influx+grafana自定义python采集数据和一些坑的总结
先上网卡数据采集脚本,这个基本上是最大的坑,因为一些数据的类型不正确会导致no datapoint的错误,真是令人抓狂,注意其中几个key的值必须是int或者float类型,如果你不慎写成了string,那就麻烦了,其他的tag是string类型。
另外数据采集时间间隔一般就是10秒,这是潜规则,大家都懂。
官方参考地址:
有图有真相
#! /usr/bin/env python
#-*- coding:utf-8 -*-
import os
import arrow
import time
from time import sleep
from influxdb import InfluxDBClient
client = InfluxDBClient('localhost', 8086, 'root', '', 'telegraf')
while True:
if int(time.time())%10 == 0:
cmd = 'cat /proc/net/dev|grep "ens4"'
rawline = os.popen(cmd).read().strip()
rxbytes = int(rawline.split()[1])
txbytes = int(rawline.split()[9])
rxpks = int(rawline.split()[2])
txpks = int(rawline.split()[10])
now = str(arrow.now()).split('.')[0] + 'Z'
print time.time(), rxbytes,txbytes,rxpks,txpks
json_body = [
{
"measurement": "network",
"tags": {
"host": "gc-u16",
"nio": "ens4"
},
#"time": now,
"fields": {
"rxbytes": rxbytes,
"txbytes": txbytes,
"rxpks": rxpks,
"txpks": txpks
}
}
]
client.write_points(json_body)
sleep(1)运行脚本,查看influxdb数据,至于后台+独立线程这些东西就见仁见智了
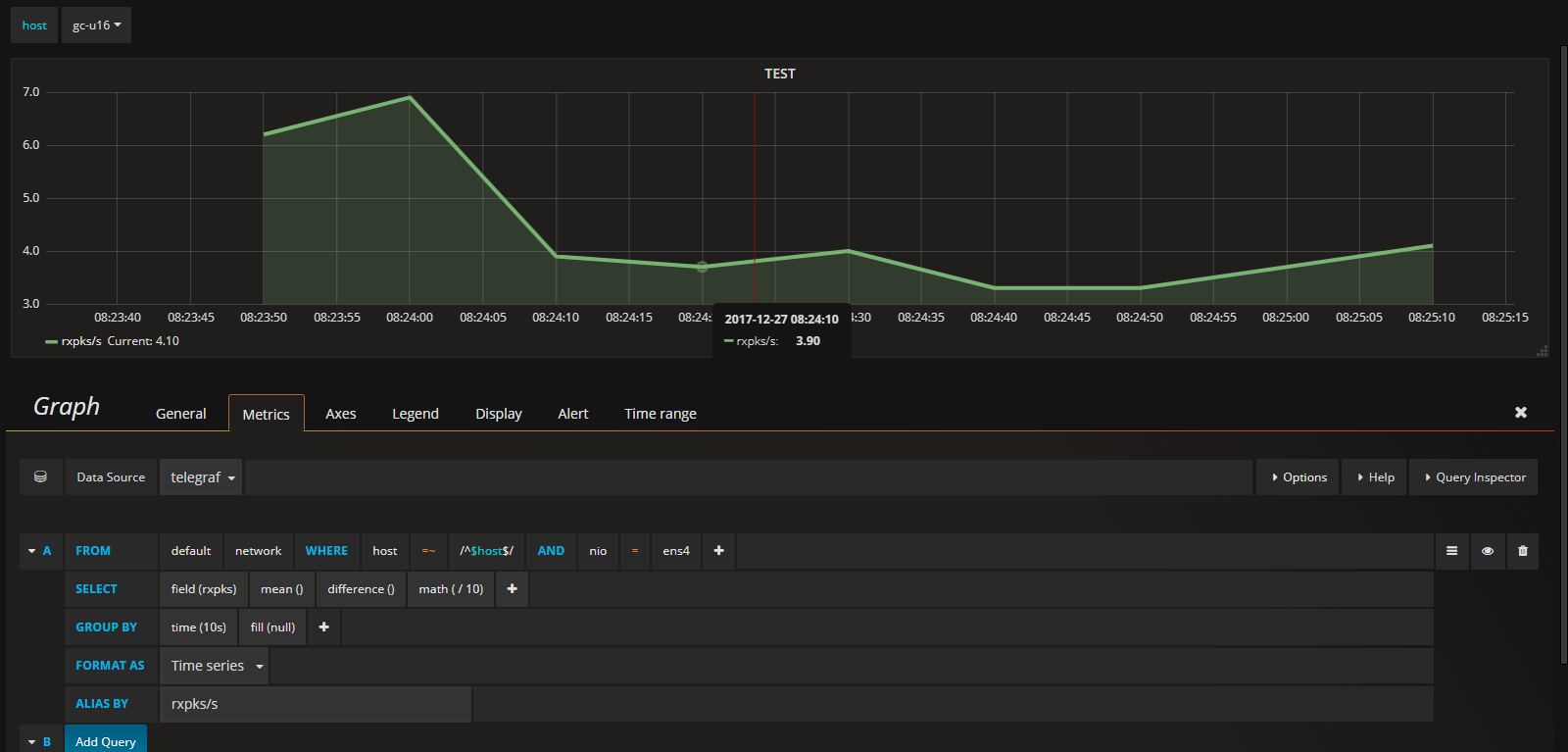
然后配置图形,这个就简单了,只要你数据没写错,基本上grafana都能采集到,这里忽略配置数据源创建dashboard和表格等乱七八糟的,直接上配置的sql图形,大致就是这样吧
influx+grafana自定义python采集数据和一些坑的总结的更多相关文章
- 这么多房子,哪一间是我的小窝?python采集数据并做数据可视化~
前言 嗨喽,大家好呀!这里是小熊猫 环境使用: (https://jq.qq.com/?_wv=1027&k=ONMKhFSZ) Python 3.8 Pycharm 模块使用: (https ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 测试环境 环境搭建 使用前提 使用方法 运行程序 效果展 ...
- 性能测试 基于Python结合InfluxDB及Grafana图表实时采集Linux多主机或Docker容器性能数据
基于Python结合InfluxDB及Grafana图表实时采集Linux多主机性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 3 使用前提 3 使用方法 ...
- python Django教程 之 模型(数据库)、自定义Field、数据表更改、QuerySet API
python Django教程 之 模型(数据库).自定义Field.数据表更改.QuerySet API 一.Django 模型(数据库) Django 模型是与数据库相关的,与数据库相关的代码 ...
- 【转】Python之数据序列化(json、pickle、shelve)
[转]Python之数据序列化(json.pickle.shelve) 本节内容 前言 json模块 pickle模块 shelve模块 总结 一.前言 1. 现实需求 每种编程语言都有各自的数据类型 ...
- Python 保存数据的方法(4种方法)
Python 保存数据的方法: open函数保存 使用with open()新建对象 写入数据(这里使用的是爬取豆瓣读书中一本书的豆瓣短评作为例子) import requests from lxml ...
- 在Caffe中使用 DIGITS(Deep Learning GPU Training System)自定义Python层
注意:包含Python层的网络只支持单个GPU训练!!!!! Caffe 使得我们有了使用Python自定义层的能力,而不是通常的C++/CUDA.这是一个非常有用的特性,但它的文档记录不足,难以正确 ...
- (数据科学学习手札06)Python在数据框操作上的总结(初级篇)
数据框(Dataframe)作为一种十分标准的数据结构,是数据分析中最常用的数据结构,在Python和R中各有对数据框的不同定义和操作. Python 本文涉及Python数据框,为了更好的视觉效果, ...
- 服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana
服务追踪数据使用 RabbitMQ 进行采集 + 数据存储使用 Elasticsearch + 数据展示使用 Kibana https://www.cnblogs.com/xishuai/p/elk- ...
随机推荐
- PYTHON HTML.PARSER库学习小结--转载
前段时间,一朋友让我做个小脚本,抓一下某C2C商城上竞争对手的销售/价格数据,好让他可以实时调整自己的营销策略.自己之前也有过写爬虫抓某宝数据的经历,实现的问题不大,于是就答应了.初步想法是利用pyh ...
- blast 数据库说明
Peptide Sequence Databases蛋白序列的数据库 nrAll non-redundant GenBank CDS translations + RefSeq Proteins + ...
- React Native控件之Picker
1. import React,{Component}from 'react'; import { AppRegistry, StyleSheet, Text, View, Picker, } fro ...
- 转载:Java 内存区域和GC机制
原文链接:http://www.cnblogs.com/hnrainll/archive/2013/11/06/3410042.html 目录 Java垃圾回收概况 Java内存区域 Java对象的访 ...
- Mac OS下安装mvn
Step1: 去官网地址下载 http://maven.apache.org/download.cgi Step2: 解压并且移动到指定到目录下 Step3: 配置环境变量并使之生效 .bash_pr ...
- vector_01
尾部 ==> 添加/删除 快 头部/中间 ==> 添加/删除 慢 A.尾部 添加/移除: void vector::push_back(); void vector::pop_back( ...
- 【Robot Framework 项目实战 01】使用 RequestsLibrary 进行接口测试
写在前面 本文我们一起来学习如何使用Robot Framework 的RequestsLibrary库,涉及POST.GET接口测试,RF用例分层封装设计等内容. 接口 接口测试是我们最常见的测试类型 ...
- 怎么运行cocos2dx 3.x simulator?
1.simulator的好处是: 快速切换分辨率:F5快速重新启动项目: 这对于脚本语言来说都是很方便快捷的. 2.涉及到显示参数的文件有两个: ①lang,这个是菜单的语言文件,如果没有这个文件的话 ...
- 把Java Web工程转换为基于Maven的Web工程
有一个之前的工程,在使用了基于Maven的Web开发后,发现这种方式很便利,于是就想把之前老的传统的J2EE Web Project转为Maven Web Project. 转换的思路如下: 1.新建 ...
- Oracle HRMS APIs
Oracle HRMS APIs..... Here I will be sharing all the Oracle HRMS APIs related articles. 参考地址: Oracle ...