Pytorch 初识
import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as plt #这个一直想学,还没学,代码从莫烦python那copy的
import torchvision
import torchvision.transforms as transforms
import numpy as np
很遗憾,看了半天还是没怎么学会,只能先记录俩个例子放在这里了。然后Pytorch就先告一段落吧。
一个简单的回归网络的例子
这个例子是对莫烦python那例子的一个修改(主要是自己玩了下,懒得弄回去了)
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) # x data (tensor), shape=(100, 1)
y = 4 * x ** 3 + x ** 2 + 3 * x + 0.2*torch.rand(x.size())
class Net(torch.nn.Module): # 继承 torch 的 Module
def __init__(self):
super(Net, self).__init__() # 继承 __init__ 功能
# 定义每层用什么样的形式
self.hidden = nn.Linear(1, 7) # 隐藏层线性输出
#self.hidden2 = torch.nn.Linear(3, 7)
self.predict = nn.Linear(7, 1) # 输出层线性输出
self.active = nn.Tanh() # 这里的激活函数玩得挺多的,带ReLU的一般效果都不错,还有Softshrink 有正有负效果也很好啊
def forward(self, x): # 这同时也是 Module 中的 forward 功能
# 正向传播输入值, 神经网络分析出输出值
x = self.active(self.hidden(x)) # 激励函数(隐藏层的线性值)
#x = self.active(self.hidden2(x))
x = self.predict(x) # 输出值
return x
net = Net()
plt.ion() # 画图
plt.show()
optimizer = torch.optim.SGD(net.parameters(), lr=0.1, momentum=0.9) # 传入 net 的所有参数, 学习率
loss_func = nn.MSELoss()
for t in range(100):
prediction = net(x) # 喂给 net 训练数据 x, 输出预测值
loss = loss_func(prediction, y) # 计算两者的误差
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 接着上面来
if t % 20 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)
有很多很有趣的现象,主要就是跟参数有关的东西:
self.hidden = nn.Linear(1, 100)
self.predict = nn.Linear(100, 1)
可能会出现下面的情况:

增加一个隐藏层也往往会这样。这个就是所谓的梯度爆炸?这类名字我也只是听过,到时候再深入吧,在此记一笔。
Tanh() 改为 Softshrink 就没问题了(因为Softshrink有正有负所以会有所抵消?)
再者:
x = torch.unsqueeze(torch.linspace(-1, 1, 100), dim=1) * 3
一样会炸,所以要很小心才行啊(对了,调小学习率可以应付这种情况)。
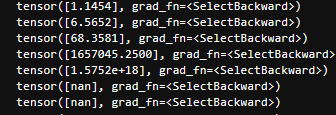
没一会功夫,最大参数的值就突破天际了。
再来一个例子
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(3, 7)
#self.fc2 = nn.Linear(7, 5)
self.fc3 = nn.Linear(7, 1)
self.active = nn.ReLU()
def forward(self, x):
x = self.active(self.fc1(x))
#x = self.active(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
print(net)
# y = x1 ** 3 + x2 ** 2 + x3 + e
x = torch.rand(100, 3)
y = x[:,0] ** 3 + x[:,1] ** 2 + x[:, 2] + torch.randn(100) * 0.05
optimizer = torch.optim.SGD(net.parameters(), lr=0.005, momentum = 0.9)
loss_func = nn.MSELoss()
for t in range(200):
pre = net(x)
loss = loss_func(pre, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
#print('step: {0} | loss: {1}'.format(t, loss))
#结果很遗憾,最后都会趋于一个值,咋搞,弄不明白啊。
官方教程上图片识别的例子
图片是 3×32×323 \times 32 \times 323×32×32的
transform = transforms.Compose( #转换格式
[transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, #训练样本
download=False, transform=transform) #我下好了所以是False
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,
shuffle=True, num_workers=0) #num_workers 好像是线程进程的处理,但是我用了这个会崩,就改成0 shuffle 打扰顺序, batch_size,一个数据分成几堆,批训练。
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4,
shuffle=False, num_workers=0)
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
dataiter = iter(trainloader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images))
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5) # (3,6,5) in_channel:3,out_channel:6,kernel_size:5 * 5
#说人话就是,输入的图片是3个通道的(RGB),卷积后的图片是6个通道的,就是6层的矩阵
self.pool = nn.MaxPool2d(2, 2) #池化
self.conv2 = nn.Conv2d(6, 16, 5) #卷积
self.fc1 = nn.Linear(16 * 5 * 5, 120) #全连接层
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) #图片大小转换:(3,32,32)->(6,28,28)->(6,14,14)
x = self.pool(F.relu(self.conv2(x))) #图片大小转换: (6,14,14)->(16,10,10)->(16,5,5)
x = x.view(-1, 16 * 5 * 5) #这玩意儿是用来排列图像的 (16,5,5)是从上面得到的
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
net = Net()
criterion = nn.CrossEntropyLoss() #交叉熵
optimizer = torch.optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
for epoch in range(2): # loop over the dataset multiple times 整体数据走2遍
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
# get the inputs
inputs, labels = data
# zero the parameter gradients
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
if i % 2000 == 1999: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 2000))
running_loss = 0.0
print('Finished Training')
#测试数据
dataiter = iter(testloader)
images, labels = dataiter.next()
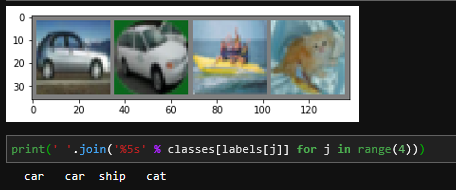
imshow(torchvision.utils.make_grid(images))
print('GroundTruth: ', ' '.join('%5s' % classes[labels[j]] for j in range(4)))
outputs = net(images)
_, predicted = torch.max(outputs, 1)
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(4)))

Pytorch 初识的更多相关文章
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 # Author : Hellcat # Time : 2018/2/11 import torch as t import t ...
- 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上
总结一下相关概念: torch.Tensor - 一个近似多维数组的数据结构 autograd.Variable - 改变Tensor并且记录下来操作的历史记录.和Tensor拥有相同的API,以及b ...
- Pytorch笔记 (2) 初识Pytorch
一.人工神经网络库 Pytorch ———— 让计算机 确定神经网络的结构 + 实现人工神经元 + 搭建人工神经网络 + 选择合适的权重 (1)确定人工神经网络的 结构: 只需要告诉Pytorc ...
- PyTorch学习笔记之初识word_embedding
import torch import torch.nn as nn from torch.autograd import Variable word2id = {'hello': 0, 'world ...
- 『PyTorch』第十二弹_nn.Module和nn.functional
大部分nn中的层class都有nn.function对应,其区别是: nn.Module实现的layer是由class Layer(nn.Module)定义的特殊类,会自动提取可学习参数nn.Para ...
- 『PyTorch』第九弹_前馈网络简化写法
『PyTorch』第四弹_通过LeNet初识pytorch神经网络_上 『PyTorch』第四弹_通过LeNet初识pytorch神经网络_下 在前面的例子中,基本上都是将每一层的输出直接作为下一层的 ...
- TensorFlow学习(1)-初识
初识TensorFlow 一.术语潜知 深度学习:深度学习(deep learning)是机器学习的分支,是一种试图使用包含复杂结构或由多重非线性变换构成的多个处理层对数据进行高层抽象的算法. 深度学 ...
- Android动画效果之初识Property Animation(属性动画)
前言: 前面两篇介绍了Android的Tween Animation(补间动画) Android动画效果之Tween Animation(补间动画).Frame Animation(逐帧动画)Andr ...
- 初识Hadoop
第一部分: 初识Hadoop 一. 谁说大象不能跳舞 业务数据越来越多,用关系型数据库来存储和处理数据越来越感觉吃力,一个查询或者一个导出,要执行很长 ...
随机推荐
- [20180819]关于父子游标问题(11g).txt
[20180819]关于父子游标问题(11g).txt --//sql语句存在父子游标,子游标堆6在父游标堆0里面.--//如果存在许多子游标的情况下,父游标堆0是否大小是发生变化呢.测试看看.--/ ...
- C#-循环语句(六)
for循环 格式: for(表达式1;循环条件;表达式2) { 循环体; } 解释:先执行表达式1,再判断循环条件是否为真,如果为真则执行循环体,执行完成后再执行表达式2 再次判断循环条件,由此一直反 ...
- 使用SQL Developer生成Oracle数据库的关系模型(ER图)
客户要一张数据库的关系模型图,于是用SQL Developer来做. 一.SQL Developer版本 我在官网下载的最新版本(现在已经到了18.1,Oracle更新的太勤快): 2.如下图所示选择 ...
- Python数据类型转换函数
数据类型转换函数 函 数 作 用 int(x) 将 x 转换成整数类型 float(x) 将 x 转换成浮点数类型 complex(real[,imag]) 创建一个复数 str(x) 将 x 转换为 ...
- Centos7安装搭建FTP服务器(最简便方法)
简介: vsftpd 是“very secure FTP daemon”的缩写,安全性是它的一个最大的特点. vsftpd 是一个 UNIX 类操作系统上运行的服务器的名字,它可以运行在诸如 Linu ...
- centos7 下安装Apache2+MariaDB+PHP5过程详解
1.启用Apache2 Centos7默认已经安装httpd服务,只是没有启动.如果你需要全新安装,可以 yum install -y httpd 启动服务:systemctl start httpd ...
- Linux补充
1.从国内豆瓣源安装软件 pip install -i https://pypi.doubanio.com/simple paramiko --trusted-host pypi.douban.com
- 我的游戏学习日志3——三国志GBA
我的游戏学习日志3——三国志GBA 三国志GBA由日本光荣公司1991~1995所推出<三国志>系列游戏,该作是光荣在GBA上推出的<三国志>系列作品的第一款.本游戏登场武将总 ...
- 详解 JSONP跨域请求的实现
跨域问题是由于浏览器为了防止CSRF攻击(Cross-site request forgery跨站请求伪造),避免恶意攻击而带来的风险而采取的同源策略限制.当一个页面中使用XMLHTTPR ...
- 从 0 → 1,学习Linux该这么开始!
首先我们还是来普及以下概念,讲点虚的.现在是图形系统的天下,windows我们用了20多年.成功归功与它图形界面,你会点鼠标吗你会敲键盘吗?所以你会上网会聊天会玩游戏了.那么,0基础接触的Linux, ...