YARN集群的mapreduce测试(四)
将手机用户使用流量的数据进行分组,排序;
测试准备:
首先同步时间,然后master先开启hdfs集群,再开启yarn集群;用jps查看:
master上: 先有NameNode、SecondaryNameNode;再有ResourceManager;
slave上: 先有DataNode;再有NodeManager;
如果master启动hdfs和yarn成功,但是slave节点有的不成功,则可以使用如下命令手动启动:
| hadoop-daemon.sh start datanode |
| yarn-daemon.sh start nodemanager |
然后在本地"/home/hadoop/test/"目录创建phoneflow文件夹,将所有需要统计的数据放到该文件夹下;
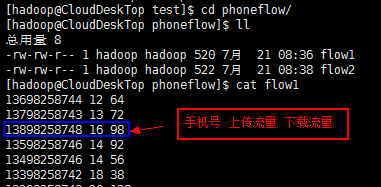
测试目标:
目标一:输出结果是:按手机号分组后,按照上传流量和下载流量的总和排序的结果;
目标二:输出结果是:按手机号分组后,先按照上传流量排序,遇到相同时再按照上传流量和下载流量的总和排序;
测试代码:
目标一:
因为涉及到了排序,我们输出的结果是一个包装好的flow对象(它自身就包含了很多信息);
分组必须必须要让flow类实现Serializable接口;
排序就必须要让flow类在分组的基础上再实现WritableComparable接口,并且重写write、readFields方法和重写compareTo方法;
package com.mmzs.bigdata.yarn.mapreduce; import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.io.Serializable; import org.apache.hadoop.io.WritableComparable; public class Flow implements WritableComparable<Flow>,Serializable{ private String phoneNum;//手机号
private Long upFlow; //上传流量
private Long downFlow; //下载流量
public Flow() {}
public Flow(String phoneNum, Long upFlow, Long downFlow) {
super();
this.phoneNum = phoneNum;
this.upFlow = upFlow;
this.downFlow = downFlow;
}
public Long getTotalFlow() {
return upFlow+downFlow;
} //按照怎样的顺序写入到reduce中,在reduce中就按照怎样的顺序读
//write是一个序列化的过程
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNum);
out.writeLong(upFlow);
out.writeLong(downFlow);
}
//read是一个反序列化的过程
@Override
public void readFields(DataInput in) throws IOException {
this.phoneNum = in.readUTF();
this.upFlow = in.readLong();
this.downFlow = in.readLong();
}
//reduce任务排序的依据
@Override
public int compareTo(Flow flow) {
Long curTotalFlow = this.getTotalFlow();
Long paramTotalFlow = flow.getTotalFlow();
Long resFlow = curTotalFlow-paramTotalFlow;
return resFlow>0?-1:1;
} public String getPhoneNum() {
return phoneNum;
}
public void setPhoneNum(String phoneNum) {
this.phoneNum = phoneNum;
}
public Long getUpFlow() {
return upFlow;
}
public void setUpFlow(Long upFlow) {
this.upFlow = upFlow;
}
public Long getDownFlow() {
return downFlow;
}
public void setDownFlow(Long downFlow) {
this.downFlow = downFlow;
}
//此方法只是单纯的为了方便一次性设置值,只set一次
public void setFlow(String phoneNum, Long upFlow, Long downFlow) {
this.phoneNum = phoneNum;
this.upFlow = upFlow;
this.downFlow = downFlow;
}
@Override
public String toString() {
return new StringBuilder(phoneNum).append("\t")
.append(upFlow).append("\t")
.append(downFlow).append("\t")
.append(getTotalFlow())
.toString();
} }
Flow
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class PhoneFlowMapper01 extends Mapper<LongWritable, Text, Text, Flow> { private Text outKey;
private Flow outValue; @Override
protected void setup(Mapper<LongWritable, Text, Text, Flow>.Context context)
throws IOException, InterruptedException {
outKey = new Text();
outValue = new Flow();
} @Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Flow>.Context context)
throws IOException, InterruptedException { String line = value.toString();
String[] fields = line.split("\\s+"); //过滤无效不完整的数据
if(fields.length<3) return; String phoneNum = fields[0];
String upFlow = fields[1];
String downFlow = fields[2]; outKey.set(phoneNum);
outValue.setFlow(phoneNum, Long.parseLong(upFlow), Long.parseLong(downFlow));;
context.write(outKey, outValue); } @Override
protected void cleanup(Mapper<LongWritable, Text, Text, Flow>.Context context)
throws IOException, InterruptedException {
outKey = null;
outValue = null;
} }
PhoneFlowMapper01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class PhoneFlowReducer01 extends Reducer<Text, Flow, NullWritable, Flow> { private NullWritable outKey;
private Flow outValue; @Override
protected void setup(Reducer<Text, Flow, NullWritable, Flow>.Context context) throws IOException, InterruptedException {
outKey = NullWritable.get();
outValue = new Flow();
} @Override
protected void reduce(Text key, Iterable<Flow> values, Reducer<Text, Flow, NullWritable, Flow>.Context context)
throws IOException, InterruptedException {
Iterator<Flow> its = values.iterator(); Long totalUpFlow = 0L;//此处是Long类型,不能设置成null;
Long totalDownFlow = 0L;
while (its.hasNext()) {
Flow flow = its.next();
totalUpFlow += flow.getUpFlow();//求和千万别忘记+号
totalDownFlow += flow.getDownFlow();
} outValue.setFlow(key.toString(), totalUpFlow, totalDownFlow);
context.write(outKey, outValue); } @Override
protected void cleanup(Reducer<Text, Flow, NullWritable, Flow>.Context context) throws IOException, InterruptedException {
outValue = null;
} }
PhoneFlowReducer01
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* @author hadoop
*
*/
public class PhoneFlowDriver01 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job pfJob01 = getJob(args);
if (null == pfJob01) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = false;
flag = pfJob01.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[0]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[1]); //获取Job实例
Job pfJob01 = Job.getInstance(conf, "pfJob0102");
//设置运行此jar包入口类
//pfJob01的入口是WordCountDriver类
pfJob01.setJarByClass(PhoneFlowDriver01.class);
//设置Job调用的Mapper类
pfJob01.setMapperClass(PhoneFlowMapper01.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
pfJob01.setReducerClass(PhoneFlowReducer01.class); //设置MapTask的输出键类型
pfJob01.setMapOutputKeyClass(Text.class);
//设置MapTask的输出值类型
pfJob01.setMapOutputValueClass(Flow.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
pfJob01.setOutputKeyClass(NullWritable.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
pfJob01.setOutputValueClass(Flow.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(pfJob01, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(pfJob01, outputPath); return pfJob01;
} }
PhoneFlowDriver01
package com.mmzs.bigdata.yarn.mapreduce; // import java.io.IOException;
// import org.apache.hadoop.io.LongWritable;
// import org.apache.hadoop.io.NullWritable;
// import org.apache.hadoop.io.Text;
// import org.apache.hadoop.mapreduce.Mapper;
// import org.apache.hadoop.mapreduce.lib.input.FileSplit; // public class PhoneFlowMapper02 extends Mapper<LongWritable, Text, Flow, NullWritable> { // private Flow outKey;
// private NullWritable outValue; // @Override
// protected void setup(Mapper<LongWritable, Text, Flow, NullWritable>.Context context)
// throws IOException, InterruptedException {
// outKey = new Flow();
// outValue = NullWritable.get();
// } // @Override
// protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Flow, NullWritable>.Context context)
// throws IOException, InterruptedException { // String line = value.toString();
// String[] fields = line.split("\\s+"); // String phoneNum = fields[0];
// String upFlow = fields[1];
// String downFlow = fields[2]; 因为获取过来的都是String类型,所以需要转换参数类型
// outKey.setFlow(phoneNum, Long.parseLong(upFlow), Long.parseLong(downFlow));;
// context.write(outKey, outValue); // } // @Override
// protected void cleanup(Mapper<LongWritable, Text, Flow, NullWritable>.Context context)
// throws IOException, InterruptedException {
// outKey = null;
// outValue = null;
// } // }
PhoneFlowMapper02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List; import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class PhoneFlowReducer02 extends Reducer<Flow, NullWritable, Flow, NullWritable> { private NullWritable outValue; @Override
protected void setup(Reducer<Flow, NullWritable, Flow, NullWritable>.Context context) throws IOException, InterruptedException {
outValue = NullWritable.get();
} @Override
protected void reduce(Flow key, Iterable<NullWritable> values, Reducer<Flow, NullWritable, Flow, NullWritable>.Context context)
throws IOException, InterruptedException {
//此reduce不能少,它会自动调用compareTo方法进行排序
//排序的工作是在shuffle的工程中进行的
context.write(key, outValue);
} @Override
protected void cleanup(Reducer<Flow, NullWritable, Flow, NullWritable>.Context context) throws IOException, InterruptedException {
outValue = null;
} }
PhoneFlowReducer02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /**
* @author hadoop
*
*/
public class PhoneFlowDriver02 { private static FileSystem fs;
private static Configuration conf;
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job pfJob02 = getJob(args);
if (null == pfJob02) {
return;
}
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag = false;
flag = pfJob02.waitForCompletion(true);
System.exit(flag?0:1);
} /**
* 获取Job实例
* @param args
* @return
* @throws IOException
*/
public static Job getJob(String[] args) throws IOException {
if (null==args || args.length<2) return null;
//放置需要处理的数据所在的HDFS路径
Path inputPath = new Path(args[1]);
//放置Job作业执行完成之后其处理结果的输出路径
Path outputPath = new Path(args[2]); //获取Job实例
Job pfJob02 = Job.getInstance(conf, "pfJob02");
//设置运行此jar包入口类
//pfJob02的入口是WordCountDriver类
pfJob02.setJarByClass(PhoneFlowDriver02.class);
//设置Job调用的Mapper类
pfJob02.setMapperClass(PhoneFlowMapper02.class);
//设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句)
pfJob02.setReducerClass(PhoneFlowReducer02.class); //设置MapTask的输出键类型
pfJob02.setMapOutputKeyClass(Flow.class);
//设置MapTask的输出值类型
pfJob02.setMapOutputValueClass(NullWritable.class); //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句)
pfJob02.setOutputKeyClass(Flow.class);
//设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句)
pfJob02.setOutputValueClass(NullWritable.class); //设置整个Job需要处理数据的输入路径
FileInputFormat.setInputPaths(pfJob02, inputPath);
//设置整个Job计算结果的输出路径
FileOutputFormat.setOutputPath(pfJob02, outputPath); return pfJob02;
} }
PhoneFlowDriver02
package com.mmzs.bigdata.yarn.mapreduce; import java.io.File;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job; public class PhoneFlowDriver { private static FileSystem fs;
private static Configuration conf;
private static final String TEMP= "hdfs://master01:9000/data/phoneflow/tmp";
static {
String uri = "hdfs://master01:9000/";
conf = new Configuration();
try {
fs = FileSystem.get(new URI(uri), conf, "hadoop");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
} public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
if (null == args || args.length<2) {
System.out.println("参数至少是两个");
return;
} Path inputPath = new Path(args[0]);
Path outputPath = new Path(args[1]);
Path tmpPath = new Path(TEMP);
//主机文件路径
File localPath = new File("/home/hadoop/test/phoneflow");
//如果输入的集群路径存在,则删除
if (fs.exists(outputPath)) fs.delete(outputPath, true);
if (fs.exists(tmpPath)) fs.delete(tmpPath, true);
if (!fs.exists(inputPath)) {
//创建并且将数据文件拷贝到创建的集群路径
Boolean flag = fs.mkdirs(inputPath);
if (!flag) {
System.out.println("创建集群路径失败");
}
File[] files = localPath.listFiles();
Path[] localPaths = new Path[files.length];
for (int i = 0; i < files.length; i++) {
localPaths[i] = new Path(files[i].getAbsolutePath());
}
fs.copyFromLocalFile(false, false, localPaths, inputPath);
} String[] params = {args[0], TEMP, args[1]}; //运行第1个Job
Job pfJob01 = PhoneFlowDriver01.getJob(params);
if (null == pfJob01) return;
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
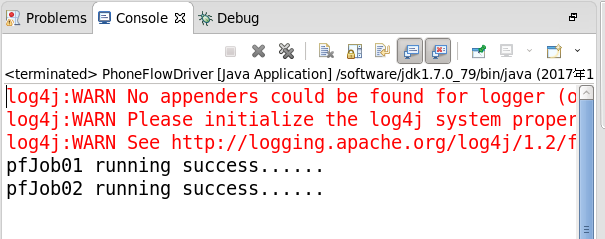
boolean flag01 = pfJob01.waitForCompletion(true);
if (!flag01) {
System.out.println("pfJob01 running failure......");
System.exit(1);
}
System.out.println("pfJob01 running success......"); //运行第2个Job
Job pfJob02 = PhoneFlowDriver02.getJob(params);
if (null == pfJob02) return;
//提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端
boolean flag02 = pfJob02.waitForCompletion(true);
if (flag02) {//等待Job02完成后就删掉中间目录并退出;
fs.delete(new Path(TEMP), true);
System.out.println("pfJob02 running success......");
System.exit(0);
}
System.out.println("pfJob02 running failure......");
System.exit(1);
} }
PhoneFlowDriver(主类)
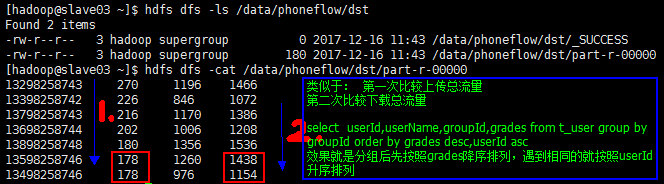
目标二:
想要达到目标二,只需将排序的方法做一定的修改即可;
所以我们需要修改Flow类中作排序依据比较的compareTo方法;
@Override
public int compareTo(Flow flow) {
//目标一:按照总流量进行排序
// Long curTotalFlow=this.getTotalFlow();
// Long paramTotalFlow=flow.getTotalFlow();
// Long resFlow=curTotalFlow-paramTotalFlow; //目标二:先按照上行流量进行排序,如果相同再比较总流量
Long curUpFlow=this.getUpFlow();
Long paramUpFlow=flow.getUpFlow();
Long resFlow=curUpFlow-paramUpFlow;
//如果上行流量相同就比较总流量
if(resFlow==0){
Long curTotalFlow=this.getTotalFlow();
Long paramTotalFlow=flow.getTotalFlow();
resFlow=curTotalFlow-paramTotalFlow;
} return resFlow>0?-1:1;
}
compareTo
测试结果:
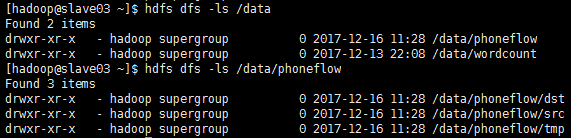
运行时传入参数是:
如果在客户端eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/phoneflow/src
输出路径参数: /data/phoneflow/dst
目标一:

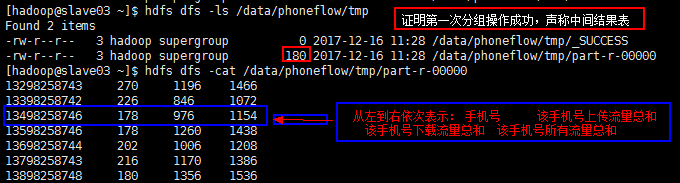
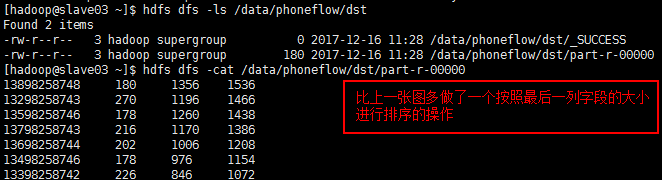
目标二:
YARN集群的mapreduce测试(四)的更多相关文章
- YARN集群的mapreduce测试(一)
hadoop集群搭建中配置了mapreduce的别名是yarn [hadoop@master01 hadoop]$ mv mapred-site.xml.template mapred-site.xm ...
- YARN集群的mapreduce测试(六)
两张表链接操作(分布式缓存): ----------------------------------假设:其中一张A表,只有20条数据记录(比如group表)另外一张非常大,上亿的记录数量(比如use ...
- YARN集群的mapreduce测试(五)
将user表计算后的结果分区存储 测试准备: 首先同步时间,然后master先开启hdfs集群,再开启yarn集群:用jps查看: master上: 先有NameNode.SecondaryNameN ...
- YARN集群的mapreduce测试(三)
将user表.group表.order表关:(类似于多表关联查询) 测试准备: 首先同步时间,然后 开启hdfs集群,开启yarn集群:在本地"/home/hadoop/test/" ...
- YARN集群的mapreduce测试(二)
只有mapTask任务没有reduceTask的情况: 测试准备: 首先同步时间,然后 开启hdfs集群,开启yarn集群:在本地"/home/hadoop/test/"目录创建u ...
- 大数据入门第八天——MapReduce详解(三)MR的shuffer、combiner与Yarn集群分析
/mr的combiner /mr的排序 /mr的shuffle /mr与yarn /mr运行模式 /mr实现join /mr全局图 /mr的压缩 今日提纲 一.流量汇总排序的实现 1.需求 对日志数据 ...
- Yarn 集群环境 HA 搭建
环境准备 确保主机搭建 HDFS HA 运行环境 步骤一:修改 mapred-site.xml 配置文件 [root@node-01 ~]# cd /root/apps/hadoop-3.2.1/et ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- Yarn篇--搭建yarn集群
一.前述 有了上次hadoop集群的搭建,搭建yarn就简单多了.废话不多说,直接来 二.规划 三.配置如下 yarn-site.xml配置 <property> <n ...
随机推荐
- 洛谷P2689 东南西北
https://www.luogu.org/problemnew/show/P2689 #include<iostream> #include<algorithm> using ...
- eclipse启动时要求高版本jdk的问题
在eclipse.ini文件首行添加 -vm C:\Program Files\Java\jdk1.8\jdk1.8.0_131\bin https://blog.csdn.net/wanlin77/ ...
- 20145232韩文浩 《网络对抗技术》 Web基础
Apache 因为端口号80已经被占用(上次实验设置的),所以先修改/etc/apache2/ports.conf里的端口为5232后重新开启 可以在浏览器中输入localhost:5208来检查是否 ...
- bzoj4445(半平面交)
列出式子对一下然后上半平面交 #include<iostream> #include<cstring> #include<cmath> #include<cs ...
- List、Set、数据结构、Collections
一.数据结构: 1.什么是数据结构: 一种数据的存储方式 2.常见的4+1种数据结构 堆栈结构: 它是只有一个开口的容器结构 特点: 先进后出(FILO) 例子:弹夹,桶装可比克 队列结构: 它是两端 ...
- Collection类,泛型
Collection(接口) 所有超级接口: Iterable<E> 一.集合 1.集合的介绍&集合和数组的区别 什么是集合:java中的一种容器 什么是数组:java中的一种容器 ...
- Tmux会话的使用
不想看废话的直接拖到下面看干货部分! 我们管理Linux服务器通常是通过ssh远程连接过去,如果在服务器上执行比较耗时的操作,比如下载安装软件.编译等等,如果需要数个小时来完成这些工作,但是又不得不关 ...
- MySQL9:索引实战
索引 无论是面试,还是实际工作中,对于一个Java程序员来说,数据库优化是避不开的一个技术点,关于数据库的优化,在性能达不到要求的情况下,我大致给出以下几个方向: (1)优化表结构,对常用字段和非常用 ...
- VSCode插件开发全攻略(五)跳转到定义、自动补全、悬停提示
更多文章请戳VSCode插件开发全攻略系列目录导航. 跳转到定义 跳转到定义其实很简单,通过vscode.languages.registerDefinitionProvider注册一个provide ...
- Ettercap 实施中间人攻击
中间人攻击(MITM)该攻击很早就成为了黑客常用的一种古老的攻击手段,并且一直到如今还具有极大的扩展空间,MITM攻击的使用是很广泛的,曾经猖獗一时的SMB会话劫持.DNS欺骗等技术都是典型的MITM ...