InnoDB源码分析--缓冲池(二)
转载请附原文链接:http://www.cnblogs.com/wingsless/p/5578727.html
上一篇中我简单的分析了一下InnoDB缓冲池LRU算法的相关源码,其实说不上是分析,应该是自己的笔记,不过我还是发扬大言不惭的精神写成分析好了。在此之后,我继续阅读了Buf0rea.c文件,因为这里写的就是如何将block读取到内存中的函数。
这个文件里很显眼的有这样一个函数:buf_read_page,这是一个高层的函数,它的作用就是:reads a page asynchronously from a file to the buffer buf_pool if it is not already there。采用异步的方式将文件中的页读入buf_pool。大体上看一眼这个函数,发现它主要搞了以下几个工作:
1 随机预读(buf_read_ahead_random)。随机预读是一个可以提高效率的策略,它的主要思想是:给定的space和offset确定的那页,可以计算出一个范围,如果这个范围内的页(pages)有一部分已经被访问(阈值:BUF_READ_AHEAD_RANDOM_THRESHOLD),那么这个范围内的页(pages)就会被预读。看一下函数内是怎么写的:
//确定一个边界,边界内的页,都要进行条件判断
low = (offset / BUF_READ_AHEAD_RANDOM_AREA)
* BUF_READ_AHEAD_RANDOM_AREA;
high = (offset / BUF_READ_AHEAD_RANDOM_AREA + )
* BUF_READ_AHEAD_RANDOM_AREA;
if (high > fil_space_get_size(space)) { high = fil_space_get_size(space);
} 省略部分...
//对边界内的页进行条件判断
for (i = low; i < high; i++) {
block = buf_page_hash_get(space, i); if ((block)
&& (block->LRU_position > LRU_recent_limit)
&& block->accessed) { recent_blocks++;
}
} mutex_exit(&(buf_pool->mutex)); if (recent_blocks < BUF_READ_AHEAD_RANDOM_THRESHOLD) {
/* Do nothing */ return();
}
省略部分...
//如果之前的判断都通过,则函数可以进行下面的步骤
//边界范围内的每一个页都会被预读:(buf_read_page_low),预读采用异步的方式
for (i = low; i < high; i++) {
/* It is only sensible to do read-ahead in the non-sync aio
mode: hence FALSE as the first parameter */ if (!ibuf_bitmap_page(i)) {
count += buf_read_page_low(
&err, FALSE,
ibuf_mode | OS_AIO_SIMULATED_WAKE_LATER,
space, tablespace_version, i);
if (err == DB_TABLESPACE_DELETED) {
ut_print_timestamp(stderr);
fprintf(stderr,
" InnoDB: Warning: in random"
" readahead trying to access\n"
"InnoDB: tablespace %lu page %lu,\n"
"InnoDB: but the tablespace does not"
" exist or is just being dropped.\n",
(ulong) space, (ulong) i);
}
}
}
满足条件的页就会被预读,注意预读采用异步的方式,同时,(space,offset)指定的页,也会被预读。这里是一个我有点搞不明白的地方,这个页既然被异步预读了,后面还会在同步的读取一次,且听后话。
2 物理读取。预读结束之后,buf_read_page函数就会调度buf_read_page_low函数,进行数据的读取,注意这个函数刚才预读的时候也使用过,但是这次采用同步的方式,注释写的很明白:“ We do the i/o in the synchronous aio mode to save thread”。这个函数还会在给block->frame加x-lock锁,这个操作会在函数调度下一级函数buf_page_init_for_read的时候进行,代码:rw_lock_x_lock_gen(&(block->lock), BUF_IO_READ)。而buf_page_init_for_read函数的主要作用就是从LRU里分配一个buf_block_t*,并对这个buf_block_t*加x-lock锁。我主要看到了这几行:
//分配一个buffer block
block = buf_block_alloc();
//向buffer pool中初始化一个page
buf_page_init(space, offset, block);
//将block插入LRU链表中,只能插入old链表
buf_LRU_add_block(block, TRUE); /* TRUE == to old blocks */
rw_lock_x_lock_gen(&(block->lock), BUF_IO_READ);
注意,buf_read_page_low函数中最后有这样一段:
if (sync) {
/* The i/o is already completed when we arrive from
fil_read */
buf_page_io_complete(block);
}
如果是同步方式,那么就用buf_page_io_complete函数释放所有的x-lock:rw_lock_x_unlock_gen(&(block->lock), BUF_IO_READ);
3 物理读取结束之后,会调度buf_flush_free_margin函数,在需要的情况下,flush掉LRU链表的尾部。
总结一下上面的步骤,发现这是地地道道的物理读取,即从磁盘中将数据读取到内存中。在《MySQL内核--InnoDB存储引擎》一书的12章里还介绍了一种读取方式叫做逻辑读取,现在分析如下。
从书中的描述里看,我觉得这个叫做逻辑读取有点不好理解。个人觉得这个逻辑读取其实就是一个流程:
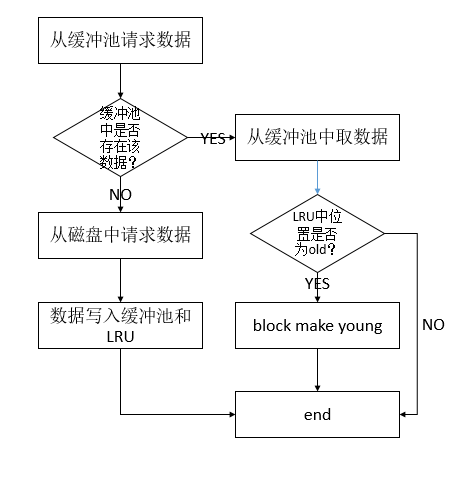
基于我的理解画的,可能有疏漏的地方。这里就需要看这个函数:buf_page_get_gen,它的注释也写得很明白:This is the general function used to get access to a database page。提供了一个访问数据库页的通用方法。
这个函数有个很有意思的地方就是它的入参里有很多的mode,这就给该函数带来了许多种可能的返回。我无心看这些,但是有一个地方却很吸引我,就是一个goto。学C的时候老师说,goto是C语言历史上臭名昭著的一个关键字,大家初学,千万别用。但是又有持不同意见的人认为善用goto能带来意想不到的效果,我相信MySQL的作者们goto用的非常好。
函数中有一个loop标记,也就是说函数是循环着读取block的,直到满足一些条件。首先会从缓冲池里寻找:block = buf_page_hash_get(space, offset),没有的话就会使用这个函数:buf_read_page(space, offset)将block读入,然后goto到开始的地方,将block置为NULL,重新开始,这次就能从缓冲池里找到block了。下面的代码是很多的判断,不过这里很显眼:
mutex_exit(&buf_pool->mutex);
/* Check if this is the first access to the page*/ accessed = block->accessed;
block->accessed = TRUE;
mutex_exit(&block->mutex);
buf_block_make_young(block);
省略部分...
if (!accessed) {
/* In the case of a first access, try to apply linear
read-ahead */
buf_read_ahead_linear(space, offset);
}
这里判断了block是不是第一次被访问,但是很奇怪,这个block立刻就被make young了,这和我以前的认知倒是不太一样了,不过这篇淘宝丁奇的博文(https://yq.aliyun.com/articles/8827)里写到了这一点,可以参考一下,经过我的分析发现,make young也不是那么笨的,它要判断这个block是不是需要被make young(if (buf_block_peek_if_too_old(block)))。如果是第一次被访问,就会触发线性预读函数的调用。
终于说到了线性预读。留着明天写吧。
看代码果然过瘾啊。
InnoDB源码分析--缓冲池(二)的更多相关文章
- InnoDB源码分析--缓冲池(三)
转载请附原文链接:http://www.cnblogs.com/wingsless/p/5582063.html 昨天写到了InnoDB缓冲池的预读:<InnoDB源码分析--缓冲池(二)> ...
- innoDB源码分析--缓冲池
最开始学Oracle的时候,有个概念叫SGA和PGA,是非常重要的概念,其实就是内存中的缓冲池.InnoDB的设计类似于Oracle,也会在内存中开辟一片缓冲池.众所周知,CPU的速度和磁盘的IO速度 ...
- DataTable源码分析(二)
DataTable源码分析(二) ===================== DataTable函数分析 ---------------- DataTable作为整个插件的入口,完成了整个表格的数据初 ...
- 一个普通的 Zepto 源码分析(二) - ajax 模块
一个普通的 Zepto 源码分析(二) - ajax 模块 普通的路人,普通地瞧.分析时使用的是目前最新 1.2.0 版本. Zepto 可以由许多模块组成,默认包含的模块有 zepto 核心模块,以 ...
- Zepto源码分析(二)奇淫技巧总结
Zepto源码分析(一)核心代码分析 Zepto源码分析(二)奇淫技巧总结 目录 * 前言 * 短路操作符 * 参数重载(参数个数重载) * 参数重载(参数类型重载) * CSS操作 * 获取属性值的 ...
- Koa源码分析(二) -- co的实现
Abstract 本系列是关于Koa框架的文章,目前关注版本是Koa v1.主要分为以下几个方面: Koa源码分析(一) -- generator Koa源码分析(二) -- co的实现 Koa源码分 ...
- Unity时钟定时器插件——Vision Timer源码分析之二
Unity时钟定时器插件——Vision Timer源码分析之二 By D.S.Qiu 尊重他人的劳动,支持原创,转载请注明出处:http.dsqiu.iteye.com 前面的已经介绍了vp_T ...
- Tomcat源码分析(二)------ 一次完整请求的里里外外
Tomcat源码分析(二)------ 一次完整请求的里里外外 前几天分析了一下Tomcat的架构和启动过程,今天开始研究它的运转机制.Tomcat最本质就是个能运行JSP/Servlet的Web ...
- spark 源码分析之二十一 -- Task的执行流程
引言 在上两篇文章 spark 源码分析之十九 -- DAG的生成和Stage的划分 和 spark 源码分析之二十 -- Stage的提交 中剖析了Spark的DAG的生成,Stage的划分以及St ...
随机推荐
- Mybatis if test中字符串比较
<if test=" name=='你好' "> <if> 这样会有问题,换成 <if test=' name=="你好" '&g ...
- Scalaz(1)- 基础篇:隐式转换解析策略-Implicit resolution
在正式进入scalaz讨论前我们需要理顺一些基础的scalaz结构组成概念和技巧.scalaz是由即兴多态(ad-hoc polymorphism)类型(typeclass)组成.scalaz typ ...
- node.js如何处理请求的路由
var http = require( 'http' ) var handlePaths = [] /** * 初始化路由配置数组 */ function initRotute() { handleP ...
- GJM:用C#实现网络爬虫(一) [转载]
网络爬虫在信息检索与处理中有很大的作用,是收集网络信息的重要工具. 接下来就介绍一下爬虫的简单实现. 爬虫的工作流程如下 爬虫自指定的URL地址开始下载网络资源,直到该地址和所有子地址的指定资源都下载 ...
- Tomcat如何设置网站的默认首页
在Tomcat安装完成后, 在其安装目录下会有一个config文件夹, 打开其中的server.xml文件, 找到相应的directory字段, 设置默认的文件, 重启服务器即可.
- 用纯CSS创建一个三角形
原理:把上.左.右三条边隐藏掉(颜色设为 transparent) #demo { width:; height:; border-width: 20px; border-style: solid; ...
- 【服务器】CentOS下部署运行NodeJs Web App
NodeJs Web App测试完成后,要怎么部署呢?介绍两个不错的方案 已知以下情景: 我要为 「kenniu」这个项目做配置 它的入口文件在 「/path/to/entry.js」 运行的User ...
- github上比较全的知识
https://github.com/hawx1993/github-FE-project
- Flex布局窥探(一)
一.Flex布局是神马? Flex是Flexible Box的缩写,意为‘弹性布局’,用来为盒模型提供最大的灵活性. 任何容器都能被指定为Flex布局: .box{ display: flex; } ...
- 用JSON.parse和eval出现的问题
json格式非常受欢迎,而解析json的方式通常用JSON.parse()但是eval()方法也可以解析,这两者之间有什么区别呢? JSON.parse()之可以解析json格式的数据,并且会对要解析 ...