Redis 如何保持和MySQL数据一致【一】
1. MySQL持久化数据,Redis只读数据
redis在启动之后,从数据库加载数据。
读请求:
不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取
写请求:
数据首先都写到数据库,之后更新redis(先写redis再写mysql,如果写入失败事务回滚会造成redis中存在脏数据)
2.MySQL和Redis处理不同的数据类型
MySQL处理实时性数据,例如金融数据、交易数据】
Redis处理实时性要求不高的数据,例如网站最热贴排行榜,好友列表等
在并发不高的情况下,读操作优先读取redis,不存在的话就去访问MySQL,并把读到的数据写回Redis中;写操作的话,直接写MySQL,成功后再写入Redis(可以在MySQL端定义CRUD触发器,在触发CRUD操作后写数据到Redis,也可以在Redis端解析binlog,再做相应的操作)
在并发高的情况下,读操作和上面一样,写操作是异步写,写入Redis后直接返回,然后定期写入MySQL
几个例子:
1.当更新数据时,如更新某商品的库存,当前商品的库存是100,现在要更新为99,先更新数据库更改成99,然后删除缓存,发现删除缓存失败了,这意味着数据库存的是99,而缓存是100,这导致数据库和缓存不一致。
解决方法:
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
2.在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
解决方法:
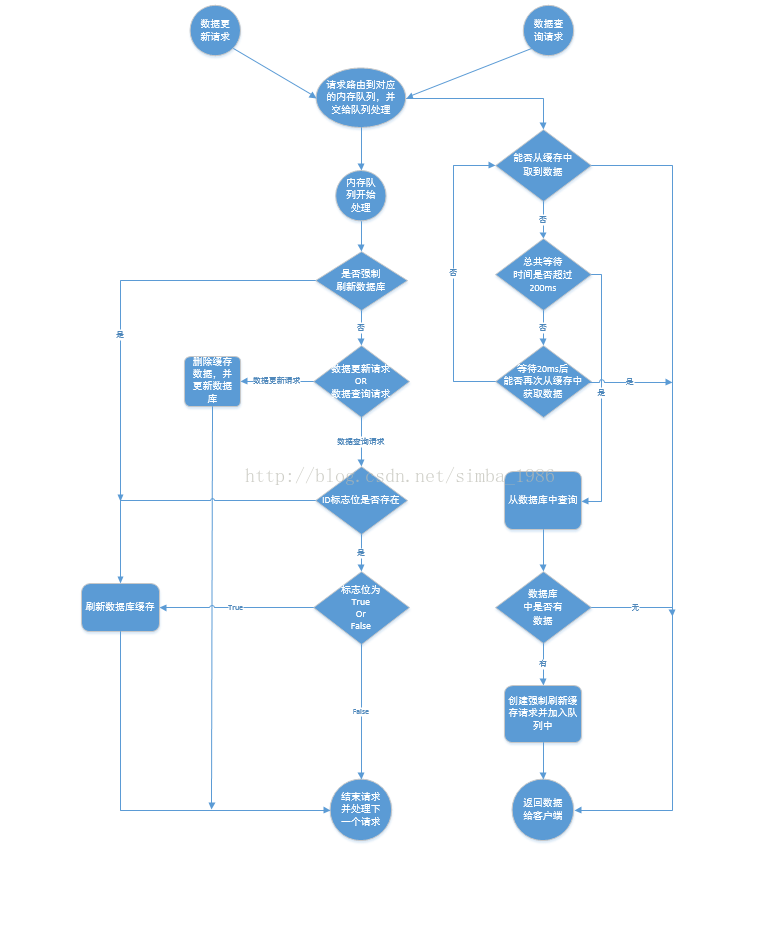
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
在高并发下解决场景二要注意的问题:
(1)读请求时长阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时间内返回,该解决方案最大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。
(2)请求并发量过高
这里还是要做好压力测试,多模拟真实场景,并发量在最高的时候QPS多少,扛不住就要多加机器,还有就是做好读写比例是多少
(3)多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
(4)热点商品的路由问题,导致请求的倾斜
某些商品的读请求特别高,全部打到了相同的机器的相同丢列里了,可能造成某台服务器压力过大,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是很大,但是确实有可能某些服务器的负载会高一些。
摘自:https://blog.csdn.net/Thousa_Ho/article/details/78900563
Redis 如何保持和MySQL数据一致【一】的更多相关文章
- Redis 如何保持和MySQL数据一致【二】
需求起因 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节.所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库. 这个业务场景,主要 ...
- Redis 如何保持和MySQL数据一致
1. MySQL持久化数据,Redis只读数据 redis在启动之后,从数据库加载数据. 读请求: 不要求强一致性的读请求,走redis,要求强一致性的直接从mysql读取 写请求: 数据首先都写到数 ...
- redis的key对应mysql数据表设计
根据用户名来查询用户信息 在关系型数据中,除主键外,还有可能其他列也步骤查询, 如上表中, username 也是极频繁查询的,往往这种列也是加了索引的. 转换到k-v数据中,则也要相应的生成一条按照 ...
- mysql数据向Redis快速导入
Redis协议 *<args><cr><lf> 参数个数 $<len><cr><lf> 第一个参数长度 <arg0> ...
- 快速同步mysql数据到redis中
MYSQL快速同步数据到Redis 举例场景:存储游戏玩家的任务数据,游戏服务器启动时将mysql中玩家的数据同步到redis中. 从MySQL中将数据导入到Redis的Hash结构中.当然,最直接的 ...
- [python]mysql数据缓存到redis中 取出时候编码问题
描述: 一个web服务,原先的业务逻辑是把mysql查询的结果缓存在redis中一个小时,加快请求的响应. 现在有个问题就是根据请求的指定的编码返回对应编码的response. 首先是要修改响应的bo ...
- Redis和mysql数据怎么保持数据一致的?
需求起因 在高并发的业务场景下,数据库大多数情况都是用户并发访问最薄弱的环节.所以,就需要使用redis做一个缓冲操作,让请求先访问到redis,而不是直接访问MySQL等数据库. 这个业务场景, ...
- 转载:mysql数据同步redis
from: http://www.cnblogs.com/zhxilin/archive/2016/09/30/5923671.html 在服务端开发过程中,一般会使用MySQL等关系型数据库作为最终 ...
- Redis和MySQL数据同步及Redis使用场景
1.同步MySQL数据到Redis (1) 在redis数据库设置缓存时间,当该条数据缓存时间过期之后自动释放,去数据库进行重新查询,但这样的话,我们放在缓存中的数据对数据的一致性要求不是很高才能放入 ...
随机推荐
- hdu-4283 You Are the One 区间dp,
题意:n个人排队上台,每个人有一屌丝值D,他的不满意值=D*(k-1)(k为他前面的总人数). 求整个队列不满意值之和的最小值.你只有一个操作,就是把队首的人塞进小黑屋,也就是压入栈中,后面的人就被提 ...
- disk_free_space
$df = disk_free_space('/')/1024/1024/1024; $df_c = disk_free_space("c:"); $df_d = disk_fre ...
- Node.js(daemon),tweak(debug ES)/nodejs forever,supervisor--express
http://www.cnblogs.com/Darren_code/p/node_express.html express -e nodejs-product sudo npm install fo ...
- centos source install
CentOS Kernel Source Install Mar 12th, 2012 | Comments CentOS kernel source install, first off if yo ...
- models语言中filter和all取数据有什么区别
转自:http://www.bubuko.com/infodetail-1882394.html rs=Person.objects.all() all返回的是QuerySet对象,程序并没有真的在数 ...
- 数字货币量化教程——使用itertools实现各种排列组合
在量化数据处理中,经常使用itertools来完成数据的各种排列组合以寻找最优参数 一.数据准备 import itertools items = [1, 2, 3] ab = ['a', 'b'] ...
- 2018/03/29 每日一个Linux命令 之 ping
ping 用于测试两及其网络是否通 主要用于检测网络是否通畅. -- 具体语法 ping [-dfnqrRv][-c<完成次数>][-i<间隔秒数>][-I<网络界面&g ...
- mac chrome 驱动配置
将解压后的chromedriver移动到/usr/local/bin目录下
- 【虫师】【selenium】参数化
# 1 #coding=utf-8 from selenium import webdriver import os,time source = open("F:\\test\\info.t ...
- sql server作业管理查看/进程管理查看命令
一.作业管理 (1) select * from msdb.dbo.sysjobhistory 可以查看作业的历史记录 (2) select * from msdb.dbo.sysjobs 查 ...