elasticsearch 通过HTTP RESTful API 操作数据
1、索引样例数据
下载样例数据集链接 下载后解压到ES的bin目录,然后加载到elasticsearch集群

curl -XPOST 127.0.0.1:9200/bank/account/_bulk?pretty --data-binary @accounts.json
如果accounts.json文件和bin目录并列:curl -XPOST 127.0.0.1:9200/bank/account/_bulk?pretty --data-binary @..\accounts.json

查看索引:curl localhost:9200/_cat/indices?v
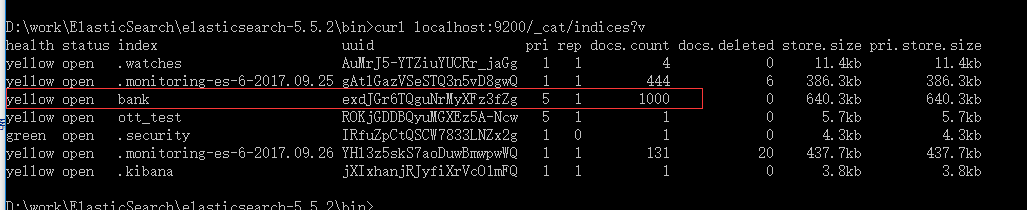
上面结果,说明我们成功bulk 1000个文档到bank索引中了
删除索引bank:curl -XDELETE http://127.0.0.1:9200/bank
2、搜索数据API
有两种方式:一种方式是通过 REST 请求 URI ,发送搜索参数;另一种是通过REST 请求体,发送搜索参数。而请求体允许你包含更容易表达和可阅读的JSON格式。
2.1、通过 REST 请求 URI
curl localhost:9200/bank/_search?pretty
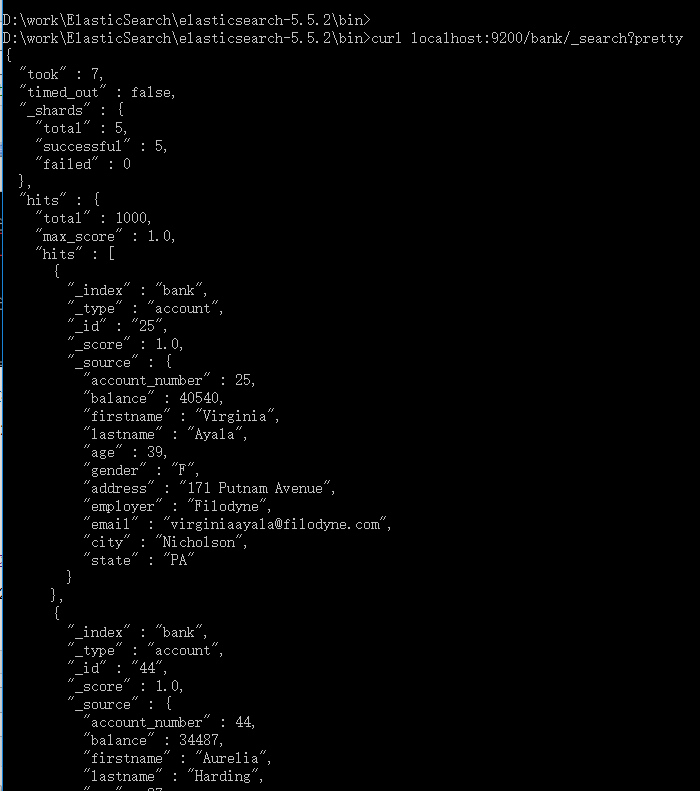
pretty,参数告诉elasticsearch,返回形式打印JSON结果
2.2、通过REST 请求体
curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_all\": {} }}"
query:告诉我们定义查询
match_all:运行简单类型查询指定索引中的所有文档

除了指定查询参数,还可以指定其他参数来影响最终的结果。
2.3、match_all & 只返回前两个文档:

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"size\" : 2}"

如果不指定size,默认是返回10条文档信息
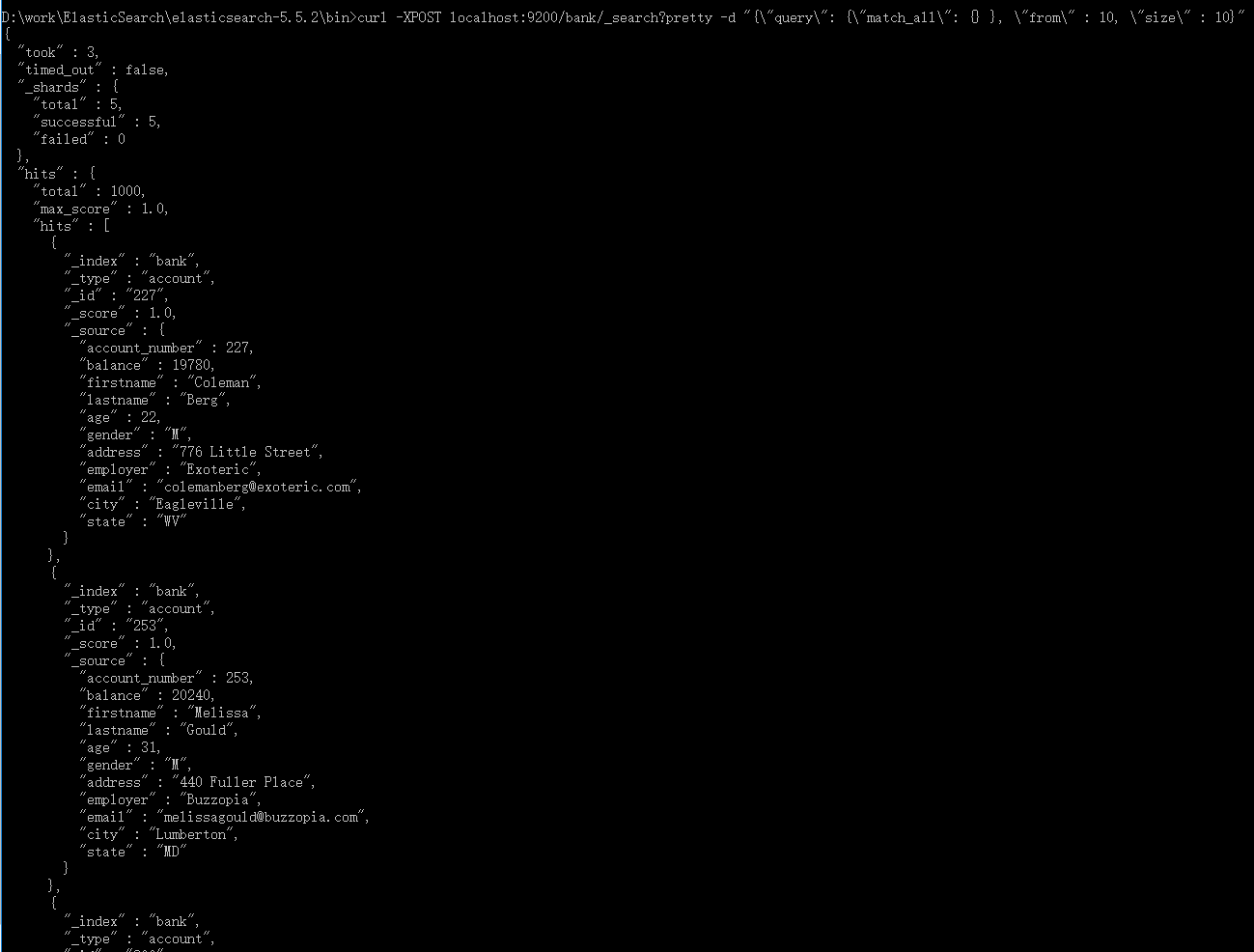
2.4、match_all & 返回第11到第20的10个文档信息

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"from\" : 10, \"size\" : 10}"
from:指定文档索引从哪里开始,默认从0开始
size:从from开始,返回多个文档
这feature在实现分页查询很有用
2.5、match_all and 根据account 的balance字段 降序排序 & 返回10个文档(默认10个)
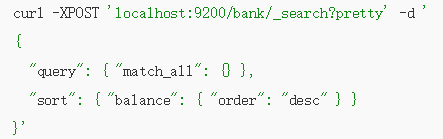
curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"sort\" : {\"balance\" : {\"order\" : \"desc\" }}}"
2.6、比如只返回account_number 和balance两个字段
默认的,我们搜索返回完整的JSON文档。而source(_source字段搜索点击量)。如果我们不想返回完整的JSON文档,我们可以使用source返回指定字段。
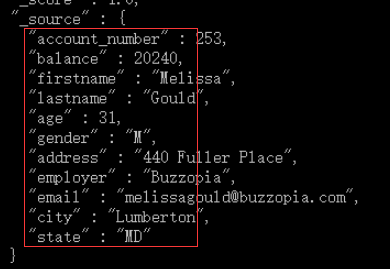
比如只返回account_number 和balance两个字段

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_all\": {} }, \"_source\": [\"account_number\", \"balance\"]}"
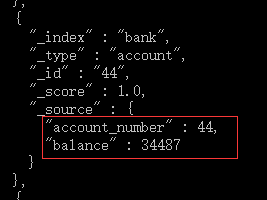
match 查询,可作为基本字段搜索查询
2.7、返回 account_number=20:

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match\": {\"account_number\": 20 } }}"

2.8、返回 address=mill:

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match\": {\"address\": \"mill\" } }}"
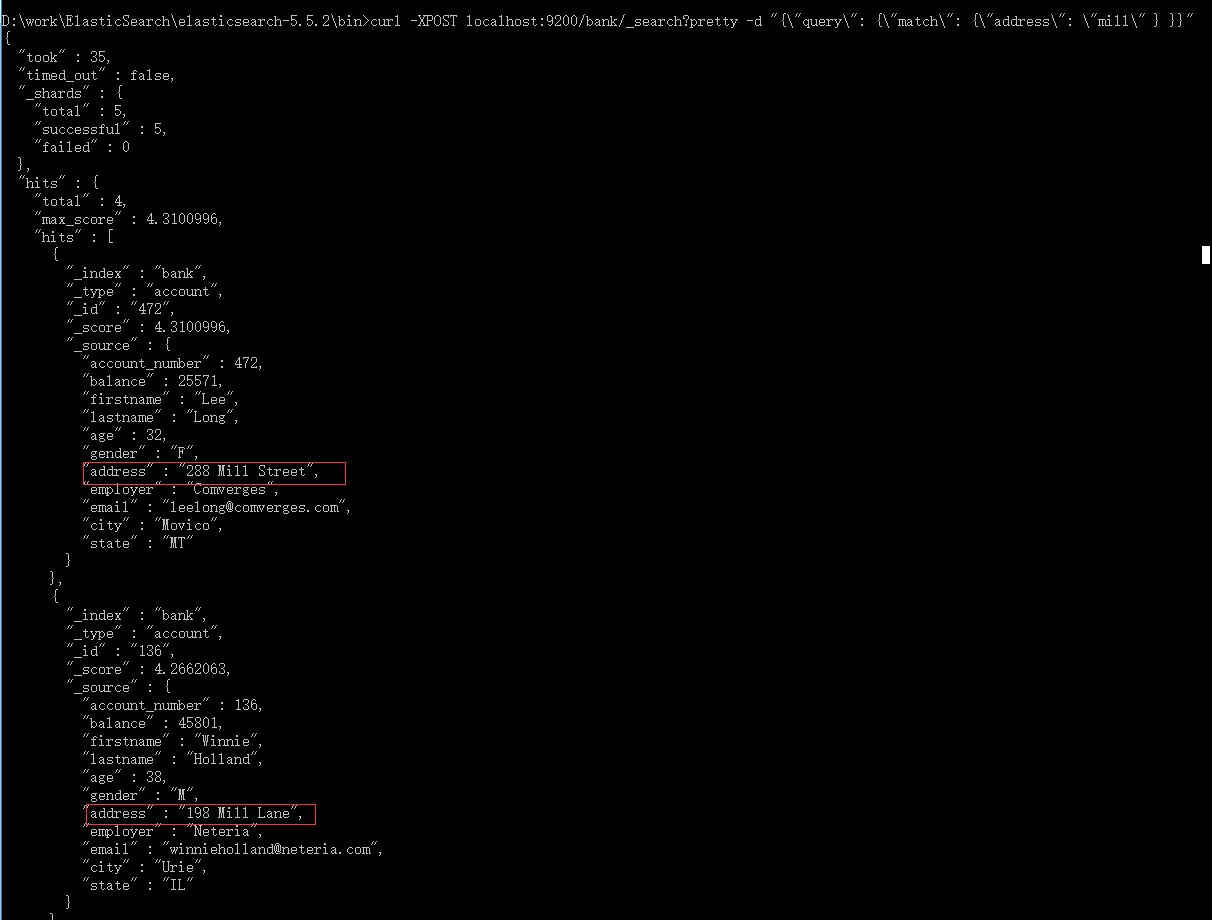
2.9、返回 address=mill or address=lane:

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match\": {\"address\": \"mill lane\" } }}"
2.10、返回 短语匹配 address=mill lane:
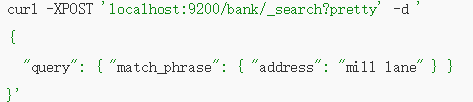
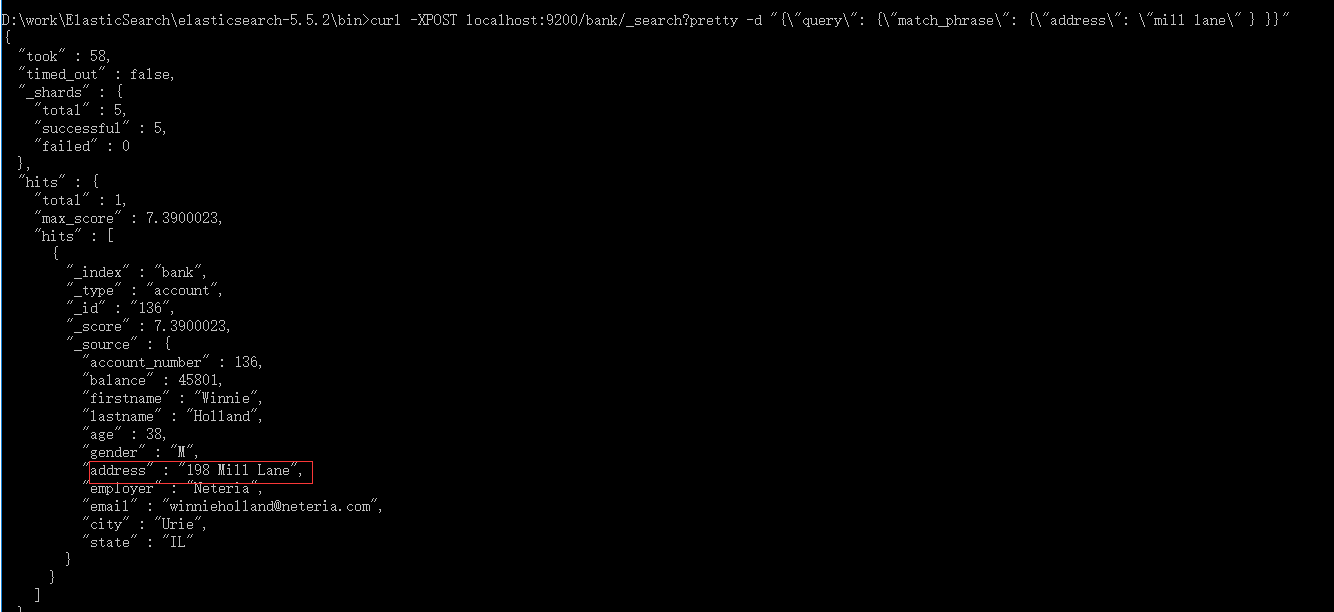
curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"match_phrase\": {\"address\": \"mill lane\" } }}"
2.11、布尔值(bool)查询
返回 匹配address=mill & address=lane:

must:要求所有条件都要满足(类似于&&)
curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"bool\": {\"must\": [{\"match\": {\"address\": \"mill\" }},{\"match\": {\"address\": \"lane\" }}]}}}"
2.12、返回 匹配address=mill or address=lane

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"bool\": {\"should\": [{\"match\": {\"address\": \"mill\" }},{\"match\": {\"address\": \"lane\" }}]}}}"
should:任何一个满足就可以(类似于||)
2.13、返回 不匹配address=mill & address=lane

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"bool\": {\"must_not\": [{\"match\": {\"address\": \"mill\" }},{\"match\": {\"address\": \"lane\" }}]}}}"
must_not:所有条件都不能满足(类似于! (&&))
2.14、返回 age=40 & state!=ID

curl -XPOST localhost:9200/bank/_search?pretty -d "{\"query\": {\"bool\": {\"must\": [{\"match\": {\"address\": \"mill\" }}],\"must_not\": [{\"match\": {\"state\": \"ID\" }}]}}}"
3、执行过滤器
文档中score(_score字段是搜索结果)。score是一个数字型的,是一种相对方法匹配查询文档结果。分数越高,搜索关键字与该文档相关性越高;越低,搜索关键字与该文档相关性越低。
在elasticsearch中所有的搜索都会触发相关性分数计算。如果我们不使用相关性分数计算,那要使用另一种查询能力,构建过滤器。
过滤器是类似于查询的概念,除了得以优化,更快的执行速度的两个主要原因:
1、过滤器不计算得分,所以他们比执行查询的速度
2、过滤器可缓存在内存中,允许重复搜索
为了便于理解过滤器,先介绍过滤器搜索(like match_all, match, bool, etc.),可以与其他的普通查询搜索组合一个过滤器。
range filter,允许我们通过一个范围值来过滤文档,一般用于数字或日期过滤
使用过滤器搜索返回 balances[ 20000,30000]。换句话说,balance>=20000 && balance<=30000

POST /bank/_search?pretty
{
"query": {
"bool": {
"must": { "match": { "age": 39 }},
"must_not": { "match": { "employer":"Digitalus" }},
"filter":
{
"range":
{ "balance":
{
"gte": 20000,
"lte": 30000
}
}
}
}
}
}
3、执行聚合
聚合提供从你的数据中分组和提取统计能力, 类似于关系型数据中的SQL GROUP BY和SQL 聚合函数。
在Elasticsearch中,你有能力执行搜索返回命中结果,同时拆分命中结果,然后统一返回结果。当你使用简单的API运行搜索和多个聚合,然后返回所有结果避免网络带宽过大的情况是高效的。
3.1、根据state分组,降序统计top 10 state
elasticsearch 通过HTTP RESTful API 操作数据的更多相关文章
- 从 0 使用 SpringBoot MyBatis MySQL Redis Elasticsearch打造企业级 RESTful API 项目实战
大家好!这是一门付费视频课程.新课优惠价 699 元,折合每小时 9 元左右,需要朋友的联系爱学啊客服 QQ:3469271680:我们每课程是明码标价的,因为如果售价为现在的 2 倍,然后打 5 折 ...
- Elasticsearch 如何使用RESTful API
所有其他语言可以使用 RESTful API 通过端口 9200 和 Elasticsearch 进行通信,你可以用你最喜爱的 web 客户端访问 Elasticsearch .事实上,正如你所看到的 ...
- Elasticsearch入坑指南之RESTful API
Elasticsearch入坑指南之RESTful API Tags:Elasticsearch ES为开发者提供了非常丰富的基于Http协议的Rest API,通过简单的Rest请求,就可以实现非常 ...
- 可以执行全文搜索的原因 Elasticsearch full-text search Kibana RESTful API with JSON over HTTP elasticsearch_action es 模糊查询
https://www.elastic.co/guide/en/elasticsearch/guide/current/getting-started.html Elasticsearch is a ...
- 利用kibana学习 elasticsearch restful api (DSL)
利用kibana学习 elasticsearch restful api (DSL) 1.了解elasticsearch基本概念Index: databaseType: tableDocument: ...
- elasticsearch组合多条件查询实现restful api以及java代码实现
原文:http://blog.java1234.com/blog/articles/372.html elasticsearch组合多条件查询实现restful api以及java代码实现 实际开发中 ...
- elasticsearch查询所有数据restful api以及java代码实现
原文:http://blog.java1234.com/blog/articles/366.html restful api实现如下: get http://192.168.1.111:9200/fi ...
- RESTful API 设计最佳实践
背景 目前互联网上充斥着大量的关于RESTful API(为了方便,以后API和RESTful API 一个意思)如何设计的文章,然而却没有一个"万能"的设计标准:如何鉴权?API ...
- Yii2框架RESTful API教程(一) - 快速入门
前不久做一个项目,是用Yii2框架写一套RESTful风格的API,就去查了下<Yii 2.0 权威指南 >,发现上面写得比较简略.所以就在这里写一篇教程贴,希望帮助刚接触Yii2框架RE ...
随机推荐
- WePY | 小程序组件化开发框架
资源连接: WePY | 小程序组件化开发框架 WePYAWESOME 微信小程序wepy开发资源汇总 文档 GITHUB weui WebStorm/PhpStorm 配置识别 *.wpy 文件代码 ...
- Windows10 + Visual Studio 2017环境为C++工程安装使用ZMQ
因为需要用 C++ 实现联机对战的功能,但是不想直接用 winsock ,因此选了ZMQ 框架(不知道合不合适).安装的过程还是挺艰辛的.但是也学到了些东西,记录一下.另外,Zmq 的作者 Piete ...
- 自定义Qt构建步骤,添加数据文件(txt,json等)到构建目录
Qt的qrc资源文件是只读的,因此我们如果要用txt之类的文件存储数据,在程序运行过程中就不能对它们进行修改,也就是不能进行读操作.用"file.open(QIODevice::WriteO ...
- python学习日记(python2/3区别补充,is / id/ encode str,bytes)
python2和python3区别 print python2中,print 是语句 :用法 ---->print '***' python3中,print 是函数:用法----->pri ...
- 脚本监控web服务器,工作不正常发邮件提醒
背景介绍公司有多个web网站,没有配置监控服务,每天都需要定时检查服务器是否工作正常.低效耗时. 代码片段 #!/bin/bash # Author Jerry.huang (Email:Jerry. ...
- 栈长这里是生成了一个 Maven 示例项目。
Spring Cloud 的注册中心可以由 Eureka.Consul.Zookeeper.ETCD 等来实现,这里推荐使用 Spring Cloud Eureka 来实现注册中心,它基于 Netfl ...
- Nifi 老是死机
1. nifi服务器配置 CPU:4核 内存:7G 2. 改动如下: nifi.provenance.repository.rollover.time=30 secs --> 36000 s ...
- VSIX 插件右键菜单
vs2017 插件开发 环境 WIN10 VS2017 CMMT VSIX 参考资源: vs菜单命令ID速查 https://docs.microsoft.com/zh-cn/visualstudio ...
- python列表转字符串
temp = "".join(sorted(arr[i])) arr[i] = temp
- ACM-ICPC 2018 南京赛区网络预赛 L题(分层最短路)
题目链接:https://nanti.jisuanke.com/t/31001 题目大意:给出一个含有n个点m条边的带权有向图,求1号顶点到n号顶点的最短路,可以使<=k条任意边的权值变为0. ...