【Teradata】 TPT基础知识
1.TPT Description
- Teradata Parallel Transporter (TPT) is client software that performs data extractions, data transformations, and data loading functions in a scalable, parallel processing environment.
- TPT brings together the traditional Teradata Load Utilities (FastLoad, MultiLoad,FastExport and TPump) into a single product using a single script language.
- A GUI-based TPT Wizard is available for script generation.
- Teradata database is the only target for load operators.
- Any ODBC database, data files or devices may be source data.
2.Architecture
There are two types of parallelism used by TPT: pipeline parallelism and data parallelism .
(1) Pipeline parallelism (also called "functional parallelism")
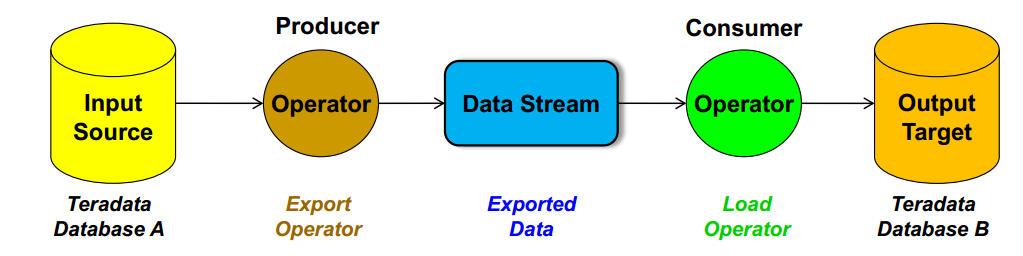
A "producer" operator extracts data from a data source and writes ("produces") it to a data stream.
A "consumer" operator reads ("consumes") the data from the data stream and writes or loads data to the target.
Both operators can operate concurrently and independently of each other. This creates a pipeline effect without the need for intermediary files.
(2) Data Parallelism
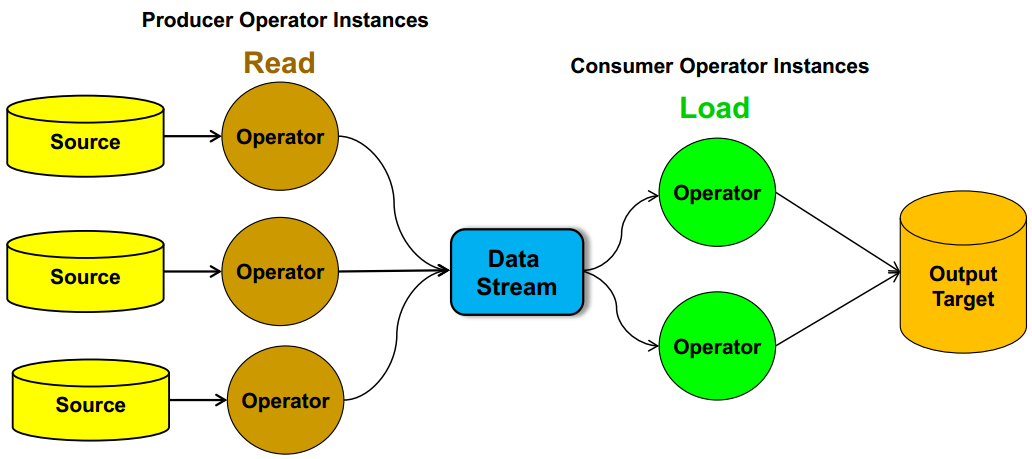
Each file can be handled by a different instance of the producer operator so that the files are read concurrently. The operator instances can then merge these files into a single data stream .
The data stream can then be input to multiple consumer operators.
3. Operator Types
(1) The two key TPT operators are:
Producer operators:[produce a Data Stream]
which 'produce' a data stream, usually by reading source data.
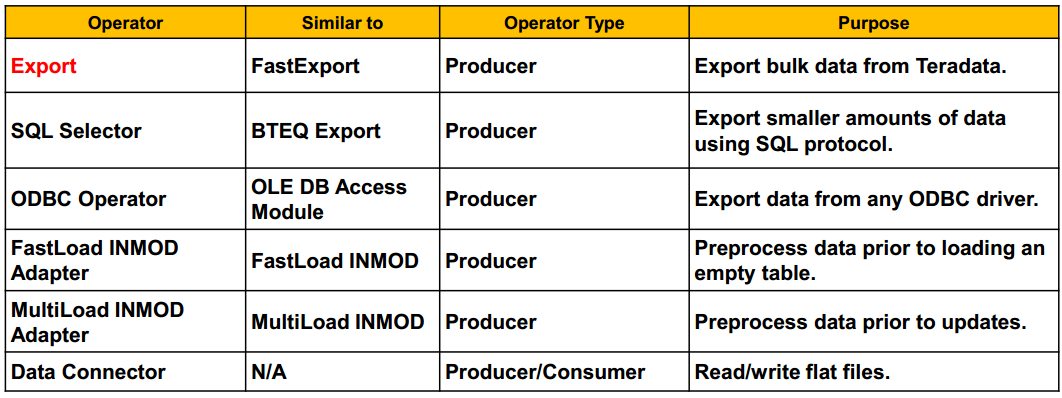
Consumer operators:[consume a Data Stream]
which 'consume' data from a data stream, usually to be loaded to a target.
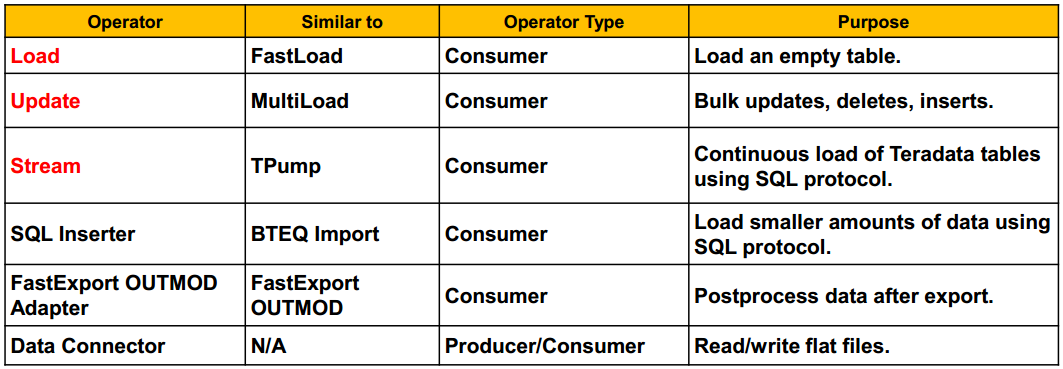
(2) Two additional operator types are:
Filter operators:[Consume and Produce a Data Stream]
which perform data transformation functions such as selection,validation, cleansing, and condensing.
Both consumers and producers since they consume an input data stream and produce an output data stream.
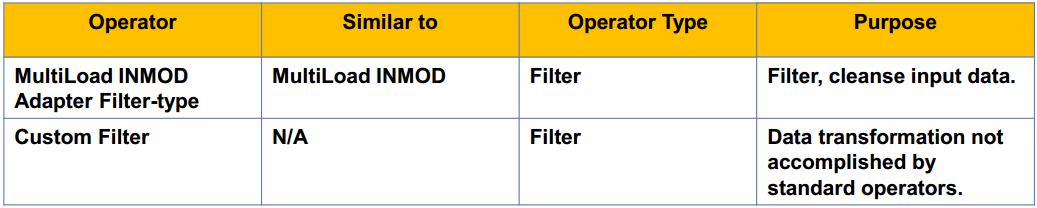
There are 3 ways to perform filtering operations in the TPT environment:
a) Use the MultiLoad INMOD Adapter operator as a filter.
b) Use the CASE statement and the WHERE clause in the APPLY statement to limit sets.
c) Create a custom filter operator using C or C++.
Standalone operators:[No Data Streams]
which perform any processing that does not involve sending data to, or receiving data from the data stream
A standalone operator does not send or receive data, and thus does not use data streams. The following are standalone operators:
- Update (Delete Task) Operator: Uses Update operator to delete rows from a single table.
- DDL Operator: Permits DDL and some DML and DCL commands in a TPT script.
- OS Command: Permits commands to the client OS in a TPT script
Data Connector Operator:Producer or Consumer
TYPE DATACONNECTOR PRODUCER – if the file is being read
TYPE DATACONNECTOR CONSUMER – if the file is being written to
4.Export
(1) Export Job ExampleDEFINE JOB Export_to_FileDESCRIPTION 'Export 1000 rows from AP.Accounts table'
(
DEFINE SCHEMA Accounts_Schema
(Account_Number INTEGER,
Street_Number INTEGER,
Street CHARACTER(25),
City CHARACTER(20),
State CHARACTER(2),
Zip_Code INTEGER,
Balance_Forward DECIMAL(10,2),
Balance_Current DECIMAL(10,2)
);
/* DEFINE SCHEMA Accounts_Schema FROM TABLE 'AP.Accounts';
This is an alternate technique to define your schema */
DEFINE OPERATOR File_Writer
TYPE DATACONNECTOR CONSUMER
SCHEMA Accounts_Schema
ATTRIBUTES
(VARCHAR FileName = 'Export_1000',
VARCHAR Format = 'FORMATTED',
VARCHAR OpenMode = 'Write',
VARCHAR IndicatorMode = 'Y'
); DEFINE OPERATOR Export_Accounts
TYPE EXPORT
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'passwd1',
VARCHAR Tdpid = 'tdp1',
INTEGER MaxSessions = 4,
INTEGER TenacitySleep = 1,
VARCHAR SelectStmt =
'SELECT Account_Number, Street_Number,Street, City, State, Zip_Code,Balance_Forward, Balance_Current FROM AP.Accounts SAMPLE 1000;'
);
APPLY TO OPERATOR (File_Writer[])
SELECT Account_Number, Street_Number, Street,
City, State, Zip_Code, Balance_Forward,
Balance_Current
FROM OPERATOR (Export_Accounts[]);
);
(2) SQL Selector Job Example
DEFINE JOB Select_Accounts
DESCRIPTION 'Select 1000 rows from AP.Accounts table'
(
DEFINE SCHEMA Accounts_Schema FROM TABLE 'AP.Accounts';
/* If your schema is identical (names, sequence, and
data type) to an existing table definition in Teradata,
you can specify the tablename in the DEFINE SCHEMA
statement. The column names are then used in your
operators. */
DEFINE OPERATOR File_Writer
TYPE DATACONNECTOR CONSUMER
SCHEMA Accounts_Schema
ATTRIBUTES
(VARCHAR FileName = 'Select_1000',
VARCHAR Format = 'FORMATTED',
VARCHAR OpenMode = 'Write',
VARCHAR IndicatorMode = 'Y'
);
/**
The DataConnector operator has the following OpenMode options:
– 'Read' = Read-only access.
– 'Write' = Write-only access.
– 'WriteAppend' = Write-only access appending to existing file.
**/
DEFINE OPERATOR Select_Accounts
TYPE SELECTOR
SCHEMA Accounts_Schema
ATTRIBUTES
(VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'passwd1',
VARCHAR Tdpid = 'tdp1',
VARCHAR SelectStmt =
'SELECT Account_Number, Street_Number,Street, City, State, Zip_Code,Balance_Forward, Balance_Current FROM AP.Accounts SAMPLE 100;'
); APPLY TO OPERATOR (File_Writer[])
SELECT
Account_Number, Street_Number, Street, City,
State, Zip_Code, Balance_Forward, Balance_Current
FROM OPERATOR (Select_Accounts[]);
);
(3) Exporting a CSV Data File Example
DEFINE JOB Export_CSV
DESCRIPTION 'Export Accounts data to CSV file'
(
DEFINE SCHEMA Accounts_Schema FROM TABLE DELIMITED 'AP.Accounts';
/* Place above statement on 1 line.
If DELIMITED option is not used,
define each field AS VARCHAR */
/*( Account_Number VARCHAR(11),
:
Balance_Current VARCHAR(12)
);
*/
DEFINE OPERATOR File_Writer
DESCRIPTION 'Writes file to disk'
TYPE DATACONNECTOR CONSUMER
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR FileName = 'accounts_csv',
VARCHAR OpenMode = 'Write',
VARCHAR Format = 'DELIMITED',
VARCHAR TextDelimiter = ',',
VARCHAR IndicatorMode = 'N'
); DEFINE OPERATOR Exp_Accounts
TYPE SELECTOR
SCHEMA Accounts_Schema
ATTRIBUTES
(VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'password1',
VARCHAR Tdpid = 'tdp1',
INTEGER MaxSessions = 1,
VARCHAR SelectStmt =
'SELECT
CAST(Account_Number AS VARCHAR(11)),
CAST(Street_Number AS VARCHAR(11)),
cast( Street as varchar(25)),
cast( City as varchar(20)),
cast( State as varchar(2)),
cast( Zip_Code as varchar(11)),
cast( Balance_Forward as varchar(12)),
CAST(Balance_Current AS VARCHAR(12))
FROM AP.Accounts;'
);
APPLY TO OPERATOR (File_Writer[])
SELECT *
FROM OPERATOR (Exp_Accounts[]);
);
5.LOAD
(1) LOAD Job Example
DEFINE JOB Load_from_File
DESCRIPTION 'Load 1000 rows to empty AP.Accounts'
(
DEFINE SCHEMA Accounts_Schema
( Account_Number INTEGER,
Street_Number INTEGER,
Street CHARACTER(25),
City CHARACTER(20),
State CHARACTER(2),
Zip_Code INTEGER,
Balance_Forward DECIMAL(10,2),
Balance_Current DECIMAL(10,2)
);
DEFINE OPERATOR File_Reader
TYPE DATACONNECTOR PRODUCER
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR FileName = 'Export_1000',
VARCHAR Format = 'FORMATTED',
VARCHAR OpenMode = 'Read',
VARCHAR IndicatorMode = 'Y'
); DEFINE OPERATOR Load_Accounts
TYPE LOAD
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'password1',
VARCHAR Tdpid = 'tdp1',
VARCHAR LogTable = 'Accounts_Load_Log',
VARCHAR TargetTable = 'Accounts',
INTEGER MaxSessions = 8,
INTEGER TenacitySleep = 1,
VARCHAR WildCardInsert = 'N' /*Default */ /*'Y[es]' = builds an INSERT statement 'N[o]' = (default); you must specify a INSERT ... VALUES statement */
);
APPLY ('INSERT INTO Accounts (Account_Number,
Street_Number, Street, City, State,
Zip_Code, Balance_Forward, Balance_Current)
VALUES (:account_number, :street_number, :street,
:city, :state, :zip_code,
:balance_forward, :balance_current);')
TO OPERATOR (Load_Accounts[])
SELECT Account_Number, Street_Number, Street,City,
State, Zip_Code, Balance_Forward, Balance_Current
FROM OPERATOR (File_Reader[]);
);
(2)LOAD Job Example (WildCardInsert)
The WildCardInsert option ONLY is available to the LOAD operator and does NOT work with the other operators
DEFINE OPERATOR Load_Accounts
TYPE LOAD
SCHEMA Accounts_Schema
ATTRIBUTES
( VARCHAR UserName = 'user1',
VARCHAR UserPassword = 'password1',
VARCHAR Tdpid = 'tdp1',
VARCHAR LogTable = 'Accounts_Load_Log',
VARCHAR TargetTable = 'Accounts',
INTEGER MaxSessions = 8,
INTEGER TenacitySleep = 1,
VARCHAR WildCardInsert = 'Y' /*Not default*/
);
APPLY ('INSERT INTO Accounts;')
TO OPERATOR (Load_Accounts[])
SELECT * FROM OPERATOR (File_Reader[]);
);
(3) Data Conversions
TPT permits conversion in the APPLY statement. Data can be converted to an alternate data type, or be changed to/from a null
APPLY
( 'INSERT INTO Customer
VALUES (:Customer_Number, :Last_Name, :First_Name, :Social_Security);')
TO OPERATOR (Load_Customer [])
SELECT
Customer_Number
,Last_Name
,First_Name
,CASE WHEN (Social_Security = 0) THEN NULL
ELSE Social_Security
END AS Social_Security
/* A derived column name is needed that matches the schema name */
FROM OPERATOR (File_Reader []);
);
(4) Checkpoint Option
Checkpoints slow down Load processing
使用方式一:
tbuild -f scriptfilename -z 60
f - This indicates the script file which is input to tbuild.
z - This indicates that a checkpoint will be taken every 60 seconds. 使用方式二:
DEFINE JOB test_job
SET CHECKPOINT INTERVAL 60 SECONDS
...
(5) Techniques to Load Multiple Data Files
- UNION ALL – can be used with APPLY to combine multiple data files (and optionally from different data sources) into a single source data stream.
- File List – this is filename which contains a list of the data files to process.
- Directory Scan – can be used to scan a directory for files to be processed.
- Staged Loading – if you want to process data files serially or if they arrive at different times, the first data file can be loaded and additional files are loaded as needed.
APPLY
('INSERT INTO Customer VALUES (:CustNum, … );')
TO OPERATOR (MyUpdateOperator [])
SELECT * FROM OPERATOR (FileReader[]
ATTRIBUTES (FileName = 'custdata1'))
UNION ALL
SELECT * FROM OPERATOR (FileReader[]
ATTRIBUTES (FileName = 'custdata2'));
APPLY
( 'INSERT INTO Customer VALUES (:CustNum, … ) ;')
TO OPERATOR (MyUpdateOperator [] )
SELECT * FROM OPERATOR
(MyExportOperator [] ATTRIBUTES
(SelectStmt = 'SELECT * FROM Customer WHERE CustNum <= 100000;')
)
UNION ALL
SELECT * FROM OPERATOR
(MyExportOperator [] ATTRIBUTES
(SelectStmt = 'SELECT * FROM Customer WHERE CustNum > 100000;')
);
执行TPT脚本
tbuild -f scriptname.tpt
【Teradata】 TPT基础知识的更多相关文章
- .NET面试题系列[1] - .NET框架基础知识(1)
很明显,CLS是CTS的一个子集,而且是最小的子集. - 张子阳 .NET框架基础知识(1) 参考资料: http://www.tracefact.net/CLR-and-Framework/DotN ...
- RabbitMQ基础知识
RabbitMQ基础知识 一.背景 RabbitMQ是一个由erlang开发的AMQP(Advanced Message Queue )的开源实现.AMQP 的出现其实也是应了广大人民群众的需求,虽然 ...
- Java基础知识(壹)
写在前面的话 这篇博客,是很早之前自己的学习Java基础知识的,所记录的内容,仅仅是当时学习的一个总结随笔.现在分享出来,希望能帮助大家,如有不足的,希望大家支出. 后续会继续分享基础知识手记.希望能 ...
- selenium自动化基础知识
什么是自动化测试? 自动化测试分为:功能自动化和性能自动化 功能自动化即使用计算机通过编码的方式来替代手工测试,完成一些重复性比较高的测试,解放测试人员的测试压力.同时,如果系统有不份模块更改后,只要 ...
- [SQL] SQL 基础知识梳理(一)- 数据库与 SQL
SQL 基础知识梳理(一)- 数据库与 SQL [博主]反骨仔 [原文地址]http://www.cnblogs.com/liqingwen/p/5902856.html 目录 What's 数据库 ...
- [SQL] SQL 基础知识梳理(二) - 查询基础
SQL 基础知识梳理(二) - 查询基础 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5904824.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(三) - 聚合和排序
SQL 基础知识梳理(三) - 聚合和排序 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5926689.html 序 这是<SQL 基础知识梳理 ...
- [SQL] SQL 基础知识梳理(四) - 数据更新
SQL 基础知识梳理(四) - 数据更新 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5929786.html 序 这是<SQL 基础知识梳理( ...
- [SQL] SQL 基础知识梳理(五) - 复杂查询
SQL 基础知识梳理(五) - 复杂查询 [博主]反骨仔 [原文]http://www.cnblogs.com/liqingwen/p/5939796.html 序 这是<SQL 基础知识梳理( ...
随机推荐
- [转]How to Add Bootstrap to an Angular CLI project
本文转自:https://loiane.com/2017/08/how-to-add-bootstrap-to-an-angular-cli-project/ In this article we w ...
- Python学习总结(一)—— 十分钟入门
一.Python概要 1.1.语言简介 Python是一种解释型.面向对象.动态数据类型的高级程序设计语言,具有20多年的发展历史,成熟且稳定. 用任何编程语言来开发程序,都是为了让计算机干活,比如下 ...
- C# 输出字符串到文本文件中
写个博客记录下,方便以后使用: public class WriteHelper { public static void WriteFile(object data) { try { string ...
- sql查询语句时怎么把几个字段拼接成一个字段
sql查询语句时怎么把几个字段拼接成一个字段SELECT CAST(COLUMN1 AS VARCHAR(10)) + '-' + CAST(COLUMN2 AS VARCHAR(10) ...) a ...
- [PHP] 2018年终总结
去掉敏感信息后的不完整版 ==========================================================================2018年12月29日 记 ...
- laravel的时间日期处理包Carbon用法
时间日期处理包--Carbon Carbon – 是继承自 PHP DateTime 类的 API 扩展,它使得处理日期和时间更加简单.Laravel 中默认使用的时间处理类就是 Carbon. La ...
- devtools进行热部署
热部署的形式这里只介绍一种devtools devtools可以实现页面热部署(即页面修改后会立即生效,这个可以直接在application.properties文件中配置spring.thymele ...
- Gvim 和vim 有什么区别
Gvim 和vim 有什么区别 Gvim是windows的 vim是linux的黑色的命令符 Gvim是单独的窗口下的vim,像notepad一样. vim就是在黑乎乎的cmd窗口下的编辑器.wind ...
- 持续集成 自动化构建、测试、部署您的Coding代码
持续集成(Continuous Integration)指的是,频繁地(一天多次)将代码集成到主干. 持续集成的目的,就是让产品可以快速迭代,同时还能保持高质量. 它的核心措施是,代码集成到主干之前, ...
- Springboot@Configuration和@Bean详解
Springboot@Configuration和@Bean详解 一.@Configuration @Target({ElementType.TYPE}) @Retention(RetentionPo ...