TensorBoard 实践 1
从新查看图的时候,删除旧的logs/下面的文件
tf.scalar_summary('loss',self.loss)
AttributeError: 'module' object has no attribute 'scalar_summary'
解决:
tf.scalar_summary('images', images)改为:tf.summary.scalar('images', images)
tf.image_summary('images', images)改为:tf.summary.image('images', images)
类似的有:
tf.train.SummaryWriter改为:tf.summary.FileWriter()
tf.merge_all_summaries()改为:summary_op = tf.summaries.merge_all()
tf.histogram_summary(var.op.name, var)改为: tf.summaries.histogram()
concated = tf.concat(1, [indices, sparse_labels])改为:concated = tf.concat([indices, sparse_labels], 1)
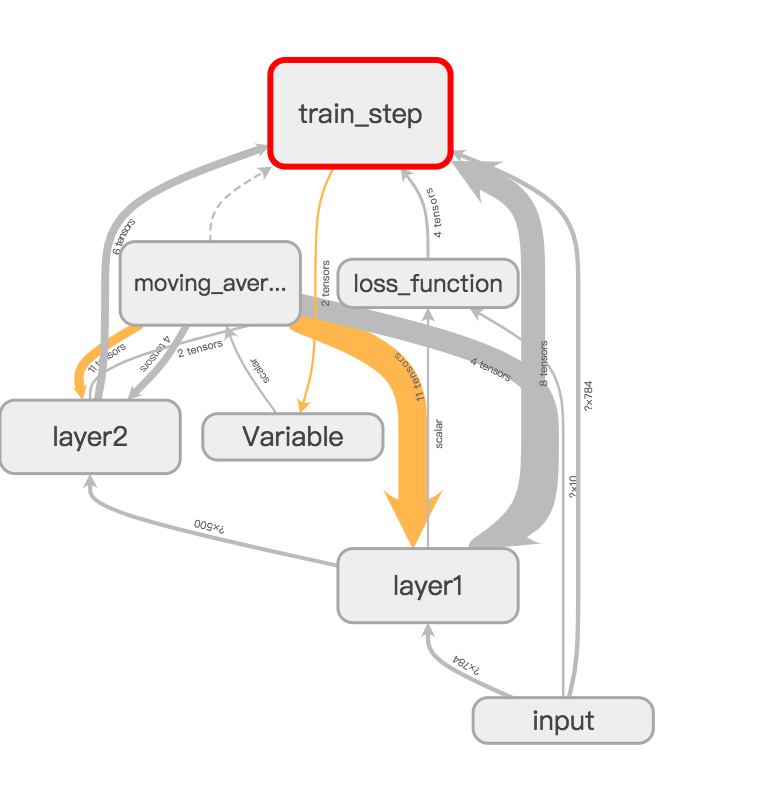
通过对命名空间管理,改进代码,使得可视化效果图更加清晰。
#coding=utf8
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
BATCH_SIZE = 100
LEARNING_RATE_BASE = 0.8
LEARNING_RATE_DECAY = 0.99
REGULARIZATION_RATE = 0.0001
TRAINING_STEPS = 3000
MOVING_AVERAGE_DECAY = 0.99
def train(mnist):
# 输入数据的命名空间。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, mnist_inference.INPUT_NODE], name='x-input')
y_ = tf.placeholder(tf.float32, [None, mnist_inference.OUTPUT_NODE], name='y-input')
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
y = mnist_inference.inference(x, regularizer)
global_step = tf.Variable(0, trainable=False)
# 处理滑动平均的命名空间。
with tf.name_scope("moving_average"):
variable_averages = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECAY, global_step)
variables_averages_op = variable_averages.apply(tf.trainable_variables())
# 计算损失函数的命名空间。
with tf.name_scope("loss_function"):
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_, 1))
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses'))
# 定义学习率、优化方法及每一轮执行训练的操作的命名空间。
with tf.name_scope("train_step"):
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
mnist.train.num_examples / BATCH_SIZE, LEARNING_RATE_DECAY,
staircase=True)
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step=global_step)
with tf.control_dependencies([train_step, variables_averages_op]):
train_op = tf.no_op(name='train')
writer = tf.summary.FileWriter("./log/modified_mnist_train.log", tf.get_default_graph())
# 训练模型。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(TRAINING_STEPS):
xs, ys = mnist.train.next_batch(BATCH_SIZE)
if i % 1000 == 0:
# 配置运行时需要记录的信息。
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
# 运行时记录运行信息的proto。
run_metadata = tf.RunMetadata()
_, loss_value, step = sess.run(
[train_op, loss, global_step], feed_dict={x: xs, y_: ys},
options=run_options, run_metadata=run_metadata)
writer.add_run_metadata(run_metadata=run_metadata, tag=("tag%d" % i), global_step=i)
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
else:
_, loss_value, step = sess.run([train_op, loss, global_step], feed_dict={x: xs, y_: ys})
writer.close()
def main(argv=None):
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
train(mnist)
if __name__ == '__main__':
main()
可视化效果图:
TensorBoard 实践 1的更多相关文章
- TF:TF之Tensorboard实践:将神经网络Tensorboard形式得到events.out.tfevents文件+dos内运行该文件本地服务器输出到网页可视化—Jason niu
import tensorflow as tf import numpy as np def add_layer(inputs, in_size, out_size, n_layer, activat ...
- tensorflow笔记(三)之 tensorboard的使用
tensorflow笔记(三)之 tensorboard的使用 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7429344.h ...
- 学习笔记TF039:TensorBoard
首先向大家和<TensorFlow实战>的作者说句不好意思.我现在看的书是<TensorFlow实战>.但从TF024开始,我在学习笔记的参考资料里一直写的是<Tenso ...
- 4. Tensorflow的Estimator实践原理
1. Tensorflow高效流水线Pipeline 2. Tensorflow的数据处理中的Dataset和Iterator 3. Tensorflow生成TFRecord 4. Tensorflo ...
- ML平台_小米深度学习平台的架构与实践
(转载:http://www.36dsj.com/archives/85383)机器学习与人工智能,相信大家已经耳熟能详,随着大规模标记数据的积累.神经网络算法的成熟以及高性能通用GPU的推广,深度学 ...
- Ubuntu环境下TensorBoard 可视化 不显示数据问题 No scalar data was found...(作者亲测有效)(转)
TensorBoard:Tensorflow自带的可视化工具.利用TensorBoard进行图表可视化时遇到了图表不显示的问题. 环境:Ubuntu系统 运行代码,得到TensorFlow的事件文件l ...
- 3.keras实现-->高级的深度学习最佳实践
一.不用Sequential模型的解决方案:keras函数式API 1.多输入模型 简单的问答模型 输入:问题 + 文本片段 输出:回答(一个词) from keras.models import M ...
- FasterRCNN目标检测实践纪实
首先声明参考博客:https://blog.csdn.net/beyond_xnsx/article/details/79771690?tdsourcetag=s_pcqq_aiomsg 实践过程主线 ...
- Python玩转人工智能最火框架 TensorFlow应用实践 ☝☝☝
Python玩转人工智能最火框架 TensorFlow应用实践 (一个人学习或许会很枯燥,但是寻找更多志同道合的朋友一起,学习将会变得更加有意义✌✌) 全民人工智能时代,不甘心只做一个旁观者,那就现在 ...
随机推荐
- DB中字段为null,为空,为空字符串,为空格要怎么过滤取出有效值
比如要求取出微信绑定的,没有解绑的 未绑定,指定字段为null 绑定的,指定字段为某个字符串 解绑的,有的客户用的是更新指定字段为1,有的客户更新指定字段为‘1’ 脏数据的存在,比如该字段为空字符 ...
- Qt5.3.2_CentOS6.4_x86_调试源码关联【勿删,简洁】
1. Qt5.3.2 --> Tools --> Options... --> 左侧选择"Debugger" --> 然后选择"General&q ...
- JavaScript权威指南--脚本化文档
知识要点 脚本化web页面内容是javascript的核心目标. 第13章和14章解释了每一个web浏览器窗口.标签也和框架由一个window对象所示.每个window对象有一个document对象, ...
- 图片保存到数据库以及C#读取图片
图片保存到数据库,如果是sqlserver就是Image类型,如果保存到Oracle就是blob类型,在c#中相对应的就是byte[]类型,同时只需要对读出的数据强制转换就行(byte[])objec ...
- [.NET开发] C#实现发送手机验证码功能
之前不怎么了解这个,一直以为做起来很复杂. 直到前两天公司要求要做这个功能. 做了之后才发现 这不过就是一个POST请求就能实现的东西.现在给大家分享一下,有不足之处还请多多指教. 废话不多说 直接上 ...
- Vue.js教程--基础(实例 模版语法template computed, watch v-if, v-show v-for, 一个组件的v-for.)
官网:https://cn.vuejs.org/v2/guide/index.html Vue.js 的核心是一个允许采用简洁的模板语法来声明式地将数据渲染进 DOM 的系统. 视频教程:https: ...
- [INS-20802] Oracle Net Configuration Assistant failed,Caught UnknownHostException
在64位Centos上安装64的oracle 11g R2,出现错误: [INS-20802] Oracle Net Configuration Assistant failed 根据提示查看日志文件 ...
- android--------自定义控件ListView实现下拉刷新和上拉加载
开发项目过程中基本都会用到listView的下拉刷新和上滑加载更多,为了方便重写的ListView来实现下拉刷新,同时添加了上拉自动加载更多的功能. Android下拉刷新可以分为两种情况: 1.获取 ...
- Confluence 6 连接一个目录
你可以添加下面类型的目录服务器和目录管理器: Confluence 的内部目录(Configuring the Internal Directory). Microsoft Active Direct ...
- 42 前端HTML
HTML 1. 概念 HTML 超文本标记语言(Hypertext Markup Language, HTML)是一种用于创建网页的标记语言 . 2.标签 Meta标签 <me ...