8.136:3306/jdbc");
dataSource.setUsername("root");
dataSource.setPassword("root"); connection = dataSource.getConnection();
} @AfterEach
public void end() throws Exception {
if (connection != null) {
connection.close();
}
} /**
* QueryRunner 类的 update 方法可用于 INSERT, UPDATE 和 DELETE
*/
@Test
public void testQueryRunnerUpdate() {
QueryRunner queryRunner = new QueryRunner();
String sql = "UPDATE user SET name = ? WHERE id = ?";
try {
queryRunner.update(connection, sql, "zhangsan",22);
} catch (Exception e) {
e.printStackTrace();
}
}
}
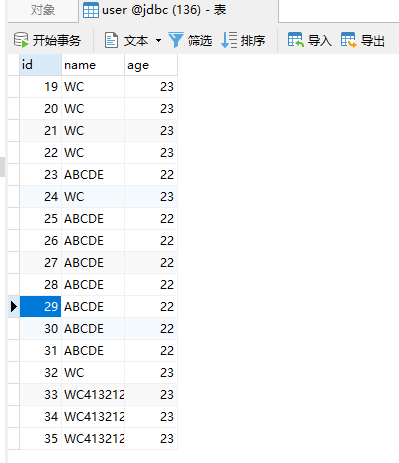
SELECT
@Test
public void testResultSetHandler() {
String sql = "SELECT id, name, age FROM user";
QueryRunner queryRunner = new QueryRunner();
try {
/**
* ResultSetHandler : query 方法的返回值直接取决于 ResultSetHandler 的 hanlde(ResultSet rs) 是如何实现
* QueryRunner 类的 query 方法中调用了 ResultSetHandler 的 handle() 方法作为返回值
*/
List<User> usersRST = queryRunner.query(connection, sql,
new ResultSetHandler<List<User>>() {
@Override
public List<User> handle(ResultSet rs) throws SQLException {
List<User> users = new ArrayList<>();
while (rs.next()) {
Integer id = rs.getInt(1);
String name = rs.getString(2);
Integer age = rs.getInt(3);
User user = new User(id, name, age);
users.add(user);
}
return users;
}
}
);
System.out.println(usersRST);
} catch (Exception e) {
e.printStackTrace();
}
}

SELECT-BeanHandler
/**
* BeanHandler: 把结果集的第一条记录转为创建 BeanHandler 对象时传入的 Class 参数对应的对象
*/
@Test
public void testBeanHanlder(){
try {
QueryRunner queryRunner = new QueryRunner();
String sql = "SELECT id, name, age FROM user WHERE id >= ?";
User user = (User) queryRunner.query(connection, sql, new BeanHandler(User.class), 5);
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
}
}
SELECT-BeanListHandler
/**
* BeanListHandler:ResultSetHandler 的实现类,把结果集转为一个 List, 该 List 不为 null, 无记录时为空集合
* 有记录, List 中存放创建 BeanListHandler 传入的 Class 对象对应的对象
*/
@Test
public void testBeanListHandler() {
String sql = "SELECT id, name, age FROM user";
QueryRunner queryRunner = new QueryRunner();
try {
Object object = queryRunner.query(connection, sql, new BeanListHandler<>(User.class));
System.out.println(object);
} catch (Exception e) {
e.printStackTrace();
}
}

SELECT-MapHandler
/**
* MapHandler: 返回 SQL 对应的第一条记录对应的 Map 对象
* 键: SQL 查询的列名(不是列的别名), 值: 列的值
*/
@Test
public void testMapHandler() {
QueryRunner queryRunner = new QueryRunner();
String sql = "SELECT id, name, age FROM user Where id > ?";
try {
Map<String, Object> map = queryRunner.query(connection, sql, new MapHandler(), 4);
System.out.println(map);
} catch (Exception e) {
e.printStackTrace();
}
}

SELECT-MapListHandler
/**
* Map 对应查询的一条记录: 键: SQL 查询的列名(不是列的别名), 值: 列的值
* MapListHandler: 返回的多条记录对应的 Map 的集合
*/
@Test
public void testMapListHandler() {
QueryRunner queryRunner = new QueryRunner();
String sql = "SELECT id, name, age FROM user";
try {
List<Map<String, Object>> mapList = queryRunner.query(connection, sql, new MapListHandler());
System.out.println(mapList);
} catch (Exception e) {
e.printStackTrace();
}
}

SELECT-ScalarHandler
/**
* ScalarHandler: 把结果集的第一行第一列转为一个数值(可以是任意基本数据类型)返回
*/
@Test
public void testScalarHandler() {
QueryRunner queryRunner = new QueryRunner();
String sql = "SELECT id, name, age FROM user WHERE id > ?";
try {
Object count = queryRunner.query(connection, sql, new ScalarHandler(), 6);
System.out.println(count);
} catch (Exception e) {
e.printStackTrace();
}
}
QueryLoader
sql.properties
QUERY_USER=SELECT id, name, age FROM user
/**
* QueryLoader: 加载存放着 SQL 语句的资源文件,以更好的解耦
* / 代表类路径的根目录
*/
@Test
public void testQueryLoader() throws IOException {
Map<String, String> sqls = QueryLoader.instance().load("/sql.properties");
String updateSql = sqls.get("QUERY_USER");
System.out.println(updateSql);
}
官方文档
JDBC-DbUtils的更多相关文章
- 【JDBC&Dbutils】JDBC&JDBC连接池&DBUtils使用方法(重要)
-----------------------JDBC---------- 0. db.properties文件 driver=com.mysql.jdbc.Driver url=jdbc: ...
- 使用JDBC(Dbutils工具包)来从数据库拿取map类型数据来动态生成insert语句
前言: 大家在使用JDBC来连接数据库时,我们通过Dbutils工具来拿取数据库中的数据,可以使用new BeanListHandler<>(所映射的实体类.class),这样得到的数据, ...
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包含增删改查、JavaBean反射原理,附源码)
最近看老罗的视频,跟着完成了利用Java操作MySql数据库的一个框架类JdbcUtils.java,完成对数据库的增删改查.其中查询这块,包括普通的查询和利用反射完成的查询,主要包括以下几个函数接口 ...
- jdbc操作mysql
本文讲述2点: 一. jdbc 操作 MySQL .(封装一个JdbcUtils.java类,实现数据库表的增删改查) 1. 建立数据库连接 Class.forName(DRIVER); connec ...
- 利用Java针对MySql封装的jdbc框架类 JdbcUtils 完整实现(包括增删改查、JavaBean反射原理,附源代码)
近期看老罗的视频,跟着完毕了利用Java操作MySql数据库的一个框架类JdbcUtils.java,完毕对数据库的增删改查.当中查询这块,包含普通的查询和利用反射完毕的查询,主要包含以下几个函数接口 ...
- Android 之JDBC
JDBC(Java DataBase Connectivity)是使用 Java 存取数据库系统的标准解决方案,它将不同数据库间各自差异API与标准 SQL语句分开看待,实现数据库无关的 Java操作 ...
- 厚积薄发系列之JDBC详解
创建一个以JDBC链接数据库的程序,包含七个步骤 1.加载JDBC驱动 加载要连接的数据库的驱动到JVM 如何加载?forName(数据库驱动) MySQL:Class.forName("c ...
- JdbcUtils.java
package com.jdbc.dbutils; import java.lang.reflect.Field; import java.sql.Connection; import java.sq ...
- 32、mybatis
第一章回顾jdbc开发 1)优点:简单易学,上手快,非常灵活构建SQL,效率高 2)缺点:代码繁琐,难以写出高质量的代码(例如:资源的释放,SQL注入安全性等) 开发者既要写业务逻辑,又要写对象的创建 ...
- mybaits入门
1.回顾jdbc开发 orm概述 orm是一种解决持久层对象关系映射的规则,而不是一种具体技术.jdbc/dbutils/springdao,hibernate/springorm,mybaits同属 ...
随机推荐
- C# Timer 的区别
首先,我们看一下 3种Timer 1.System.Threading.Timer 2.System.Timers.Timer 3.System.Windows.Forms.Timer 主要区别,其实 ...
- 数据库 -- mysql支持的数据类型
mysql支持的数据类型 数值类型 MySQL支持所有标准SQL数值数据类型. 这些类型包括严格数值数据类型(INTEGER.SMALLINT.DECIMAL和NUMERIC),以及近似数值数据类型( ...
- Python中xlrd模块解析
xlrd 导入模块 import xlrd 2.打开指定的excel文件,返回一个data对象 data = xlrd.open_workbook(file) ...
- WIN8.1下Prolific USB-to-Serial Comm Port驱动黄色感叹号问题
文章解决来源:http://blog.csdn.net/gsj0791/article/details/17664861 在做fpga口的uart回环测试时候,由于开发板上的是usb转uart,所以需 ...
- 【XSY1262】【GDSOI2015】循环排插 斯特林数
题目描述 有一个\(n\)个元素的随机置换\(P\),求\(P\)分解出的轮换个数的\(m\)次方的期望\(\times n!\) \(n\leq 100000,m\leq 30\) 题解 解法一 有 ...
- 【XSY1476】平凡之路 斜率优化DP
题目大意 有\(n\)个格子,一开始你在\(1\)号格子.每次你只能往编号更大的格子走.从第\(i\)个格子走到第\(j\)个格子的代价是\(a_i+a_j\times(j-i)\times m\) ...
- hdu 2159 FATE (二维完全背包)
链接:http://acm.hdu.edu.cn/showproblem.php?pid=2159 思路: dp[j][k] 代表消耗耐久度j,干掉k个敌人获得的经验值. 状态转移方程为: dp[j] ...
- 自学华为IoT物联网_09 OceanConnect业务流程
点击返回自学华为IoT物流网 自学华为IoT物联网_09 OceanConnect业务流程 1. 物流网重要的连个协议介绍 1.1 重要物联网协议介绍----MQTT MQTT(消息队列遥测传输) ...
- Ubuntu18.04搜狗输入法最新版本2.2.0.0108经常乱码的解决方案
图示 解决 旧版 可以安装旧版(我只在新版sogoupinyin_2.2.0.0108_amd64才遇到这个问题) 旧版安装指南:http://www.cnblogs.com/dunitian/p/6 ...
- Python By 360、小米
小米 乱谈Python并发 说实话,我一直觉得PHP真的是最好的语言,不仅养活了一大批PHP程序员,同时还为安全人员提供了大量的就业机会.然而,令人唏嘘的是,安全界很多人其实是吃着Python的饭,操 ...