Oracle索引梳理系列(二)- Oracle索引种类及B树索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载。转载时,请在文章明显位置注明原文链接。若在未经作者同意的情况下,将本文内容用于商业用途,将保留追究其法律责任的权利。如果有问题,请以邮箱方式联系作者(793113046@qq.com)。
Oracle索引种类
一 Oracle索引类型概述
oracle索引的种类主要有以下几种:
- B树索引:oracle默认的索引类型,内部采用二叉树结构,根据rowid实现访问行的快速定位。
- 反向索引:反转B树索引的索引列的键值字节,尤其是索引列值递增且批量插入数据时,使索引分布均匀。
- 位图索引:通过使用位图,标识被索引的列值,进而管理与数据行的对应关系。主要用于OLAP的系统。
- 表簇索引:使用表簇索引必须要使用表簇(cluster)。
- 函数索引:通过函数将数据列计算的返回值作为索引键值建立的索引结构。
二 B树索引
2.1 B树索引结构图说明
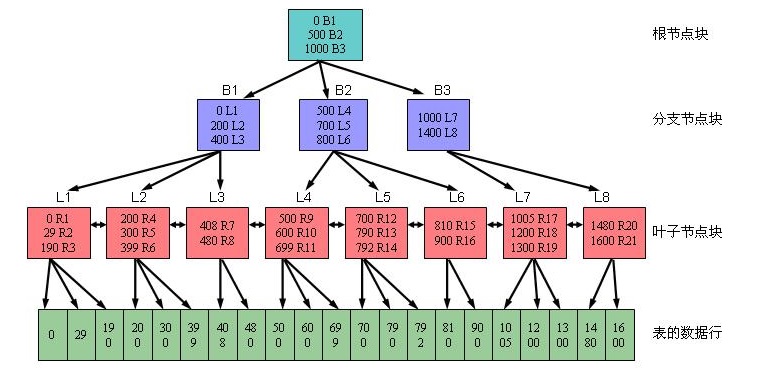
- 该结构图源自于网络,从图中不难看出,B树索引结构主要由三部分组成:根节点、分支节点、叶子节点。
- 对于oracle而言,索引的层级号采用倒序的方式,既对于层级数为N的索引,根节点的层级号为N,其下一层的分支节点为N-1,类推。
- 需要注意的是,oracle会自动为表的主键列创建索引。
- 需要注意的是,oracle不会对包含NULL值的索引列进行索引;但对于组合索引,其中包含NULL值的,这一行会索引。
- 需要注意的是,索引发生的I/O次数与索引树的层数成正比,因此有些情况下,采用“反向索引”(后面介绍),可以有效降低层数,今儿优化索引性能。
2.2 B树索引说明 - 分支节点(包含根节点)
- 对于分支节点块而言,其内部的索引条目采用顺序排列,默认为升序,创建时也可制定为降序。
- 对于分支节点块的索引条目而言,主要两个字段:
- 该分支节点块下面索引块的最小键值。
- 链接的索引块地址,该地址指向下面一个索引块。
- 对于分支节点块的索引条目数量,其大小由数据块大小以及键值长度决定。
2.3 B树索引说明 - 叶子节点
- 对于叶子节点块而言,其内部的索引条目同样采用顺序排列,默认为升序,创建时可制定为降序
- 索引的键值。对于单一列索引,其键值为一个列值;对于组合列索引,其键值为多个列值的组合。
- 键值的rowid信息。该rowid信息记录表中的相应数据的物理地址。
- 对于叶子节点块间的关系,采用双向链表,包含了指向上一个叶子节点以及下一个叶子节点的指针,方便一定范围内索引。
对于叶子节点块的索引条目而言,同样主要包含两个字段:
2.4 B树索引的实际运用情况
- 检索的数据列是索引指定列时,只需访问索引块即可完成数据的访问
--查看表中的索引信息
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNO--查看索引的类型,normal说明为正常B树索引
Yumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMAL--打开会话追踪
Yumiko@sunny >set autotrace traceonly --查看执行结果
Yumiko@sunny >select empno from emp where empno=7900; Execution Plan
----------------------------------------------------------
Plan hash value: 56244932 ----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4 | 0 (0)| 00:00:01 |
|* 1 | INDEX UNIQUE SCAN| PK_EMP | 1 | 4 | 0 (0)| 00:00:01 |
---------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 1 - access("EMPNO"=7900) Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
1 consistent gets
0 physical reads
0 redo size
523 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed通过上面的执行计划可以看到,检索数据仅仅扫描索引块便返回数据,并未进一步通过rowid进行表的扫描(
TABLEACCESSBYINDEXROWID)
- 检索的数据列中,含有未涵盖的索引指定列的时候,将会访问索引块以及数据块进行数据的检索
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNOYumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMALYumiko@sunny >set autotrace traceonly Yumiko@sunny >select * from emp where empno=7900; Execution Plan
----------------------------------------------------------
Plan hash value: 2949544139 --------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 38 | 1 (0)| 00:00:01 |
| 1 | TABLE ACCESS BY INDEX ROWID| EMP | 1 | 38 | 1 (0)| 00:00:01 |
|* 2 | INDEX UNIQUE SCAN | PK_EMP | 1 | | 0 (0)| 00:00:01 |
-------------------------------------------------------------------------------------- Predicate Information (identified by operation id):
--------------------------------------------------- 2 - access("EMPNO"=7900) Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
889 bytes sent via SQL*Net to client
512 bytes received via SQL*Net from client
1 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed通过上面的执行计划可以看到,检索数据在扫描索引块后,进一步通过rowid进行表数据的扫描(
TABLEACCESSBYINDEXROWID)
- 检索数据时,当直接访问表数据的成本(访问数据块)优于使用索引访问表数据的成本(访问索引块+数据块)时,将不使用索引扫描。如全表扫描。
Yumiko@sunny >select index_name,table_name,column_name from user_ind_columns where table_name = 'EMP'; INDEX_NAME TABLE_NAME COLUMN_NAME
-------------------- -------------------- --------------------
PK_EMP EMP EMPNOYumiko@sunny >select INDEX_NAME,TABLE_NAME,index_TYPE from user_indexes where index_name ='PK_EMP';
INDEX_NAME TABLE_NAME INDEX_TYPE
----------------------------------------------------
PK_EMP EMP NORMALYumiko@sunny >set autotrace traceonly Yumiko@sunny >select * from emp;
14 rows selected. Execution Plan
----------------------------------------------------------
Plan hash value: 3956160932 --------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 14 | 532 | 3 (0)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 14 | 532 | 3 (0)| 00:00:01 |
-------------------------------------------------------------------------- Statistics
----------------------------------------------------------
1 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
1630 bytes sent via SQL*Net to client
523 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
14 rows processed通过上面的执行计划可以看到,当检索全表时,并未进行索引扫描,而是采用全表扫描的方式(TABLE ACCESS FULL),访问数据块,进而取得结果。
Oracle索引梳理系列(二)- Oracle索引种类及B树索引的更多相关文章
- [独孤九剑]Oracle知识点梳理(二)数据库的连接
本系列链接导航: [独孤九剑]Oracle知识点梳理(一)表空间.用户 [独孤九剑]Oracle知识点梳理(二)数据库的连接 [独孤九剑]Oracle知识点梳理(三)导入.导出 [独孤九剑]Oracl ...
- Oracle索引梳理系列(五)- Oracle索引种类之表簇索引(cluster index)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(四)- Oracle索引种类之位图索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(九)- 浅谈聚簇因子对索引使用的影响及优化方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(八)- 索引扫描类型及分析(高效索引必备知识)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(十)- 直方图使用技巧及analyze table操作对直方图统计的影响(谨慎使用)
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(七)- Oracle唯一索引、普通索引及约束的关系
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(一)- Oracle访问数据的方法
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
- Oracle索引梳理系列(六)- Oracle索引种类之函数索引
版权声明:本文发布于http://www.cnblogs.com/yumiko/,版权由Yumiko_sunny所有,欢迎转载.转载时,请在文章明显位置注明原文链接.若在未经作者同意的情况下,将本文内 ...
随机推荐
- Firemonkey 载入 Style 皮肤 (*.fsf 二进制文件) 速度测试
说明:Firemonkey 可以换肤是一大亮点,但使用它必须要付出一点代价,就是需要一点载入的时间,下面以 *.fsf 二进制文件来做载入测试,有兴趣可以参考看看. 开发:XE8 for iOS 皮肤 ...
- 简单在android adb root方法
在有些android手机上使用adb root希望获取root权限时出现如下提示信息:adbd cannot run as root in production builds.此时提升root权限的方 ...
- vim退出后终端保留 退出前的内容
export TERM=linux 或者 具体选项 可以看看secrecrt的选项
- java 数据库连接池
1. About java利用jdbc直接连接数据库,经常取得连接,用完释放,很浪费系统资源 2. Code Java代码 package com.cdv.mam.db; import java.sq ...
- Apache运行python cgi程序
Apache运行python cgi程序 环境 win10 x64 专业版 Apache2.4 python 2.7 Apache安装和配置 Apache服务器的安装请自行搜索.在Apache2.4中 ...
- Alfresco 4 项目介绍
body{ font: 16px/1.5em 微软雅黑,arial,verdana,helvetica,sans-serif; } Alfresco 是一个开源的企业内容管理系统(ECM) ...
- Python实现装饰模式的一段代码
# 实现装饰模式的一段代码 import functools def log(func): @functools.wraps(func) def wrapper(*args,**kw): print( ...
- Nuget很慢,我们该怎么办
在VS中给项目添加程序已经采用NuGet 十分方便 不过很多时候速度很慢,一直显示“正在检索信息” 其实直接使用程序包管理控制台,速度就会好很多 如果命令不太会写,安装包名不是确认,可以先登录 htt ...
- 删除 QQ 最新版右键菜单 通过QQ发送文件到手机
64位:打开命令行执行: regsvr32 /u "C:\Program Files (x86)\Tencent\QQ\Bin\QQShellExt64.dll" 32位:打开命令 ...
- [.NET] 使用Json.NET提供依赖注入功能(Dependence Injection)
[.NET] 使用Json.NET提供依赖注入功能(Dependence Injection) 前言 在一些小型项目的开发情景里,系统不需要大型DI Framework所提供的:单一对象生成.生命周期 ...