Hive简单编程实践-词频统计
一、使用MapReduce的方式进行词频统计
(1)在HDFS用户目录下创建input文件夹
hdfs dfs -mkdir input
注意:林子雨老师的博客(http://dblab.xmu.edu.cn/blog/1080-2/)中是在hadoop目录下创建input文件,而MapReduce读取的是HDFS目录中的文件,因此笔者认为该博客存在错误。
(2)在hadopp根目录中创建两个测试文件file1.txt和file2.txt,并将他们拷贝到HDFS中的input目录下
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt
hdfs dfs -put file1.txt file2.txt input/
知识点延伸:
echo " hello world" > file1.txt # 表示创建file1.txt
echo "nihao" >> file1.txt # 表示往file1.txt里追加内容
echo "" > file1.txt # 表示清空file1.txt里的内容,但是文件中还存在空字符串
echo -n > file1.txt # 清除文件的所有内容,包括空字符串
参考:https://linux.cn/article-8024-1.html
(3)调用MapReduce程序对input文件夹中的文件进行词频统计
cd /usr/local/hadoop #切换到hadoop目录下
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.6.jar wordcount input output
注意:虽然输入目录是在hadoop目录下,但是自动生成的输出目录是在HDFS目录下的,如果HDFS目录下已存在output文件夹,就需要先删除,否则会出现下图所示的错误:

(4)执行结果

二、使用Hive完成词频统计(7行代码搞定)
1.编写Hql代码
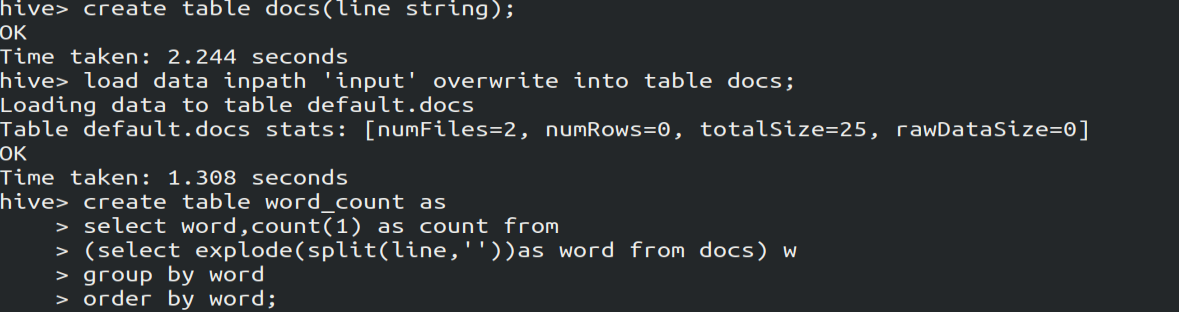
create table docs(line string); # 创建docs表并注明表里的数据类型是String
load data inpath 'input' overwrite into table docs; # 向表中装载数据
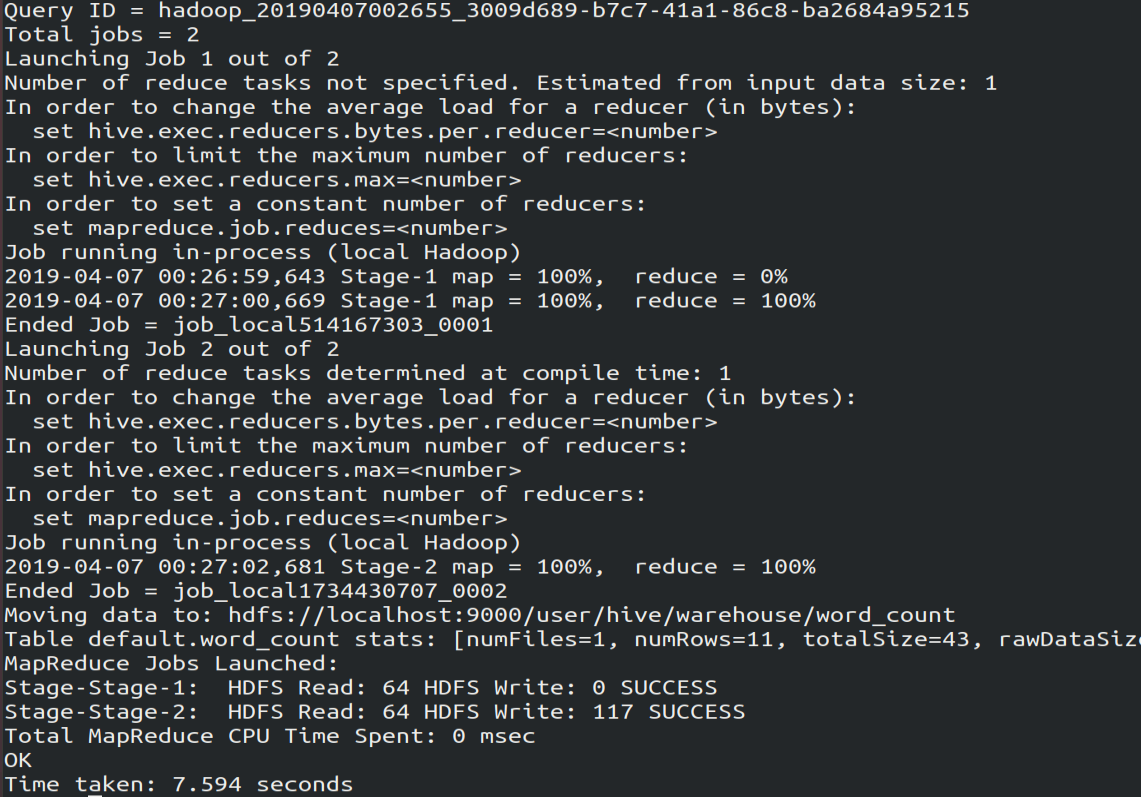
create table word_count as # 创建word_count表,将数据保存到该表
select word, count() as count from
(select explode(split(line,' '))as word from docs) w
group by word
order by word;
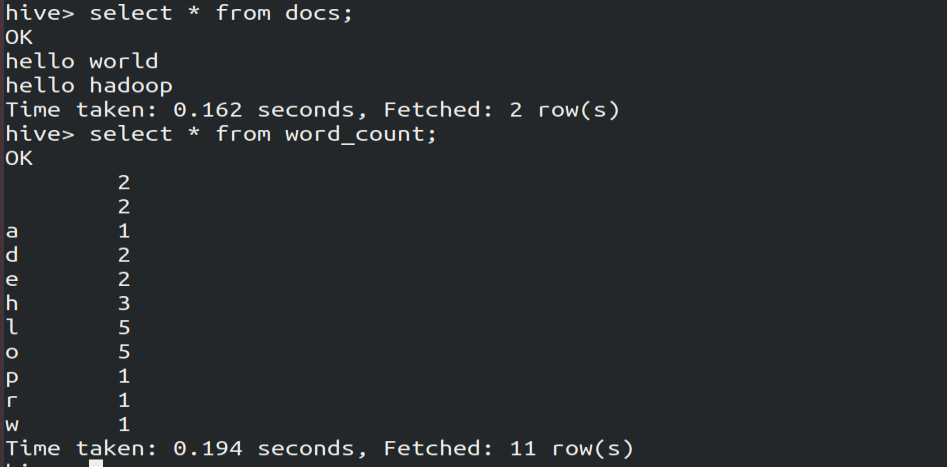
2.查询执行结果
select * from word_count
Hive简单编程实践-词频统计的更多相关文章
- MapReduce编程:词频统计
首先在项目的src文件中需要加入以下文件,log4j的内容为: log4j.rootLogger=INFO, stdout log4j.appender.stdout=org.apache.log4j ...
- java - Socket简单编程实践
1.简介: 1)SOCKET是应用程序和网络之间的一个接口.SOCKET创建设置好以后,应用程序可以: 通过网络把数据发送到socket . 通过网络从socket接收数据.(通信的前提是应用程序知道 ...
- Hadoop上的中文分词与词频统计实践 (有待学习 http://www.cnblogs.com/jiejue/archive/2012/12/16/2820788.html)
解决问题的方案 Hadoop上的中文分词与词频统计实践 首先来推荐相关材料:http://xiaoxia.org/2011/12/18/map-reduce-program-of-rmm-word-c ...
- hive进行词频统计
统计文件信息: $ /opt/cdh-5.3.6/hadoop-2.5.0/bin/hdfs dfs -text /user/hadoop/wordcount/input/wc.input hadoo ...
- sqoop进行将Hive 词频统计的结果数据传输到Mysql中
使用sqoop进行将Hive 词频统计的结果数据传输到Mysql中. mysql准备接受数据的数据库与表 hive准备待传输的数据 sqoop进行数据传输 mysql查看传输结果 二:电子书 ...
- [Java 并发] Java并发编程实践 思维导图 - 第一章 简单介绍
阅读<Java并发编程实践>一书后整理的思维导图.
- hive学习01词频统计
词频统计 #创建表,只有一列,列名line create table word_count ( line string) row format delimited fields terminated ...
- 利用python实现简单词频统计、构建词云
1.利用jieba分词,排除停用词stopword之后,对文章中的词进行词频统计,并用matplotlib进行直方图展示 # coding: utf-8 import codecs import ma ...
- Storm实时计算:流操作入门编程实践
转自:http://shiyanjun.cn/archives/977.html Storm实时计算:流操作入门编程实践 Storm是一个分布式是实时计算系统,它设计了一种对流和计算的抽象,概念比 ...
随机推荐
- [Hive_add_3] Hive 进行简单数据处理
0. 说明 通过 Hive 对 duowan 数据进行简单处理 1. 操作流程 1.1 建表 create table duowan(id int, name string, pass string, ...
- Debian9安装vim和vim无法右键鼠标粘贴解决方法
问题描述: Debian9有时候安装的时候没有vim,在centos用习惯了vim 1.Debian安装vim: root@kvm1:/etc/network# apt-get install vim ...
- 【Teradata】 TPT基础知识
1.TPT Description Teradata Parallel Transporter (TPT) is client software that performs data extract ...
- 前端性能优化成神之路-HTTP压缩开启gzip
什么是HTTP压缩 HTTP压缩是指: Web服务器和浏览器之间压缩传输的”文本内容“的方法. HTTP采用通用的压缩算法,比如gzip来压缩HTML,Javascript, CSS文件. 能大大减少 ...
- PHP 缓存技术(一)
移除光盘
- zabbix图形乱码问题解决办法
zabbix中的图形乱码的问题解决办法: 1.下载字体,例如:simkai.ttf楷体(注:在windows中的字体格式可能是TTC的,所以去网上下载一个ttf的字体) 2.上传到linux中(我使用 ...
- geth工作运行程序转后台
今天查看了一下运行程序怎么转后台,然后就发现了之前写的脚本一定要进行console控制台然后在解锁coinbase,然后才手动挖矿的操作真的是太笨了,后面研究了一下,发现是可以在运行语句上进行操作的: ...
- 初学Python——文件操作第二篇
前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求.下面来一一分析. 一.Python文件操作的特点 首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作? 字符(串 ...
- python:HTMLTestRunner测试报告优化
之前的博客有介绍过python的单元测试框架unittest,基于其扩展的测试报告模块HTMLTestRunner,不过这个报告本身的界面看起来太丑... 趁着今天有时间,找了两个二次开发优化后的HT ...
- vue引入css的两种方式
方案1.在main.js中引入方式 import '@/assets/css/reset.css' 方案2.在.vue文件的<style/>标签里面引入 @import &qu ...